| I Protocolli TCP/IP |
|
Il protocollo TCP Il protocollo IP Innanzi tutto spieghiamo il nome. TCP sta per Transfer Control Protocol, IP sta per Internet Protocol. In realt� il protocollo TCP/IP � una famiglia di protocolli, ognuno con una sua funzione particolare, TCP ed IP sono due protocolli importanti di questa famiglia.
Tutti i protocolli di livello superiore, sono specializzati nel compiere qualche servizio particolare. Ad esempio FTP, File Transfer Protocol, permette il trasferimento dei file, TELNET, network terminal protocol, permette di parlare con un computer remoto come se vi foste davanti, SMTP, Simple Mail Trasfer Protocol, serve a trasferire la posta elettronica, SNMP, Simple Network Management Protocol, per gestire e monitorare lo stato della rete. Questi non sono tutti, sono solo i pi� importanti. Per la loro diversit�, ritengo che descriverli uno per uno in dettaglio, andrebbe al di l� dello scopo di questo documento. I protocolli di livello superiore basano il loro lavoro su un'assunzione: che i protocolli di basso livello siano in grado di comunicare in modo affidabile.
Vediamo questa struttura al lavoro facendo un semplice esempio, immaginate di voler inviare un messaggio su una rete TCP/IP (Internet � una di queste). Ci� che il protocollo di posta SMTP produce, viene passato in basso al TCP. Innanzi tutto diciamo che TCP fornisce un servizio byte-stream. Questo termine indica che i dati da e per i livelli superiori vengono presentati e ricevuti come un unico flusso di byte, e non come pacchetti. Questo significa che � TCP, e non i protocolli superiori (e quindi le applicazioni), a doversi preoccupare di preparare i pacchetti, con l'evidente vantaggio di avere una chiara la distinzione dei ruoli: SMTP (o qualsiasi altra applicazione di alto livello) pensa a preparare il messaggio di posta, TCP pensa a come deve inviarlo. Un pacchetto TCP � detto segmento. Essenzialmente i compiti di TCP sono:
Ad ogni segmento, TCP aggiunge il suo header. Se non sapete cos'� un header dovreste davvero leggere la pagina Il viaggio dei dati. Nell'header sono contenuti i seguenti campi; quelli in rosso sono i pi� importanti
Qui apro una piccola ma importante parentesi per far capire quanto sia utile il concetto di porta nelle comunicazioni TCP. Normalmente, quando stabilite una comunicazione generica, TCP genera un numero di porta casuale. Se per� volete iniziare una connessione con un protocollo di alto livello (cio� il 99% dei casi), come per esempio il protocollo SMTP, perch� volete mandare un messaggio di posta all'altro computer, dovete prima di tutto specificare che volete una connessione attraverso la porta n.25 (o lo far� per voi il vostro lettore di posta). Solo dietro a questo numero di porta troverete SMTP in ascolto. Ci sono diversi "numeri magici" standard (detti "well known services", servizi ben noti), ad esempio 21 per FTP, 23 per Telnet, 53 per il servizio DNS, 80 per il Web Server. Potete trovare una lista dei principali servizi noti in C:\Windows\Services, o in /etc/services in Linux.
E finalmente
Il meccanismo delle finestre scorrevoli Cosi come l'abbiamo descritto potremmo pensare che il lavoro del TCP consista semplicemente nel mandare un segmento, aspettare l'acknowledgement per quel pacchetto, mandare un altro pacchetto. Se l'Ack non arriva entro un certo intervallo di tempo ritrasmettere il primo segmento. Anche se funziona, questo modo di procedere � estremamente inefficiente poich� sfrutta solo una piccola parte della larghezza di banda disponibile. Un sistema molto pi� efficiente ed ugualmente affidabile, � il meccanismo a finestre. Il funzionamento � il seguente.
Consideriamo ora qualche caso particolare. Se il pacchetto 2 non arrivasse a destinazione, la finestra non verrebbe spostata oltre il pacchetto 1. Il destinatario manderebbe gli Ack dei pacchetti 3, 4, 5... ma tutti uguali, cio� settati al valore 1, dato che � il questo l'ultimo pacchetto valido, ricevuto nell'ordine di consegna. Ad un certo punto il timer per 2 scade e il pacchetto viene ritrasmesso. A questo punto per� sorge una domanda: dobbiamo ritrasmettere anche 3, 4, 5... ? Purtroppo non possiamo saperlo. Se mandiamo solo 2, ma anche 3, 4, 5... sono andati persi dovremo aspettare che scadano i timer di tutti questi altri segmenti. Alternativamente possiamo rimandare tutta la finestra. E' comunque chiaro che nessuna soluzione � priva di inefficienze, perch� l'informazione del campo Ack non � sufficientemente espressiva: non dice nulla del frame ricevuto, dice solo qual'� l'ultimo frame valido ricevuto nell'ordine di consegna. Altra caso particolare: il pacchetto 2 viene ricevuto correttamente, ma � l'Ack che viene perso. Semplicemente, il mittente ricever� prima o poi un Ack con valore 3, questo indica che tutti i pacchetti fino al terzo sono arrivati a destinazione, quindi anche il secondo. Dopo l'Ack 3 il mittente pu� spostare la finestra in avanti di 2 passi in una volta. La finestra ora coprir� i pacchetti da 4 a n+3. Nella realt�, per identificare i segmenti si usa il Sequence number non il numero di pacchetto (vedi la def. di Sequence number, nell'header TCP). Inoltre l'ampiezza della finestra � variabile da parte del ricevente durante la connessione grazie al campo Window. Stabilire una connessione TCP: l'handshake a tre vie Quando due computer utilizzano TCP devono innanzitutto creare una sessione. La procedura attraverso la quale la sessione viene stabilita si chiama "three way handshacking", o handshacking a tre vie. Se il computer client PC1 vuole connettersi al computer server PC2, succede questo: 1 - PC1 manda a PC2 un segmento TCP attivando il flag SYN. 2 - PC2 risponde a PC1 con i flag SYN e ACK attivi. 3 - PC1 risponde a sua volta con il flag ACK. Al primo passo, PC1 attiva nel primo segmento il flag SYN per indicare a PC2 che il campo Sequence number � valido e che quindi deve essere letto. Il valore settato da PC1 in quel campo � detto Sequence number iniziale, o ISN (Initial Sequence Number). PC2 risponde attivando il flag SYN ed indicando un proprio ISN, inoltre attiva l'ACK indicando l'ISN+1 di PC1. Infine PC1 attiva l'ACK indicando l'ISN+1 di PC2. A questo punto la comunicazione � stabilita e PC1 pu� iniziare ad inviare gli altri segmenti. Ad esempio: n.___mitt.___dest._____SYN Flag___ACK Flag_____Seq. n.__________Ack. n. 1____PC1____PC2_____Si_________No_________2481573249_____1875913495
Un problema di questa tecnica � la vulnerabilit� ad un famoso tipo di DoS (Denial of Service): il SYN-Flooding. In sostanza il client (PC1) richiede decine e decine di connessioni al server vittima (PC2) inondandolo di pacchetti SYN (inondare = to flood). PC2 risponde con tanti SYN-ACK, a cui per� PC1 volutamente non risponde (in teoria dovrebbe completare gli handshake con un ACK per ogni connessione). PC2 dopo un p� smette di aspettare, ma quando i SYN ricevuti sono troppi, rimane pressoch� paralizzato: dato che esiste un limite massimo al numero di connessioni che si possono stabilire su PC2, un eventuale utente PC3 che si collega a PC2 non verrebbe accettato perch� tutti i canali disponibili sono impegnati (ad aspettare ACK che non arrivano). Chiudere una connessione TCP: il saluto a quattro vie Quando si vuole terminare una connessione, si usa una procedura di terminazione a quattro vie. Un computer manda all'altro un segmento con il flag FIN attivo. Il flag FIN chiude la connessione in una sola direzione. All'altro capo verr� spedito tutto ci� che deve ancora essere spedito, dopodich� anche questo invier� un segmento con il flag FIN. Ora che la comunicazione � chiusa in entrambi i sensi, la sessione pu� considerarsi terminata.. Ad esempio: n.___mitt.____dest._____FIN Flag___ACK Flag____Seq. n.__________Ack. n. 1____PC1_____PC2_____Si_________Si________408549508______2481575301 Gli stati di una connessione TCP Una sessione TCP pu� essere in diversi stati. Potete visualizzare lo stato di tutte le
connessioni in corso sul vostro computer con il comando: Gli stati possibili sono i seguenti
Il controllo delle congestioni di TCP Per evitare congestioni indesiderate sulla rete, TCP dispone di alcuni algoritmi di controllo. Slow start (partenza lenta): quando due computer iniziano a comunicare, questo algoritmo impedisce al mittente di partire subito con una finestra di massima ampiezza (suggerita nel campo window del ricevente, detto anche "advertised window"). Questo meccanismo � molto utile quando la rete che unisce due computer non � una LAN diretta, ma una serie di collegamenti lenti (router e collegamenti WAN). Quando si stabilisce la comunicazione, abbiamo una finestra nel TCP del mittente detta congestion window, cio� finestra di congestione. All'inizio � fatta di un solo segmento, poi cresce esponenzialmente (2, 4, 8, 16...) mano a mano che arrivano gli ACK dal computer ricevente, finch� non si raggiunge il valore del campo window del ricevente. Spesso per�, prima di raggiungere il valore indicato dall'advertised window, si arriva ad punto in cui alcuni pacchetti iniziano ad essere scartati dai collegamenti lenti intermedi. Questo indica che � opportuno fermare la crescita della finestra di congestione. Attenzione a non confondere la congestion window con l'advertised window, quest'ultima � usato solo dal ricevente per indicare quanti segmenti per finestra esso � in grado di accettare nel buffer di ricezione, mentre la congestion window � gestita dal mittente in base al numero di ACK giunti indietro. Congestion Avoidance (evitare la congestione): Congestion Avoidance e Slow Start sono due algoritmi mutualmente esclusivi, cio� non possono mai avvenire contemporaneamente, tuttavia esiste un forte legame tra di loro. Senza scendere troppo nel tecnico, quando avviene una congestione e vengono persi segmenti durante lo Slow Start, viene salvata in una speciale variabile "ssthresh" (che sta per "slow start threshold") la met� del valore della congestion window per cui abbiamo perso segmenti. La finestra viene poi riportata ad uno, dopodich�, quando il valore della congestion window ricresce diventando uguale a ssthresh, la crescita della finestra diventa lineare e non pi� esponenziale. Quindi, se durante una slow start abbiamo una congestione per una congestion window pari a 32 byte, salviamo in ssthresh il valore 16, rimettiamo la congestion buffer a 1, poi rifacciamo una nuova slow start fino a 16 (crescita esponenziale: 1, 2, 4, 8, 16) dopodich� l'algoritmo di Congestion Avoidance interviene sulla velocit� della crescita della congestion window (crescita lineare: 17, 18, 19, 20 ...). Fast Retrasmit (ritrasmissione veloce): come dicevamo
nel paragrafo delle finestre scorrevoli, quando un pacchetto viene perso, gli ACK dei
segmenti successivi arrivati a destinazione riportano come Acknowledgement number il
valore del segmento mancante nell'ordine di consegna. In condizioni normali dovremmo
aspettare lo scadere del timer per il segmento andato perduto prima di poterlo
ritrasmettere. Questo perch� forse il segmento incriminato non � veramente andato
perduto, ma � semplicemente molto lento. L'algoritmo di Fast Retrasmit permette di
scavalcare il timer del pacchetto sospetto quando sono gi� arrivati TRE ACK riportanti lo
stesso valore nell'Acknowledgement number (sintomo che quel pacchetto, pi� che essere
lento, ha probabilmente gi� preso il volo!). Fast Recovery (recupero veloce): per migliorare l'efficienza del Fast Retrasmit, quando ritrasmettiamo un segmento che probabilmente � andato perduto, Fast Recovery fa in modo che il valore della congestion window non venga ridotto proprio del tutto, e che non venga effettuata una Slow Start, bens� una Congestion Avoidance. Il valore della congestion window infatti non viene riportato a 1, ma a sshtresh + 3, dove ssthresh � ancora settato alla met� della congestion window per cui � avvenuta la congestione, e 3 � il numero di ACK duplicati, questo per aumentare la c.window del numero di segmenti che sono nel buffer di ricezione del destinatario, inoltre per ogni ulteriore ACK uguale incrementa ancora la congestion window di uno, questo per aumentare la c.window del numero di segmenti partiti. Se permesso dal nuovo valore della c.window, viene trasmesso un nuovo pacchetto. Quando arriva il successivo ACK relativo a nuovi dati, setta la c.window a ssthresh (la met�). Ed eccoci in Congestion Avoidance. Esiste anche un fratello minore del TCP, e si chiama UDP, User Datagram Protocol. E' usato in tutti quei casi in cui non � necessaria tutta la potenza di TCP, ad esempio quando dobbiamo inviare una richiesta che sta tutta in un solo datagramma. Infatti ogni datagramma UDP viene mandato in un singolo datagramma IP. In sostanza l'unica cosa che un datagramma UDP aggiunge al protocollo IP � la capacit� di usare le porte. L'esempio classico � quando bisogna contattare un server DNS. Un server DNS, Domain Name Service, svolge un ruolo molto importante, specialmente in Internet: traduce indirizzi umani (www.xyz.com) in indirizzi IP (194.37.205.123). Una richiesta del genere � molto corta, non abbiamo bisogno di usare il TCP. L'UDP non si divide in datagrammi e non tiene conto di ci� che viene mandato o di ci� che non � arrivato. Dopo tutto, se qualcosa va storto e non si riceve risposta, basta reinviare lo stesso pacchetto UDP. In gergo tecnico, si dice che TCP fornisce un servizio connection-oriented, mentre UDP � un protocollo connectionless (senza connessione). L'header UDP � composto dai campi: porta sorgente/porta destinataria, equivalenti alle porte dell'header TCP, un campo Message Lenght che indica la lunghezza del datagramma incluso l'header, un campo di checksum di 16 bit ed infine il campo dati. Questo protocollo � abbastanza particolare perch� si trova sullo stesso layer di IP (diversamente da TCP e UDP), ma usa comunque IP per spedire i suoi dati. ICMP non aggiunge garanzie a IP, quindi � possibile che i datagrammi ICMP non arrivino a destinazione o che arrivino corrotti (esattamente come per IP). Il compito di ICMP � quello di inviare messaggi di servizio e messaggi di errore. Un datagramma ICMP � composto dai campi: type (8 bit), che indica il tipo di messaggio, code (8 bit), un codice di errore che dipende dal tipo di messaggio, checksum (16 bit) per sapere se ci sono errori nel datagramma, data (variabile), che contiene informazioni sul messaggio e di solito include parte del datagramma IP che ha generato l'errore. I principali codici sono: 0 - Echo Reply: in risposta all'ICMP n.8 3 - Destination Unreachable: viene generato da un router intermedio quando questo non � in grado di trovare il computer desiderato, oppure viene generato dal computer destinatario se si richiede un servizio (protocollo o porta) che non � attivo. 4 - Source quench: nelle congestioni, viene generato da un router intermedio quando questo ha esaurito lo spazio dove accodare i messaggi in arrivo, oppure viene generato dal computer destinatario se i datagrammi stanno arrivando troppo velocemente. 5 - Redirect: se viene generato da un router intermedio conterr� un indirizzo IP relativo ad un router che andrebbe contattato al posto di questo. 8 - Echo: usato per controllare se un computer � attivo. E' il messaggio che genera il comando ping. 9 - Router Advertisement: Con questo messaggio ICMP, i router periodicamente segnalano la loro presenza sulle reti a cui sono collegati. 10 - Router solicitation: Usato per forzare i router in ascolto ad identificarsi per non dover attendere i Router Advertisement periodici. 11 - Time exceeded: viene generato da un router intermedio quando il campo Time To Live del datagramma � zero. Se generato dal computer destinatario indica che � scaduto il timer che controlla il riassemblamento di un datagramma, il datagramma sar� scartato. 12 - Parameter problem: indica che � stato incontrato un problema durante l'analisi dei paramentri dell'header IP. 13 - Time Stamp request: usato per misurare le prestazioni e per il debugging ma mai per sincronizzare orologi. Il mittente salva in un campo dell'ICMP n.13 il suo time stamp. Il ricevente prepara un ICMP 14 settando altri due campi: il time stamp di ricezione e di trasmissione. 14 - Time Stamp reply: in risposta all'ICMP n.13 17 - Address mask request: Una richiesta broadcast che serve per scoprire la maschera subnet usata dalle macchine in rete. Usato nelle richieste Reverse-ARP, un particolare tipo di ARP usato dalle macchine che non possiedono dischi e non possono memorizzare i dati della rete tra uno spegnimento e la riaccensione. Tutti i riceventi del broadcast ICMP 17 rispondono preparando un ICMP 18 con i dati della sottorete. 18 - Address mask reply: in risposta all'ICMP n.17 IP � un protocollo un p� particolare: non garantisce che i suoi pacchetti, detti datagrammi IP, arrivino a destinazione, che siano privi di errori, o che essi arrivino nell'ordine corretto. Questo lavoro viene lasciato ai protocolli superiori come TCP. Per questo motivo IP � un protocollo abbastanza semplice. L'header di IP si aggiunge a sua volta all'header di TCP visto in precedenza. Contiene i seguenti campi; quelli in rosso sono i pi� importanti
E alla fine
La frammentazione dei datagrammi IP Un datagramma IP, quando viene passato al livello fisico, viene incapsulato in un header Ethernet per formare un frame fisico. Il problema � che le dimensioni massime di questo frame sono limitate. Il valore di questo limite � chiamato MTU, maximum transfer unit (unit� massima di trasferimento). Cosa succede se il nostro datagramma IP � troppo grande per stare in una trama lunga al massimo MTU byte? La risposta a questo problema � la tecnica della frammentazione. Quello che succede � che il datagramma IP viene spezzettato in tanti frammenti abbastanza piccoli da entrare nel frame della rete. Ogni frammento possiede un proprio header molto simile all'header IP del datagramma originale, ma con i campi Identification, Flags, Fragment Offset settati opportunamente (per le loro funzioni vedere il paragrafo precedente). Innanzi tutto il flag DF non deve essere settato, altrimenti il datagramma non viene frammentato ma semplicemente scartato. Il flag MF � pari a uno in tutti i frammenti tranne l'ultimo. Il campo offset viene riempito con il valore opportuno per ogni frammento. Inoltre viene ricalcolato il contenuto di tutti quei campi dell'header IP contenenti valori variabili in funzione della lunghezza (checksum compreso). Ora che i frammenti sono diventati nuovi datagrammi IP vengono inoltrati normalmente. Sul computer ricevente viene riassemblato il datagramma IP originale facendo uso di questi campi. La frammentazione � piuttosto fragile: la perdita di un solo frammento comporta la perdita dell'intero datagramma. In generale avere un frame molto grande permette di avere una maggiore efficienza di trasmissione (anche se nei collegamenti soggetti a problemi di lentezza e corruzione dei pacchetti, avere un MTU grande sar� solo fonte di guai, dato che ogni pacchetto perso contiene molti dati). Normalmente si cerca di evitare di dover ricorrere alla frammentazione. La lunghezza finale del datagramma dipende sia dallo spazio occupato dagli header TCP e IP, che dalla lunghezza del segmento creato da TCP. Per evitare la frammentazione bisogna tenere conto di questi valori confrontandoli con il valore di MTU minimo tra quello delle due macchine. Anche cos� per� non possiamo avere la garanzia che non avverr� una frammentazione, perch� � sempre possibile che alcune reti intermedie abbiano limiti MTU inferiori. E in alcuni casi avverr� anche pi� di una frammentazione. Finito? Quasi... , ci siamo dimenticati un piccolo (?) particolare; stiamo usando una rete Ethernet, quindi dovremo aggiungere anche l'header di Ethernet. Lo trovate descritto per bene nella pagina Analisi delle trame Ethernet. Se non avete voglia di leggerlo vi dico brevemente che nell'header vengono aggiunti l'indirizzo Ethernet del mittente e del destinatario; fate attenzione: in Ethernettiano questo non � un indirizzo IP a 32 bit, ma quello della scheda di rete a 48 bit. Prima di proseguire � bene vedere cosa sono questi due indirizzi. Indirizzi IP - Indirizzi Ethernet Un indirizzo IP, 32 bit, viene indicato come 4 numeri decimali, ognuno esprime 8 bit (8bit x 4n=32bit), es. 192.168.150.10. Essendo solo 8 i bit per ogni numero, i valori andranno da 0 a 255. Un indirizzo IP a 32 bit pu� essere visto come una coppia di due numeri: il numero
di rete e il numero di host o nodo. Il numero di bit usato per il numero di
rete dipende dalla classe di indirizzo. Esistono cinque classi di indirizzi IP: Il numero di rete � assegnato da un ente centrale, l'InterNIC, il numero di host � invece deciso dal possessore di quel numero di rete. Quando il numero di host � fatto solo da '0', l'indirizzo esprime l'indirizzo di rete. Quando � fatto di soli '1', indica un broadcast a tutti i nodi della rete. Dato che la suddivisione per classi � piuttosto grezza, � stato creato il concetto di subnet, o sottorete, che permette di sottrarre qualche bit del numero dell'host in favore di una maggiore flessibilit� di configurazione (ad esempio per separare il traffico in rete tramite un router), invisibile fuori dalla rete. In questo modo l'indirizzo � composto da: un numero di rete, un numero di subnet, un numero di host. Se facciamo un AND bit a bit tra un indirizzo IP e una subnet mask quello che otteniamo
� il numero di rete comprensivo del numero di subnet. I valori di default per le prime
tre classi sono: Usando queste maschere standard con un indirizzo IP, riotteniamo semplicemente il
numero di rete. Se per� volessimo fare tre sottoreti, dato un numero di rete di Classe C,
possiamo "rubare" tre bit al quarto ottetto (l'inizio del numero di host),
bastano 3 bit perch� con 111 abbiamo il numero 7(>5). Quando facciamo questo otteniamo
una Subnet mask di In realt� le subnet 1=000 e 8=111 � meglio non usarle perch� i numeri fatti di soli 0 o soli 1 hanno le funzioni particolari di cui parlavamo prima. N.B. : quando assegnate gli indirizzi IP alle vostre macchine, � buona norma non assegnare mai valori gi� usati in Internet, per questo sono stati definiti indirizzi "sicuri": 10.0.0.0 (numero di rete=primi 8 bit), 172.16.0.0 (numero di rete=primi 20 bit), 192.168.0.0 (numero di rete=primi 16 bit), se non avete particolari esigenze io vi consiglio quest'ultimo. Evitate come al solito i valori 0 e 255. Un'altra classe di indirizzi riservata � 127.0.0.0 (numero di rete=primi 8 bit), che identifica il localhost, ossia il proprio computer. In generale il mio consiglio � di assegnare alle macchine della vostra LAN gli indirizzi 192.168.x.y dove x rappresenta il numero di sottorete, e y il numero per il nodo, e come subnet 255.255.255.0. Tra parentesi, una macchina pu� essere collegata a pi� di una rete, avr� quindi due o pi� indirizzi IP, uno per ogni rete. Tale macchina viene detta multi-homed e pu� svolgere le funzione di un router (un altro nome usato � gateway, tuttavia questa parola ha anche altre definizioni e pu� generare confusione). Un indirizzo Ethernet, 48 bit, viene invece indicato con una notazione differente: 6 numeri esadecimali, ma ognuno di essi continua ad esprime ancora 8 bit(8bit x 6n=48bit), es. 20-53-52-b8-1f-00. I valori vanno da 00 a ff (che per l'appunto sono poi equivalenti in decimale a 0 e 255, cambia solo il modo di scriverli). Anche qui i numeri 0 e ff non vanno usati, ma di questo non vi dovete preoccupare. Infatti gli indirizzi Ethernet sono gi� scritti nelle schede di rete quando vengono fabbricate. Essi devono seguire le disposizioni della IEEE in materia, secondo le quali non devono esistere due schede di rete con lo stesso indirizzo. Ora la domanda sorge spontanea: cosa unisce l'indirizzo IP di una macchina con l'indirizzo fisico della scheda di rete di quella macchina? Nulla! E' per questo che hanno inventato un altro protocollo molto importante: ARP, Address Resolution Protocol. Quando due computer su una stessa rete Ethernet vogliono comunicare, essi devono prima conoscere l'indirizzo fisico. Ogni volta che usiamo TCP/IP su Ethernet e vogliamo comunicare con un sistema di cui conosciamo solo l'indirizzo IP, viene spedita una richiesta ARP di tipo broadcast sulla rete. In essa si chiede ai computer in ascolto quale sia l'indirizzo fisico corrispondente al quell'indirizzo IP. Il computer interessato fornisce la risposta, noi la riceviamo, la mettiamo nella nostra ARP-Table, dopo di che possiamo parlare con quel computer in modo diretto. Se in seguito abbiamo nuovamente bisogno di parlargli, guardando nella ARP-Table, ci accorgeremo che conosciamo gi� l'indirizzo fisico, cos� non dovremo neppure inviare una richiesta ARP. Gi� che siamo in argomento, volevo farvi notare una curiosit� che forse non tutti conoscono (ed al tempo stesso vedrete ARP al lavoro sul vostro Pc). Quando siete in Internet, cio� adesso, lanciate da una finestra Dos il comando "arp -a"; questo comando serve per vedere la ARP-Table. Scoprirete una cosa strana: tutti gli indirizzi IP dei siti che avete visitato di recente, hanno l'indirizzo fisico uguale! Perch�? Perch� in realt� quell'indirizzo fisico corrisponde al router del vostro provider. Questo perch� quando cercate di accedere ad un sito dovete lasciare tutto in mano al router, il quale fare tutto il lavoro per voi, come se fosse un maggiordomo virtuale.
Ora che abbiamo tutto pronto, e che conosciamo grazie ad ARP l'indirizzo fisico del destinatario, non resta che spedire il tutto! Nel sistema ricevente, tutti gli header saranno analizzati ed utilizzati opportunamente e via via rimossi. |
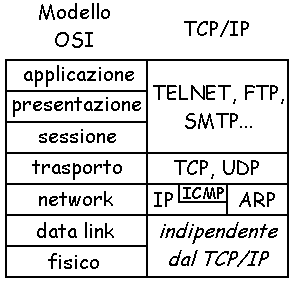 Alcuni di questi,
come TCP, UDP, IP, ICMP e ARP (li vedremo meglio dopo) sono di basso livello.
Questo significa che essi lavorano vicino al livello fisico della rete (vedremo infatti
che i loro compiti sono strettamente correlati con la trasmissione effettiva dei dati). La
loro funzione � di fornire servizi ai protocolli superiori e alle applicazioni. Se
non avete capito bene questo concetto vi consiglio di leggere la pagina
Alcuni di questi,
come TCP, UDP, IP, ICMP e ARP (li vedremo meglio dopo) sono di basso livello.
Questo significa che essi lavorano vicino al livello fisico della rete (vedremo infatti
che i loro compiti sono strettamente correlati con la trasmissione effettiva dei dati). La
loro funzione � di fornire servizi ai protocolli superiori e alle applicazioni. Se
non avete capito bene questo concetto vi consiglio di leggere la pagina