Usare Java e Linux per vincere la sfida al DES
L'ultima versione riveduta e corretta da F. P. Nasuti la potete trovare sulla Linux Gazette Edizione Italiana
Abstract
Il DES è stato usato per molto tempo per garantire la privacy
delle transazioni negli ambienti con comunicazioni pubbliche, specialmente
in ambito bancario e finanziario. Tuttavia, il livello di sicurezza offerto
da questo algoritmo non è lo stesso di prima. Le condizioni di lavoro
del DES sono state modificate dall'esponenziale crescita di Internet, e
ciò che era sicuro dieci anni fa non lo è più oggi.
Lo scopo di questo articolo è mostrare la debolezza del DES, e come
e che cosa un attacco determinato può fare per violarlo usando il
nuovo linguaggio di programmazione Java e il sistema operativo Linux.
1. Introduzione
La crittografia è stata sempre usata come un modo efficace
per proteggere le informazioni sensibili da occhi indiscreti e non autorizzati.
La crittografia ha avuto una crescita esponenziale con la Seconda Guerra
Mondiale. Sia gli Alleati che i Nazisti e i Giapponesi usarono questa tecnologia
con successo. Sostanzialmente, la crittografia è il processo che
permette di mantenere le comunicazioni private. Ci sono due problemi nella
crittografia: cifrare e decifrare. Sia cifrare che decifrare sono due problemi
della crittografia, ma non solo. I problemi come le firme digitali e i
certificati digitali sono ugualmente importanti. Oggi, due tipi differenti
di crittografia sono usati: crittografia simmetrica o a chiave segreta
e crittografia asimmetrica o a chiave pubblica. Le principale differenza
tra queste è nell'uso della chiave. Nella prima, solo una chiave
è usata sia nella cifratura che nella decifrazione, e nella seconda,
sono usate due chiavi differenti, una per cifrare e l'altra per decifrare.
Normalmente, la chiave pubblica è liberamente distribuita, mentre
la chiave privata è tenuta segreta. Tutti i sistemi di sicurezza
a chiave pubblica confidano nella segretezza della chiave privata. In questo
articolo, la nostra attenzione sarà principalmente focalizzata sul
primo caso, la crittografia a chiave segreta. Il DES è proprio uno
degli algoritmi che usano la crittografia a chiave segreta. Anche altri
la usano, come IDEA (International Data Encryption Algorithm), RC2 (Ron's
Code 2) o RC5 (Ron's Code 5). Il DES (Data Encryption Standard) è
un algoritmo di cifratura a blocchi che è stato definito e adottato
dal governo americano nel 1977 come standard ufficiale. E' stato originariamente
sviluppato da IBM nel 1970 sotto il nome di Lucifer, ed è stato
rapidamente adottato come il sistema crittografico maggiormente usato nel
mondo [1]. Principalmente istituzioni bancarie e finanziarie
usano il DES.
2. Attacchi alla crittografia
Il principale obiettivo della crittografia è mantenere tutte
le informazioni nascoste a persone non autorizzate. La crittoanalisi è
una branca della crittografia che cerca di violare la segretezza (trovare
il testo originale da un certo testo cifrato senza sapere la chiave usata
per la cifratura). Una crittoanalisi riuscita può trovare sia il
testo originale che la chiave usata. Ci sono molti modi di condurre attacchi
a questi algoritmi. Il successo o il fallimento di ciascuno dei metodi
di attacco è fortemente correlato alla quantità di informazioni
che l'aggressore può ottenere sia dal testo cifrato che in chiaro
[2].
Qualcuno dei metodi maggiormente usati sono:
- Attacco solo sul testo cifrato: il crittoanalista ha solo uno o più
esempi di testi cifrati che usano la stessa chiave e cerca di scovare il
testo in chiaro e la chiave usata.
- Attacco condotto conoscendo il testo in chiaro: in questo caso, sia
il testo cifrato che quello in chiaro di uno o più messaggi sono
disponibili per il crittoanalista.
- Attacco su un testo in chiaro scelto: è quasi simile al primo.
Comunque in questo caso, il crittoanalista può scegliere il testo
in chiaro che vuole veder cifrato.
- Attacco ad un selezionato testo in chiaro adattabile: simile al metodo
presentato prima. Comunque, il crittoanalista può scegliere la sottosequenza
di testo secondo il testo cifrato / in chiaro precedentemente scelto.
- Attacco al testo cifrato selezionato: per un cifrario simmetrico
è simile all'attacco al testo in chiaro scelto. Per i cifrari asimmetrici
il crittoanalista può scegliere il testo cifrato che deve essere
decifrato.
- Attacco a chiave scelta o con forza bruta: consiste in una ricerca
completa di tutte le possibili chiavi, decifrando il testo cifrato con
ognuna delle chiavi e cercando di ottenere un risultato comprensibile.
3. Robustezza della chiave
La questione della robustezza della chiave è sempre stata
molto controversa. La chiave crittografica più è grande,
più risulterà forte il testo cifrato generato. Comunque,
se la chiave crittografica è grande, il sistema crittografico è
anche più esigente in termini di potenza di elaborazione.
| Anno | Milioni di cifrature al secondo |
| 1995 | 4 |
| 200 | 32 |
| 2005 | 256 |
| grandezza chiave | 1995 | 2000 | 2005 |
| 40 bits | 68 secondi | 8,6 secondi | 1,07 secondi |
| 56 bits | 7,4 settimane | 6,5 giorni | 19 ore |
| 64 bits | 36,7 anni | 4,6 anni | 6,9 mesi |
| 128 bits | 6,7e23 anni | 8,4e22 anni | 1,1e22 anni |
| Anni | Milioni di cifrature al secondo |
| 1995 | 50 |
| 2000 | 400 |
| 2005 | 3200 |
| Grandezza chiave | 1995 | 2000 | 2005 |
| 40 bits | 1,3 giorni | 3,8 ore | 28,6 minuti |
| 56 bits | 228 anni | 28,6 anni | 3,6 anni |
| 64 bits | 58,5e6 anni | 7,3e6 anni | 914 anni |
| 128 bits | 1,1e18 anni | 1,3e36 anni | 1,7e25 anni |
La robustezza della chiave dipende molto dalla capacità di calcolo
disponibile. Con una più grande capacità di calcolo, minore
sarà il tempo necessario a violare un sistema crittografico.
D'altra parte, se la potenza di calcolo aumenta, lo stesso farà
la grandezza della chiave e conseguentemente la robustezza degli algoritmi
crittografici. Ma, sembra chiaro, la chiave che era considerata sicura
due o tre anni fa non lo è più oggi.
4. DES - Data Encryption Standard
Nel 1972, il National Bureau of Standards (ora conosciuto come NIST)
lanciò una richiesta alla comunità scientifica per creare
un nuovo algoritmo crittografico. Questo nuovo algoritmo doveva avere le
seguenti caratteristiche:
1. Alto livello di sicurezza
2. Completamente definito e facile da capire
3. Disponibile a tutti
4. Adattabile
5. Efficiente abbastanza da implementarlo in un computer.
Nel 1974, IBM rispose alla richiesta con un algoritmo chiamato LUCIFER (più tardi fu chiamato DEA - Data Encryption Algorithm o DES). Infine nel 1976 il DES fu adottato come standard negli Stati Uniti.
Il DES ha retto finora, per venti anni come standard internazionale.
Benché il DES alla fine stia mostrando i segni del tempo, è
ancora considerato come uno dei più forti ed efficienti algoritmi
nel mondo.
4.1. Come funziona il DES
Il DES è un cifrario a blocchi. Cifra ogni volta blocchi
di 64 bits. Un gruppo di 64 bits di testo in chiaro è processato
dall'algoritmo e un gruppo di 64 bits di testo cifrato ne viene fuori.
Il DES è un algoritmo a chiave simmetrica e usa la stessa chiave per il processo di cifratura e decifrazione. La grandezza della chiave è 56 bits. Il DES usa una chiave di 56 bits (la chiave è normalmente rappresentata da 64 bits, e ogni otto bits uno è usato per il controllo di parità).
Al suo livello più semplice, l'algoritmo è basato su due semplici principi: diffusione e confusione. Il DES applica sostituzioni seguite da permutazioni a un testo in chiaro, in base a una data chiave. Questo processo è chiamato round (ciclo) e il DES lo applica 16 volte. Il seguente schema rappresenta un più dettagliato sguardo al DES.
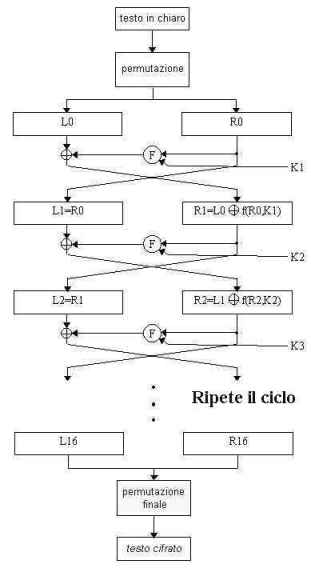
Figura 1 - Uno schema dettagliato
che mostra come lavora il DES.
Una più ampia spiegazione non è lo scopo di questo articolo.
Maggiori informazioni possono essere trovate in qualunque buon libro sulla
crittografia.
5. Le sfide crittografiche della RSA Labs
La Divisione Sicurezza Dati della RSA Labs promuove e mantiene un
gruppo di sfide crittografiche come strumenti di ricerca. [3].
Alcune delle sfide che attualmente la RSA tratta sono:
1. La sfida della RSA sulla fattorizzazione
2. La sfida della chiave segreta
3. La sfida al DES
5.1. La sfida al DES
La sfida originale al DES fu lanciata nel gennaio 1997, con l'intento
di dimostrare che la sicurezza a 56-bit, come quella proposta dal governo
degli Stati Uniti, offre solo una protezione marginale contro un avversario
tenace. Questo fu confermato quando la chiave segreta usata per la cifratura
fu scoperta il 17 giugno 1997. Da allora è stato ampiamente riconosciuto
che i più veloci e completi sforzi di ricerca sono possibili e la
seconda sfida al DES è intesa a mostrare con quale velocità.
Mentre la sfida originale mostrò che il DES era violabile usando
un attacco con ricerca completa, l'obiettivo della nuova sfida al DES è
vedere quanto velocemente un attacco con ricerca completa può essere
realizzato per aiutare a valutare la vulnerabilità del DES.
Due volte all'anno, il 13 gennaio e il 13 giugno, alle 9:00 antimeridiane
del fuso orario del Pacifico, una nuova gara sarà pubblicata sulla
homepage della RSA. La gara sarà composta dal testo cifrato prodotto
col DES, cifrando qualche messaggio sconosciuto che ha un titolo stabilito
e conosciuto. Il primo a scoprire la chiave vince e l'ammontare del premio
dipenderà dalla velocità con cui la chiave è stata
trovata.
5.2. I dettagli della sfida al DES
Per ogni gara, il messaggio sconosciuto sarà preceduto da
tre blocchi conosciuti del testo contenenti la frase di 24 caratteri: ``The
unknown message is:``. Mentre il testo misterioso sarà ovviamente
conosciuto da qualche dipendente della RSA Data Security, la chiave segreta
realmente usata per la cifratura sarà generata in maniera casuale
e distrutta dal software di generazione della sfida. La chiave non sarà
mai rivelata a nessuno.
L'obiettivo di ogni gara per i partecipanti è scoprire
la chiave segreta generata in maniera casuale e che è stata usata
nella cifratura in un tempo più veloce di quello richiesto dalla
sfida precedente.
6. Violare il DES
Molti problemi richiedono una grande quantità di potenza
di elaborazione per raggiungere la soluzione. Alcuni problemi, però,
sono soggetti a un estremamente alto livello di parallelizzazione, e con
la rete Internet di oggigiorno è possibile allargarsi a realizzare
uno sforzo di larga scala a livelli precedentemente inattesi.
Violare il DES è uno di questi problemi. E' necessario usare una potenza computazionale piuttosto ampia. Anche se noi consideriamo una chiave a 56 bit, è un compito davvero difficile da assolvere.
La migliore strategia per violare il DES è realizzare una attacco
con forza bruta. Questo significa dover testare tutte le possibili chiavi
e analizzare e comparare i risultati. Se noi consideriamo una chiave a
56 bit, significa che avremo circa 256 possibili combinazioni. Anche se
con l'odierna comune potenza computazionale lo si fa in un momento.
7. Architettura generale
Il primo aspetto da considerare quando progettiamo una architettura
generale per violare il DES è scegliere tra attacco software o hardware.
Il DES può essere davvero semplicemente implementato in un chip hardware, e molti di questi chip possono essere usati per violare il DES. Uno dei più ovvi vantaggi di questo approccio è la potenza di elaborazione che ne risulta. D'altro canto, però, uno dei problemi che risulta da questa architettura è il suo grande costo.
Un altro possibile approccio per una architettura generale è usare un attacco software. Uno dei problemi di questo tipo di architettura è la sua potenza di elaborazione. Se solo un computer è usato, la potenza di elaborazione ottenuta è abbastanza deludente. Questo tipo di attacco è davvero facile da implementare ed è anche meno costoso del precedente.
Comunque, i risultati più interessanti possono essere raggiunti
con un attacco ad elaborazione distribuita, basato sulla aumentata potenza
di elaborazione che scaturisce dall'unione di più computer.
8. Elaborazione distribuita
L'elaborazione distribuita può essere facilmente descritta
come lo sforzo di unire un complesso di macchine connesse in rete in modo
che l'informazione o altre risorse possono essere condivise da tutte le
macchine connesse. La speranza è che la divisione può aver
luogo su grandi aree, molte macchine e molti utenti, unificandoli in una
consistente e coerente struttura.
L'elaborazione distribuita è diventato un settore di studio quando l'hardware si sviluppò dal mainframe (computer centrale), dove tutti condividono le risorse di una singola macchina, al minicomputer. Il minicomputer soddisfa le esigenze di due persone (o programmi) per lavorare insieme o condividere risorse quando sono su macchine diverse. Coordinare questo lavoro, o dare accesso a queste risorse, è l'obiettivo della elaborazione distribuita.
L'interesse nell'elaborazione distribuita è incrementato con
l'avvento delle workstation individuali e dei PC connessi in rete, principalmente
con la diffusione di Internet. Siccome queste sono macchine per singoli
utenti, occorre condividere le informazioni, le risorse di elaborazione
o i dati in modo che diventino disponibili appena giunge il lavoro da svolgere.
9. Architettura specifica
Come è stato già detto, una della possibili strade
per costruire una architettura per violare il DES è attraverso una
architettura di elaborazione distribuita.
Comunque, alcune considerazioni dovrebbero essere fatte. Per esempio, qual è la migliore configurazione e quali sono i suoi limiti.
Nessun dubbio che, per approfittare della disponibilità della potenza di elaborazione su Internet la migliore soluzione è implementare una tipica architettura client-server. Un server per distribuire le chiavi, i client per fare il lavoro più impegnativo: testare tutte le chiavi e controllare i risultati.
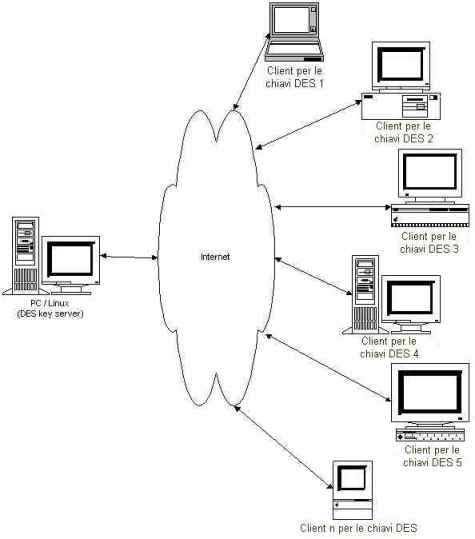
Figura 2 - L'architettura distribuita
in generale
9.1. Considerazioni
Ci sono diversi approcci per una ricerca completa. La considerazione
più importamte è se la ricerca è coordinata da qualche
server centrale, o se più processi iniziano in posizioni casuali
nello spazio della ricerca e girano indipendentemente finché una
chiave viene trovata.
L'uso di un server centrale pone qualche difficoltà. Pure prevedendo una sola mancanza, c'è anche il pericolo di congestione della rete e collasso.
Una varietà di precauzioni dovrebbe essere tenuta in conto. I
server possono essere connessi in una gerarchia, o replicati se le risorse
lo permettono, così che i casi di fallimento sono meno catastrofici.
In più, i client possono autotestarsi per fornire qualche livello
di sicurezza contro i malfunzionamenti e i server posson cautelarsi da
client maligni poichè possono condurre dei test più specifici
sui client. I server possono avere dai client un resoconto sui problemi
provocati dai server che possono essere verificati a basso costo. Alternativamente
un client potrebbe calcolare una somma di controllo su tutte le soluzioni
tentate nel campo esaminato e un altro client della stessa architettura
potrebbe verificare questo.
9.2. Funzionalità
Benché una architettura client-server presenti qualche problema,
è ancora la più facile e meno costosa da implementare e mantenere.
L'idea base è avere un server centrale, che deve compiere semplici compiti, come aggiungere nuovi client alla gara, distribuire nuovi gruppi di chiavi e verificare e aggiornare i risultati.
Il server stesso fa solo il lavoro più facile nel sistema. Il lavoro più pesante, cioè provare tutte le possibili chiavi e verificare i risultati, è fatto dal gruppo di client. Tanti più client ha il sistema, più veloce sarà la verifica di tutte le chiavi possibili.
Le funzionalità del server possono essere facilmente riepilogate nel seguente schema.
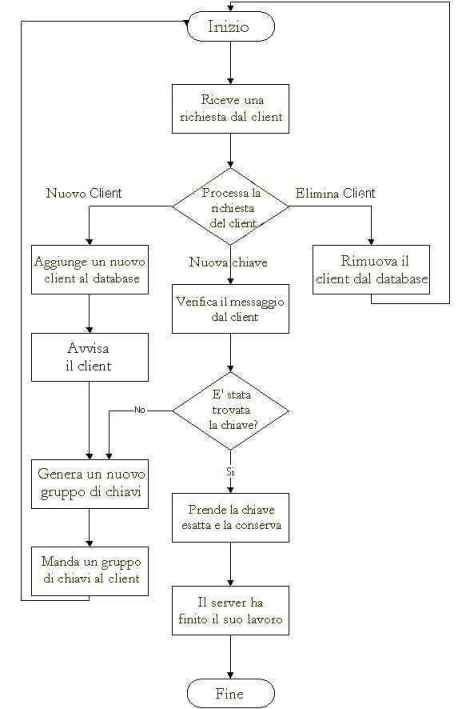
Figura 3 - Funzionalità
del server.
Le funzionalità del client possono essere riepilogate così:
Fondamentalmente, la principale funzionalità del software client è testare tutte le possibili chiavi distribuite dal server e quindi analizzare il risultato e testare se la chiave è giusta o meno.
Se la chiave è giusta, il client la comunica al server e manda una nota al server per indicare che ha trovato la chiave.
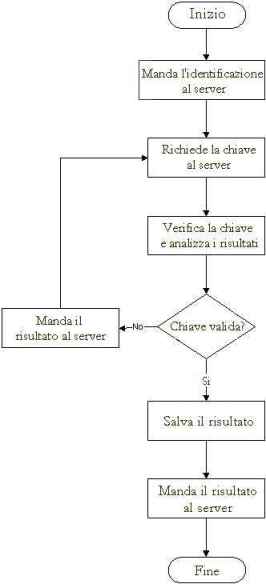
Figura 4 - Funzionalità
del client.
10. Implementazione
Nessun dubbio sussiste che la migliore architettura possibile per
affrontare la sfida al DES è usare una architettura client-server
distribuita su Internet.
Per implementare tale architettura, qualche importante decisione deve
essere presa, come scegliere la migliore piattaforma di sviluppo e i mezzi
giusti.
10.1. Linux
Linux è un sistema operativo che rispetta le specifiche Posix
disegnato per girare su architettura Intel. Il sistema ha anche estensioni
per conformarsi alle richieste di System V e BSD.
Questo sistema operativo è sotto licenza pubblica GNU ed è liberamente distribuibile provvisto di sorgenti nella forma di distribuzioni oppure il sorgente è almeno reso disponibile al destinatario.
Linux gira su processori Intel 386 e successivi che sono capaci di usare la modalità protetta 386.
Per una implementazione minima occorrono circa 10-15 Megabyte di spazio su disco e 8 Mega di RAM. E' possibile che giri in 4, ma si consideri 8 un minimo ragionevole per l'installazione basata sul testo. Per usare X (il sistema a finestra di Unix) con una ragionevole efficienza, occorreranno circa 16 Mega di RAM come minimo (300 M di spazio su disco).
Il sistema può compilare e girare programmi Unix rispettosi delle specifiche Posix, come programmi Dos attraverso DosEmu. Le applicazioni Windows hanno successo limitato girando su Linux attraverso l'uso di Wine (un emulatore di Windows).
Benché Linux è di solito riferito a macchine 386/486/Pentium,
gira anche su, o è stato da poco portato su, altre architetture
(per esempio DEC Alpha, Sun SPARC, MIPS, PowerPC, and PowerMAC).
10.2. Java
Java è un linguaggio di programmazione orientato agli oggetti
sviluppato da Sun Microsystems, e ora sviluppato dalla sua sussidiaria
JavaSoft.
Al primo sguardo assomiglia al C e C++, ma sotto sotto è differente. Java è un linguaggio sia compilato che interpretato. Il suo codice sorgente è compilato in una forma universale - codice macchina per una macchina virtuale - che può essere facilmente portato attraverso Internet e interpretato e fatto girare su molte piattaforme.
Comparato ad altri linguaggi Java è molto più semplice, robusto ed economicamente valido. Permette a una applicazione di essere sviluppata con un minimo di debugging ed è istantaneamente portatile su molti sistemi operativi. Comparato ad altre soluzioni Internet, Java offre performance ineguagliate e versatilità minimizzando il carico dei server web distribuendo il processo che deve girare alle macchine client.
Java possiede anche una serie di API addizionali che permettono lo sviluppo
veloce di applicazioni complesse. Include ad esempio API per Networking,
Metodi di Comunicazione Distribuita, Connettività ai Database e
supporto alla Crittografia.
10.2.1. Java RMI
La tecnologia Java RMI (Remote Method Invocation, Metodo di invocazione
remoto) è la base per l'elaborazione distribuita in ambiente Java.
Siccome Java RMI è stata creata dopo un'ampia accoglienza di Internet
e del design orientato agli oggetti, gli sviluppatori si adoperano per
un dinamico e flessibile ambiente di sviluppo per applicazioni distribuite.
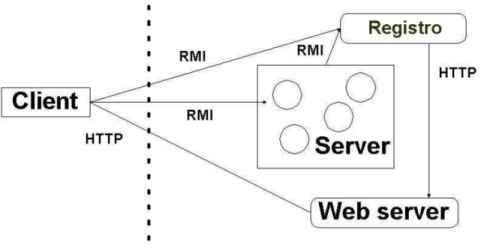
Figura 5 - Il comportamento della
tecnologia Java RMI in una applicazione distribuita.
A causa della tecnologia Java RMI, gli sviluppatori ora possono:
1. Creare facilmente potenti applicazioni distribuite e servizi di rete
per ambienti Java e non-Java.
2. Usare Java RMI, una singola interfaccia di programmazione, per comunicazioni
a oggetti in applicazioni distribuite.
10.2.2. JDBC
JDBC (Java Database Connectivity) è un' API (application
program interface, interfaccia di programmi di applicazione) per programmi
di rete scritti in Java per gsetire i dati usati nei database popolari.
L'API permette di codificare i comandi di richiesta di accesso per le interrogazioni
fatte con un linguaggio strutturato (SQL) che sono quindi passate al programma
che amministra il database. Esso restituisce il risultato attraverso una
interfaccia simile. JDBC è molto simile all' ODBC (Open Database
Connectivity) di Microsoft e, con un piccolo programma "ponte", puoi usare
l'interfaccia JDBC per accedere ai database attraverso l'interfaccia ODBC
di Microsoft. Per esempio, puoi scrivere un programma progettato per accedere
a molti database popolari in parecchi sistemi operativi. Quando accedi
ad un database in un PC con MS Windows 95 e, per esempio, un database MS
Access, il tuo programma con comandi JDBC sarà capace di accedere
al database MS Access.
JDBC in realtà ha due livelli di interfaccie. In aggiunta all'interfaccia principale, c'è anche una API per un JDBC "manager" che comunica con i "driver" dei database individuali, il ponte JDBC-ODBC se necessario, e una driver per la rete JDBC quando il programma Java sta girando in un ambiente di rete (cioè, sta accedendo a un database remoto).
Quando accede a un database remoto, JDBC si avvantaggia dello schema di indirizzamento dei file di Internet e un nome di file assomiglia molto a un indirizzo di pagina Web (URL). Per esempio, un comando JAVA SQL può identificare il database come:
jdbc:odbc://www.somecompany.com:400/databasefile
JDBC specifica un gruppo di classi di programmazione orientata agli
oggetti da usare nella costruzione della richieste SQL. Un gruppo aggiuntivo
di classi descrive il JDBC driver API. Il più comune tipo di dati
SQL, sono mappati con i tipi di dati Java, e sono supportati. L'API provvede
alla specifica implementazione di supporto per richieste di transazione
e la capacità di consegnare o ritornare indietro all'inizio della
transazione.
10.2.3. JCE
La JCE (Java Cryptography Extension) estende l'API JCA (Java Cryptography
Architecture) circa le caratteristiche aggiuntive per il supporto alla
cifratura e allo scambio di chiavi.
La JCE è un gruppo di API e implementazioni di funzionalità crittografiche, incluse cifratura simmetrica, asimmetrica, di flusso e a blocchi. Essa integra le funzionalità di sicurezza del carente JDK 1.1.x / 1.2, che include firme digitali (DSA) e raccolta messaggi (MD5, SHA).
L'architettura della JCE segue gli stessi principi di design trovati
altrove nella JCA.
10.2.4. PostgreSQL
I tradizionali sistemi di amministrazione dei database relazionali
(DBMS) supportano un modello di dati che consistono in un insieme di relazioni
fra gli oggetti, contenenti attributi di un tipo specifico.
Nei correnti sistemi commerciali, i tipi possibili includono numeri a virgola mobile, interi, stringhe di caratteri, valute e date. E' comunemente riconosciuto che questo modello è inadeguato per le future applicazioni di elaborazione dati. Il modello relazionale sostuì con successo i vecchi modelli in parte per la sua spartana semplicità. Comunque, come già detto, questa semplicità spesso rende molto difficile l'implementazione di certe applicazioni. Postgres offre una sostanziale potenza aggiuntiva incorporando i seguenti quattro concetti base in modo che gli utenti possano facilmente estendere il sistema:
- classi
- ereditarietà
- tipi
- funzioni
Altre caratteristiche forniscono potenza aggiuntiva e flessibilità:
1. legami di integrita' referenziale
2. triggers (N.d.T., condizioni che determinano una determinata reazione)
3. regole
4. integrita' dei dati
Queste caratteristiche pongono Postgres nella categoria dei database relazionali e a oggetti. Nota che questo è diverso da quelli detti anche orientati agli oggetti, che in generale non sono adatti al supporto dei linguaggi dei tradizionali database relazionali. Così, benché Postgres ha qualche caratteristica orientata agli oggetti, è fermamente nel mondo dei database relazionali. Infatti, alcuni database commerciali hanno recentemente incluso caratteristiche a cui Postgres ha aperto la strada.
PostgreSQL è quindi un sofisticato DBMS relazionale e a oggetti,
supportando quasi tutti i costrutti SQL, includendo transazioni, sottoselezioni,
tipi e funzioni definiti dall'utente. E' il più avanzato database
open-source disponibile dovunque.
10.3. Mettiamo tutto insieme
Ora, dopo aver in mente i mezzi e quale architettura usare, è
necessario mettere tutto insieme.
La piattaforma di sviluppo scelta è Linux, per la sua caratteristica di buon sistema di sviluppo. Il linguaggio usato sarà Java, per la sua semplicità.
Dal lato server, una delle più importanti cose da definire è il database server. Questo database è abbastanza importante perché immagazzinerà importanti informazioni sulla gara, come dettagliate informazioni sui client della gara, il gruppo di chiavi che ogni client sta attualmente processando, quale è stata l'ultima chiave a essere stata distribuita tra le altre cose.
Il database sarà sviluppato usando un database free a oggetti e relazionale chiamato PostgreSQL. Il server software, totalmente sviluppato in Java, si interfaccerà con i database attraverso le API JDBC.
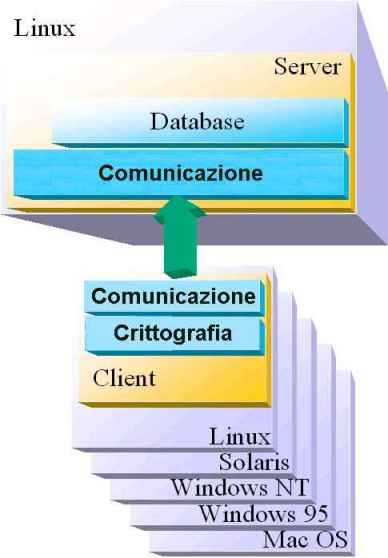
Figura 6 - Configurazione finale
dell'architettura client-server.
Una delle principali funzioni di un server è aspettare e ricevere richieste da un client. Il server delle chiavi DES ha lo stesso comportamento. Il server parte, attende e processa le richieste. Per comunicare con i client è necessario avere qualche funzionalità di rete. In questo caso, il server, riceve richieste dai client attraverso RMI. RMI è stato scelto, perché aggiunge uno strato di astrazione tra il programma Java e la complessità della rete.
Dal lato client, una delle più importanti cose da implementare è la funzionalità crittografica. Il software client dovrebbe essere capace di usare e processare l'algoritmo DES. Poiché il software client conoscerà parte del testo in chiaro e l'intero messaggio segreto, deve essere capace di cercare di decifrare il messaggio segreto usando una chiave fornita dal server e comparare i risultati con il testo parziale in chiaro.
Siccome è nel server, questo software client è totalmente
implementato in Java. Questo permette che un largo numero di differenti
computer e piattaforme si unisca rapidamente alla gara, allargando considerevolmente
la potenza di elaborazione per trovare il più rapidamente possibile
una soluzione per il problema proposto, trovare la corretta chiave DES.
11. Conclusioni
Il DES a 56-bit non è più sicuro. E' chiaro che con
l'odierna potenza elaborativa, e con le crescenti capacità di rete,
come Internet, è facile costruire una architettura per violare una
chiave DES.
Linux e Java sono due dei mezzi che permettono la facile creazione di
tale architettura e renderla disponibile a quasi tutti. Linux, siccome
è un sistema operativo semplice, veloce, potente e free che permette
di costruire potenti capacità server. Java, perchè è
facile da imparare e il suo essere indipendente dalla architettura permette
uno sviluppo veloce per una gran numero di piattaforme diverse.
Note
[1] RSA Laboratories - Cryptographic Research and
Consultation, "Answers to Frequently Asked Questions About Today's Cryptography
- Version 3.0", RSA Data Security, 1996
[2] Schneier, Bruce, "Applied Cryptography - Protocols, Algorithms and Source code in C", John Wiley & sons, Inc., 1996
[3] "DES Challenge II", RSA Laboratories, RSA Data Security,
http://www.rsa.com/rsalabs/des2,
1997
Copyright © 1999, Carlos Serrao
Pubblicato sul numero 46 di Linux Gazette, Ottobre 1999
Tradotto in italiano da ADaM "unno" unno@softhome.net