Next: H.261 Up: La codifica video Previous: La codifica video Contents Index
Un segnale video digitale consiste di una sequenza di frame video, ciascuna frame è fatta da un insieme di valori numerici che rappresentano i campioni dell'immmagine originaria.
Una sequenza video di buona qualità richiede uno spazio per la memorizzazione, o equivalentemente un bit-rate per la trasmissione, molto elevato. Si pensi ad esempio ad immagini con una risoluzione spaziale pari a 720×576 pixel e quantizzate ad 8 bit/pixel, nel caso di un frame-rate pari a 25 frame/s la trasmissione del segnale richierde un bit-rate r pari a:
Ogni segnale presenta un certo grado di ridondanza al suo interno, riducendo questa ridondanza si ottiene una rappresentazione più compatta.
La ridondanza è essenzialmente di due tipi:
L'operazione di codifica può essere o meno invertibile, dove con invertibilità intendiamo la possibilità di ricostruire esattamente l'immagine di partenza. Quindi si può distinguere tra algoritmi di compressione lossy (con perdita di informazione e quindi non invertibili) e lossless (senza perdite, in questo caso è possibile ricostruire esattamente il segnale originale).
Un parametro che permette di confrontare i vari algoritmi di codifica è il rapporto di compressione, può essere definito come il rapporto fra il tasso del segnale originario e quello del segnale codificato. Quanto maggiore è questo valore tanto maggiore sarà la riduzione ad esempio del bit-rate del segnale codificato rispetto a quello del segnale originario. É chiaro però che per gli algoritmi lossy, che introducono anche una perdita di informazione, questo parametro da solo non basta a caratterizzare le prestazioni di codifica. In questi casi è necessario quantificare la perdita di qualità, questo tipicamente viene fatto attraverso delle misure oggettive della distorsione come ad esempio l'errore quadratico medio (MSE, Mean Square Error), o il rapporto segnale-rumore di picco (PSNR, Peak Signal to Noise Ratio):
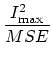
Per quanto sofisticate possano essere, non è detto che le misure oggettive della distorsione diano una buona indicazione della qualità dell'immagine ricostruita. Specialmente nel campo della codifica video, non è difficile trovare situazioni in cui immagini caratterizzate dalla stessa qualità oggettiva abbiano una qualità soggettiva molto diversa. In altre parole, non è detto che ad una maggiore qualità oggettiva debba necessariamente corrispondente una maggiore qualità soggettiva. Per questo motivo, spesso alle misure oggettive si affiancano quelle soggettive in modo da dare una valutazione più precisa delle prestazioni del codificatore.
Abbiamo visto che nella valutazione di un algoritmo di codifica vanno presi in considerazione tanto il rapporto di compressione che le misure di qualità, tuttavia non bisogna mai dimenticarsi del contesto nel quale l'algoritmo si troverà ad operare, e quindi non si può trascurare un'altra caratteristica molto importante e cioè la richiesta di risorse hardware.
Tipicamente quanto più un algoritmo è efficiente (nel senso del trade-off compressione/qualità) tanto più è complesso, e quindi richiede maggiori risorse hardware. Tuttavia non è detto che ad un codificatore complesso debba necessariamente corrispondere un decodificatore altrettanto complesso, ed in questo senso è possibile distinguere tra:
In genere gli algoritmi di codifica vengono costruiti mettendo insieme più strategie, al fine di soddisfare i requisiti del progetto cercando di riutilizzare quanto più possibile risultati che sono già consolidati, di seguito vengono illustrate alcune tra le più diffuse tecniche di compressione.
Intuitivamente possiamo immaginare una tecnica che ci permetta rappresentare un immagine usando solo un numero limitato di ``tasselli'' predefiniti, questo concetto è alla base della quantizzazione vettoriale, estensione della più nota quantizzazione scalare al caso multidimensionale. In pratica l'immagine viene suddivisa in blocchi di dimensioni M×N e ciascun blocco viene confrontato con un numero limitato di blocchi di riferimento (codebook). Tra questi si sceglie quello che meglio rappresenta il blocco originale e ne viene trasmesso l'indice che lo identifica all'interno del codebook, ovviamente si richiede che il codebook utilizzato sia disponibile anche per il decodificatore. Essendo il numero di blocchi di riferimento limitato, molto inferiore rispetto a quelle che sono tutte le possibili configurazioni di blocchi M×N, trasmettere l'identificativo di un tale blocco è molto meno dispendioso che trasmettere l'intero blocco originale. La quantizzazione vettoriale è una tecnica molto generale con la quale si riesce a sfruttare bene la dipendenza statistica presente tra i pixel contigui, tuttavia la sua complessità computazionale cresce notevolmente al crescere delle dimensioni dei blocchi, questo impedisce di ottenere rapporti di compressione elevati. Per questo motivo spesso se ne usano versioni ``vincolate'' in cui, a patto di vincolare opportunamente la struttura del codice e la strategia di ricerca, si riesce ad ottenere una complessità computazionale ed una richiesta di memoria accettabili.
Nella codifica con trasformata l'ingresso è diviso in blocchi che vengono poi sottoposti ad una trasformazione lineare. Lo scopo della trasformazione è quello di rappresentare il blocco in un dominio trasformato nel quale i campioni di uscita siano indipendenti (o quanto meno abbiano una bassa correlazione). Un'altra caratteristica richiesta è la compattazione dell'energia in pochi campioni di uscita: a valle della trasformazione la maggior parte dell'energia sarà contenuta in pochi campioni, rendendo di fatto trascurabili gli altri. Tornando nel dominio di partenza, l'errore commesso non trasmettendo le componenti a bassa energia si ridistribuisce su tutto il blocco divenendo meno visibile. É possibile dimostrare che la trasformata ottima secondo i due criteri di cui sopra è la trasformata di Karhunen-Loeve, essa tuttavia è di notevole complessità computazionale. Nella pratica vengono utilizzate trasformazioni sub-ottime che però hanno una complessità computazionale molto più bassa. La DCT (Discrete Cosine Transform) è una delle più utilizzate, anche perché data la particolare forma della funzione di correlazione delle immagini, le sue prestazioni si avvicinano molto a quelle della trasformata ottima ed inoltre esiste un algoritmo per il calcolo veloce simile alla FFT (Fast Fourier Transform), utilizzata per il calcolo della trasformata di Fourier. La codifica con trasformata è forse la tecnica più utilizzata nella codifica video, offre una elevata qualità abbinata ad un ottimo rapporto di compressione, tuttavia anche in questo caso la complessità computazionale è discretamente elevata.
La codifica predittiva, invece, sfrutta la ridondanza statistica esistente tra i campioni. Quindi invece di trasmettere i campioni viene trasmessa la differenza tra il campione attuale ed il campione predetto sulla base dei campioni precedenti. A causa della dipendenza statistica l'errore sarà molto contenuto e quindi è possibile rappresentarlo con un numero minore di bit rispetto al campione, ed in questo modo si riduce il bit-rate.
Attualmente molti sforzi di ricerca sono concentrati sulla codifica per sintesi, in questo caso si cerca di estrarre dall'immagine delle informazioni che permettano al decodificatore di sintetizzare l'immagine, ad esempio, come avviene nel caso della videotelefonia, le informazioni possono riguardare la posizione di alcuni punti caratteristici di un volto. In questo modo si riesce ad ottenere una compressione molto spinta, ma chiaramente tali tecniche richiedono un'elevata complessità di calcolo.
Per quanto riguarda la codifica interframe attualmente si possono individuare due tecniche principali, il movement compensation e il conditional replenishment. Nel primo caso si sfrutta il fatto che spesso nelle sequenze in movimento in pratica si hanno dei blocchi di immagine che compiono delle traslazioni, e per ognuno di essi invece che ritrasmettere tutto il blocco di dati, si può semplicemente trasmettere la traslazione corrispondente. Nel caso del conditional replenishment invece si suddivide l'immagine in tanti blocchi, ogni blocco viene poi confrontato con quello che occupa la stessa posizione nella frame precedente (o comunque in un'altra frame utilizzata come riferimento) e il blocco viene trasmesso solo se risulta cambiato (tipicamente si confronta l'energia della differenza dei due blocchi con un opportuno valore di soglia). Dei due, quello che offre il maggiore rapporto di compressione è certamente il movement compensation, tuttavia richiede anche una complessità computazionale nettamente superiore.
Molto spesso, come dicevamo in precedenza, gli algoritmi di codifica vengono costruiti combinando alcune di queste (ed altre) tecniche, quindi ad esempio si può combinare la codifica con trasformata (per una singola frame) con il movement compensation (tra frame e frame). La scelta di quali utilizzare è essenzialmente dettata dal tipo di applicazione verso la quale ci si rivolge. Ad esempio se l'obiettivo è quello di contenere la complessità computazionale (ad esempio perché si vuol utilizzare il codec in tempo reale) si dovrà scartare il movement compensation e puntare sul conditional replenishment, se invece l'obiettivo primario è il rapporto di compressione (ad esempio per permettere l'archivazione di filmati) si possono utilizzare tecniche come la codifica con trasformata e il movement compensation.
Debian User 2003-06-05