|
|
| Introduzione allo Shell Scripting |
|
|
In questo capitolo sono raggruppati alcuni argomenti più specialistici che semplificano la vita di chi si accinge a fare uno script con la shell Bash (Alzi la mano chi non è un po' pigro!).
Immaginiamo di aver fatto uno script in cui le stesse istruzioni dovrebbero essere scritte più volte all'interno del codice. Il copia ed incolla potrebbe essere una soluzione a questo fastidiosissimo problema, ma di sicuro non sarebbe elegante.
Cerchiamo di risolvere il problema pensando a ciò che facciamo durante
il quotidiano. Quando andiamo a fare la spesa e compriamo divesi
oggetti, mettiamo tutto all'interno di un sacchetto, anziché portare
ogni cosa a mano; ecco il lampo di genio, ci serve qualcosa di
analogo!
La shell Bash ci offre degli speciali sacchetti per la spesa,
le funzioni (Saranno biodegradabili?) con le quali possiamo
risparmiare molta fatica e conservare uno stile di programmazione
elegante. La definizione schematica di una funzione Bash è
[ function ] nome_funzione () {
COMANDI
}
Analizziamo brevemente quanto scritto; la parola chiave
function è tra parentesi quadre poiché opzionale, infatti
possiamo equivalentemente scrivere
function nome_funzione () {
COMANDI
}
o
nome_funzione () {
COMANDI
}
L'unica differenza tra le due forme dichiarative sta nel fatto che la
scrittura di function consente di omettere le parentesi tonde
(), altrimenti obbligatorie. Altra cosa importante da notare
è che le parentesi graffe devono essere separate dal testo che le
precede tramite uno spazio, un TAB
(
Definendo una funzione, si ha l'opportunità di richiamare i comandi in
essa contenuti in maniera più semplice all'interno di uno script,
possiamo anche passarle argomenti sotto forma di parametri posizionali
(sezione 2.3) e ritornare allo script un valore attraverso
il quale scegliere cosa fare successivamente4.1. Nel
seguito
analizzeremo altre peculiarità delle funzioni.
È ora di smettere con le parole e considerare un esempio.
#!/bin/bash
#
# Un primo esempio di funzione
EXIT_SUCCESS=0
EXIT_FAILURE=1
CONTINUA=2
fai_questo () {
echo "Hai scritto: $1"
echo "Vuoi smettere?"
read RISPOSTA
case "$RISPOSTA" in
si|s|yes|y)
return $EXIT_SUCCESS
;;
no|n)
return $CONTINUA
;;
*)
echo "Non ho capito cosa hai scritto, termino subito!"
exit $EXIT_FAILURE
;;
esac
}
while true; do
echo "Scrivi una parola: "
read PRESS
fai_questo $PRESS
RITORNO=$?
case $RITORNO in
$EXIT_SUCCESS)
exit $RITORNO
;;
$CONTINUA)
:
;;
esac
done
Abbiamo a che fare con la nostra prima funzione, ovvero con fai_questo(), che utilizziamo per raggruppare una serie di comandi.
Procediamo con ordine, innanzi tutto vediamo che la funzione fa uso
del parametro posizionale $1, ciò vuol dire che
fai_questo() accetta un solo argomento che si passa alla
funzione sotto forma di parametro posizionale. Successivamente viene
letto un valore dalla tastiera ed in base alla risposta data si
ritorna, attraverso l'istruzione interna return, un
determinato valore o si conclude lo script nel caso in cui la risposta
non fosse chiara.
Finito il corpo della funzione, abbiamo il resto dello script che
consiste in un ciclo infinito,
![]() . Il comando
true (Del pacchetto GNU Shell
Utils) non compie assolutamente alcuna azione, ma ritorna
all'ambiente di esecuzione un codice di successo, quindi il ciclo
continua indefinitamente. L'uscita o meno dal ciclo dipende dal valore
di ritorno della funzione fai_questo(). Se il ritorno è
$EXIT_SUCCESS, allora viene interrotto non solo il ciclo, ma
anche l'esecuzione dello script tramite la chiamata
. Il comando
true (Del pacchetto GNU Shell
Utils) non compie assolutamente alcuna azione, ma ritorna
all'ambiente di esecuzione un codice di successo, quindi il ciclo
continua indefinitamente. L'uscita o meno dal ciclo dipende dal valore
di ritorno della funzione fai_questo(). Se il ritorno è
$EXIT_SUCCESS, allora viene interrotto non solo il ciclo, ma
anche l'esecuzione dello script tramite la chiamata
![]() . Se invece il ritorno è $CONTINUA, allora viene
eseguito il comando
. Se invece il ritorno è $CONTINUA, allora viene
eseguito il comando
![]() , che non è
altro se non l'equivalente di true interno alla shell.
, che non è
altro se non l'equivalente di true interno alla shell.
Può accadere che sia necessario utilizzare all'interno di una funzione un nome di variabile già utilizzato nel codice dello script. Ciò accade spesso negli script di grosse dimensioni, in cui si vuole che le variabili abbiano nomi espressivi.
Per evitare di modificare il valore della variabile globale (Globale?
Si, rispetto a quella presente nella funzione, ma in realtà si tratta
sempre di una variabile la cui esistenza è limitata all'esecuzione
dello script), la shell Bash consente di dichiarare delle
variabili che ``vivono'' solo all'interno del corpo della funzione,
tali variabili vengono dette locali e vengono dichiarate
attraverso l'istruzione
![]() .
.
Come al solito, le parentesi quadre rappresentano argomenti
facoltativi, infatti local può essere richiamato da solo
(sempre all'interno di una funzione) con il risultato di stampare
sullo standard output una lista di variabili locali definite in una
funzione. Vediamo di chiarire le nostre idee con un esempio.
#!/bin/bash
#
# Uso di local
EXIT_SUCCESS=0
funzione () {
local VARIABILE="Sono all'interno della funzione"
echo -e "\t$VARIABILE"
}
VARIABILE="Sono all'esterno della funzione"
echo $VARIABILE
funzione
echo $VARIABILE
exit $EXIT_SUCCESS
Dopo i soliti convenevoli, abbiamo definito la funzione funzione() (Bel nome, vero?) ed all'interno di questa la variabile locale $VARIABILE (Quelli che usiamo, sono sempre nomi espressivi!), assegnadole il valore ``Sono all'interno della funzione''. Nel seguito, definiamo per tutto lo script la variabile $VARIABILE (locale allo script, ma globale rispetto alla funzione) assegnandole il valore ``Sono all'esterno della funzione''. Se eseguiamo lo script, ci accorgiamo che l'assegnazione fatta all'interno di funzione() non intacca minimamente il valore ``globale'' di $VARIABILE, infatti otteniamo:
[nico@deepcool nico]$ ./local.sh
Sono all'esterno della funzione
Sono all'interno della funzione
Sono all'esterno della funzione
La shell Bash consente di scrivere funzioni che richiamano sè stesse. Tali funzioni vengono dette ricorsive. Una funzione ricorsiva si rende particolarmente utile quando all'interno di una funzione occorre applicare ad un dato la funzione stessa, in questo modo, anziché realizzare complessi passaggi di valori, si può semplicemente risolvere il problema consentendo alla funzione di richiamarsi.
Chiariamo il tutto con un esempio.
Capita spesso, scambiando file con amici, di averne alcuni con
estensioni in maiuscolo (file.JPG, file.HTM) sparsi
per il proprio disco fisso. Sarebbe bello escogitare un sistema per
far cambiare automagicamente tutte queste estensioni in minuscolo.
Proviamo a vedere come fare!
#!/bin/bash
#
# Una funzione ricorsiva
EXIT_SUCCESS=0
EXIT_FAILURE=1
utilizzo () {
echo "$(basename $0) <estensione> [directory di partenza]"
exit $EXIT_FAILURE
}
sostituisci_estensione () {
E=$1
# Un'abbreviazione per ESTENSIONE
if [ -z "$2" ]; then
DIR=$PWD
else
DIR=$2
fi
N_E=$(echo $E | tr [A-Z] [a-z])
# Un'abbreviazione per NUOVA_ESTENSIONE
cd $DIR
for ELEMENTO in $(ls) ; do
if [ -d "$ELEMENTO" ]; then
sostituisci_estensione "$E" "$ELEMENTO"
elif [ -n "$(echo $ELEMENTO | grep -E "\.${E}$")" ]; then
mv $ELEMENTO ${ELEMENTO%$E}$N_E
fi
done
cd ..
}
if [ $# -eq 0 -o $# -gt 2 ]; then
utilizzo
# Se lo script è stato lanciato con 0 o più di 2 argomenti,
# mostriamo come si lancia e ritorniamo un errore.
fi
echo "INIZIO QUI!"
sostituisci_estensione "$1" "$2"
echo "HO FINITO!"
exit $EXIT_SUCCESS
Come prima cosa, definiamo una funzione utilizzo() che ci sarà utile per dire con cortesia che il programma è stato utilizzato male. Per ottenere il nome dello script, utilizziamo il comando basename sul parametro posizionale $0. Successivamente, definiamo la funzione sostituisci_estensione(); questa accetta 2 valori, il primo è l'estensione (in maiuscolo!) che vogliamo sostituire, il secondo è, invece, la directory dalla quale partire ad applicare lo script (qualora non si fornisse il secondo valore, la directory di partenza sarebbe $PWD). Questi valori vengono poi assegnati rispettivamente alle variabili $ESTENSIONE e $DIR. Tramite il comando tr (guardarne la pagina manuale!!) si ottiene l'estensione in caratteri minuscoli e la si deposita nella variabile $NUOVA_ESTENSIONE.
Ora inizia il lavoro sporco! Si entra nella directory di partenza
(cd $DIR) e si analizzano ad uno ad uno i file presenti.
Se uno di questi è una directory, allora gli si riapplica la funzione
(sostituisci_estensione $ESTENSIONE
``$ELEMENTO``), altrimenti si verifica che il
file abbia l'estensione data (
![]() ), man grep e
man 7 regex per informazioni su grep e le
espressioni regolari). Se il file ha l'estensione cercata, allora
viene fatto il cambio, altrimenti si prosegue con il ciclo. Una volta
finiti gli elementi da controllare, si ritorna nella
directory superiore. Qui finisce la funzione ricorsiva.
), man grep e
man 7 regex per informazioni su grep e le
espressioni regolari). Se il file ha l'estensione cercata, allora
viene fatto il cambio, altrimenti si prosegue con il ciclo. Una volta
finiti gli elementi da controllare, si ritorna nella
directory superiore. Qui finisce la funzione ricorsiva.
Il resto dello script non fa altro che controllare che siano stati
forniti da uno a due parametri, per poi, in caso affermativo,
richiamare la funzione sostituisci_estensione() sui
parametri passati.
Come ulteriore esempio sulle funzioni ricorsive, consideriamo una
implementazione dell'algoritmo di Euclide per il calcolo del massimo comun divisore
(mcd) di due numeri. Questo algoritmo consiste nella
relazione per ricorrenza (valida per ![]() ed
ed ![]() naturali):
naturali):
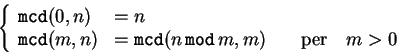
#!/bin/bash
#
# Funzioni ricorsive: calcolo del massimo comun divisore
# di due numeri tramite l'algoritmo di Euclide
EXIT_SUCCESS=0
EXIT_FAILURE=1
utilizzo () {
echo "$(basename $0) <primo numero> <secondo numero>"
exit $EXIT_FAILURE
}
mcd () {
m=$1
n=$2
if [ $n -eq 0 -a $m -eq 0 ]; then
echo "mcd(0,0) non è definito!"
exit $EXIT_FAILURE
elif [ $m -eq 0 ]; then
return $n
elif [ $n -eq 0 ]; then
return $m
fi
mcd $(( $n % $m )) $m
}
if [ $# -ne 2 ]; then
utilizzo
fi
mcd $1 $2
MCD=$?
echo "Il massimo comun divisore dei numeri \"$1\" \"$2\" è: $MCD"
exit $EXIT_SUCCESS
L'implementazione consiste in un'applicazione ricorsiva della funzione mcd() fino a quando $n o $m risulti essere uguale a zero, in tale caso, infatti, la relazione di ricorrenza ci dice che il calcolo del mcd è semplicissimo. La funzione controlla, dunque, che $n o $m non valgano entrambe zero (mcd(0,0) non è definito) e continua effettuando dei test su $n e $m. Se una di queste vale zero, si ritorna il valore dell'altra.
Qualora non si fosse in uno di questi casi, la funzione si richiama,
applicandosi ai valori ``$n % $m'' e $m fino a quando
non si giunge al caso semplice ($n o $m uguali a zero). In
ultimo, trovato il mcd dei due numeri, la funzione ne fa il suo valore
di ritorno, infatti, per ottenerlo abbiamo usato l'assegnazione
![]() .
.
Nella sezione 2.2 abbiamo visto che le variabili sono dei contenitori in cui conserviamo valori. Continuando con la nostra analogia, se andassimo in un negozio di casalinghi, potremmo acquistare dei set di contenitori, che, magari, potrebbero essere legati l'uno all'altro: questi sono gli array o vettori (Noi cercheremo di chiamarli sempre vettori).
Per il momento cerchiamo di capire meglio cosa siano i vettori e per
farlo, aiutiamoci con la figura 4.1.
Ritorniamo a parlare della shell e chiariamo subito che Bash,
al momento della scrittura, mette a disposizione soltanto vettori
monodimensionali, quindi non dobbiamo aspettarci di avere a che fare
con oggetti del tipo
![]() . Forse in futuro, oltre a
nome e cognome, ci sarà anche il codice fiscale ed avremo dunque
vettori bidimensionali.
. Forse in futuro, oltre a
nome e cognome, ci sarà anche il codice fiscale ed avremo dunque
vettori bidimensionali.
Consideriamo qualcosa di più specifico. Bash consente di
dichiarare esplicitamente un vettore attraverso il comando
![]() , tuttavia qualunque riga di codice del tipo
, tuttavia qualunque riga di codice del tipo ![]()
![]() creerà automaticamente un vettore.
Un'altra forma legale per dichiarare un vettore è l'assegnazione
esplicita di tutti i suoi elementi nella forma:
creerà automaticamente un vettore.
Un'altra forma legale per dichiarare un vettore è l'assegnazione
esplicita di tutti i suoi elementi nella forma:
![]() .
.
OCCORRE
FARE MOLTA ATTENZIONE AL FATTO CHE L'INDICE DI UN VETTORE PARTE
SEMPRE DA ZERO!
Riassumendo, creiamo un vettore in questi modi:
# Usando declare declare -a VETTORE declare -a ALTRO_VETTORE[10] # Nel secondo caso abbiamo creato un vettore di 10 elementi, il # primo è ALTRO_VETTORE[0], mentre l'ultimo ALTRO_VETTORE[9] # Mediante assegnazione di un elemento, in questo caso il primo # per ricordare che L'INDICE PARTE DA 0! VETTORE[0]=10 # Attraverso l'assegnazione di tutti i suoi elementi VETTORE=(11 24 32 88 55) # Provate a giocare la cinquina!
Ora che abbiamo capito come dichiarare un vettore, dobbiamo anche
vedere come poter ottenere i valori in esso contenuti. Per evitare di
dar luogo ad ambiguità, occorre sempre utilizzare la forma
![]() , in questo modo la shell capirà che stiamo
facendo riferimento all'(INDICE+1)-esimo elemento del vettore
VETTORE e lo sostituirà con il suo valore, proprio come
accade con ${VARIABILE}.
, in questo modo la shell capirà che stiamo
facendo riferimento all'(INDICE+1)-esimo elemento del vettore
VETTORE e lo sostituirà con il suo valore, proprio come
accade con ${VARIABILE}.
#!/bin/bash
#
# uso dei vettori
declare -a VETTORE[3]
VETTORE[0]="Tutto è andato bene"
VETTORE[1]="Hai inserito un numero maggiore di 20"
VETTORE[2]="Hai inserito un numero minore di 10"
inserisci_numero () {
echo "Inserisci un numero compreso tra 10 e 20"
read NUMERO
if [ "$NUMERO" -lt 10 ]; then
return 2
elif [ "$NUMERO" -gt 20 ]; then
return 1
else
return 0
fi
}
inserisci_numero
RITORNO=$?
echo ${VETTORE[$RITORNO]}
exit $RITORNO
All'inizio del codice, dichiariamo tramite declare il vettore a 3 elementi VETTORE e successivamente lo popoliamo con delle stringhe. Proseguendo definiamo la funzione inserisci_numero() alla quale diamo il compito di leggere dalla tastiera un numero e di stabilire se questo è compreso tra 10 e 20 o meno. Qualora il numero inserito non soddisfacesse tale richiesta, la funzione ne stabilirebbe il perché e ritornerebbe un opportuno valore per caratterizzare l'evento.
In ogni caso, il valore di ritorno della funzione viene immagazzinato
nella variabile $RITORNO che viene usata come indice per il
vettore VETTORE. In base al valore di $RITORNO, tramite
la linea di codice
![]() viene stampato
sullo schermo un messaggio a seconda dell'esito delle operazioni
effettuate da inserisci_numero().
viene stampato
sullo schermo un messaggio a seconda dell'esito delle operazioni
effettuate da inserisci_numero().
Continuiamo ad esaminare l'argomento ``vettori''. È possibile
utilizzare come indice di un vettore i caratteri ``*'' e
``@''; la scrittura ${VETTORE[*]} espande il vettore in
un'unica stringa composta dagli elementi del vettore separati dal
primo carattere presente in $IFS, mentre ${VETTORE[@]}
espande ogni elemento in una stringa separata. Alcuni delle tecniche
di espansione di parametri possono essere applicate con successo non
solo ad ogni elemento di un vettore, ma anche all'intero vettore
stesso. Ad esempio,
![]() e
e
![]() possono essere usati per ottenere il numero
di elementi presenti in un vettore. FIXME: Inserire una spiegazione
dettagliata a riguardo
possono essere usati per ottenere il numero
di elementi presenti in un vettore. FIXME: Inserire una spiegazione
dettagliata a riguardo
Nella sezione 2.4.5 abbiamo già avuto a che fare con gli operatori di input/output (Nel seguito abbreviato con ``I/O''); in particolare, ci siamo soffermati su ``|'', ``<'' e la coppia ``> - »''. In questa sezione, cercheremo di estendere ciò che già conosciamo, introducendo alcuni nuovi concetti.
Prima che un comando venga eseguito, è possibile redirigere sia il suo
canale di input che quello di output, utilizzando gli operatori di
reindirizzamento. Il reindirizzamento può essere anche utilizzato per
chiudere ed aprire file. Il reindirizzamento ha una sintassi bene
precisa, che la shell interpreta da sinistra verso destra; inoltre,
dato che questo può avvenire utilizzando più di una espressione, è
importante l'ordine con cui queste vengono impartite alla shell.
Ci si può chiedere perché dedicare addirittura un'intera sezione a questo argomento, che all'apparenza sembrerebbe piuttosto semplice. In un sistema Unix, tuttavia, i file occupano un ruolo assai importante; questi, infatti, forniscono un'interfaccia semplice e consistente ai vari servizi del sistema operativo ed ai dispositivi in genere. Finalmente, capiamo il significato del principio ``everything is a file'' a cui abbiamo fatto riferimento nella sezione 2.4.4.
Ciò significa che i programmi, in generale, possono usare file su
disco, porte seriali, connessioni di rete, stampanti ed altri
dispositivi tutti nello stesso modo. Nella realtà, dunque, quasi tutto
è reso disponibile sotto forma di file o in alcuni casi file
particolari, con differenze minime rispetto al caso generale, in modo
da non violare il principio espresso in precedenza.
Prima di procedere, occorre introdurre una nozione fondamentale.
Un descrittore di file è una
entità (Nel nostro caso, la shell, un numero) che identifica in
maniera univoca un file aperto in una particolare modalità, quale ad
esempio lettura o scrittura. In questo modo, ogni azione su un file
può essere intrapresa agendo sul suo descrittore.
Se non istruita diversamente, ad esempio, per ogni processo la shell
associa sempre dei descrittori di file allo standard input
(Descrittore 0), standard output (Descrittore 1) e
standard error (Descrittore 2).
[n]<>parolaL'operatore
[n]<parolaAnche qui, il parametro opzionale n rappresenta il descrittore di file su cui indirizzare il risultato dell'espansione di parola. Nel caso in cui non venisse fornito il descrittore di file n, il reindirizzamento viene effettuato su descrittore 0, ovvero lo standard input.
Ad esempio, quando abbiamo visto il comando
![]() , non avendo specificato alcun descrittore di file,
intendendevamo redirigere il contenuto di /etc/passwd sullo
standard input del comando mail nico.
, non avendo specificato alcun descrittore di file,
intendendevamo redirigere il contenuto di /etc/passwd sullo
standard input del comando mail nico.
[n]>parolaCiò fa sì che il file risultante dall'espansione di parola venga aperto (o creato nel caso non esista) in scrittura e vi si memorizzino i dati provenienti dal descrittore di file n. Nel caso in cui n manchi, si assume che si voglia reindirizzare lo standard output, descrittore 1.
È possibile anche aprire un file solo per aggiungere dati, senza
perderne il contenuto; per effettuare tale operazione è sufficiente
utilizzare l'operatore
![]() , la cui sintassi è analoga al
precedente:
, la cui sintassi è analoga al
precedente:
[n]>>parola
Abbiamo visto che un processo possiede due canali di output, uno
dedicato in generale alla rappresentazione del risultato (lo standard
output), l'altro agli errori incorsi durante l'esecuzione del processo
(lo standard error). In genere, in un calcolatore i due output vengono
mostrati sullo schermo, con il risultato di confonderli
entrambi. Tuttavia, esistono casi in cui è necessario doverli
separare; questa operazione può essere eseguita facilmente
reindirizzando lo standard error, ad esempio:
[nico@deepcool nico]$ ls -lh bg?.{jpg,png} non_esisto
ls: non_esisto: No such file or directory
-rw-rw-r-- 1 nico nico 160k Apr 15 01:20 bg1.jpg
-rw-rw-r-- 1 nico nico 249k Apr 15 01:25 bg2.jpg
-rw-rw-r-- 1 nico nico 198k Mar 30 13:47 bg2.png
-rw-rw-r-- 1 nico nico 86k May 14 11:50 bg3.png
[nico@deepcool nico]$ ls -lh bg?.{jpg,png} non_esisto 2>/dev/null
-rw-rw-r-- 1 nico nico 160k Apr 15 01:20 bg1.jpg
-rw-rw-r-- 1 nico nico 249k Apr 15 01:25 bg2.jpg
-rw-rw-r-- 1 nico nico 198k Mar 30 13:47 bg2.png
-rw-rw-r-- 1 nico nico 86k May 14 11:50 bg3.png
Come possiamo vedere, la prima esecuzione del comando
FIXME: completare.
Bash consente di duplicare i descrittori di file in modo da organizzare il più funzionalmente possibile i propri script. Ad esempio, può essere necessario assegnare temporaneamente un descrittore aggiuntivo allo standard input, in modo da facilitare l'elaborazione dei dati dopo complesse operazioni di reindirizzamento.
FIXME: Completare.
Un Here document (Nel seguito sarà abbreviato con HD, che non sta per hard disk!) è un tipo particolare di reindirizzamento dell'I/O che consente alla shell di leggere delle righe di testo fino ad una parola delimitatrice e trasformarle in standard input di un comando.
La sintassi di questa speciale caratteristica è la seguente:
comando <<[-]PAROLA ... (CORPO dell'HD) ... DELIMITATORESu PAROLA non viene fatta alcun tipo di espansione, l'unica cosa da tenere a mente è il fatto che, qualora contenesse un qualsiasi carattere quotato (catattere preceduto da un backslash,
Il ``-'' facoltativo serve a rendere più
``graziosa'' la vista di un HD, in questo modo, infatti, le
righe possono essere indentate rispeto all'inizio di una riga di un
carattere TAB, la sinstassi pertanto diverrebbe:
comando <<-PAROLA
...
(CORPO dell'HD)
...
DELIMITATORE
Ciò è possibile poiché l'operatore di redirezione «-
istruisce la shell a rimuovere tutti i caratteri TAB che
precedono le righe dell'HD e del DELIMITATORE.
Vediamo come applicare quanto appreso con un esempio che fa uso di
alcuni semplici comandi previsti dal protocollo SMTP
(Simple Mail Transfer
Protocol) e del comando nc (netcat).
#!/bin/bash
#
# Spedire e-mail con uno shell script
EXIT_SUCCESS=0
EXIT_FAILURE=1
# indirizzo del server di posta
SMTP_SERVER="localhost"
# percorso completo dell'eseguibile di nc
NC="$(which nc)"
# indirizzo del mittente
MITTENTE="nico@localhost"
utilizzo () {
echo "$(basename $0) <destinatario> \"<testo>\" \"<oggetto>\""
exit $EXIT_FAILURE
}
if [ $# -ne 3 ]; then
utilizzo
fi
DESTINATARIO=$1
TESTO=$2
OGGETTO=$3
$NC -w 5 "$SMTP_SERVER" "25" &> /dev/null <<EOF
HELO $(hostname)
MAIL FROM: <$MITTENTE>
RCPT TO: <$DESTINATARIO>
DATA
Subject: $OGGETTO
To: $DESTINATARIO
From: $MITTENTE
$TESTO
.
EOF
exit $EXIT_SUCCESS
Innanzitutto, vediamo come lanciare lo script.
[nico@deepcool nico]$ ./mail.sh nico@deepcool "ecco una e-mail inviata > con uno shell script" "e-mail con shell script" [nico@deepcool nico]$Come mostrato nella funzione utilizzo(), lo script richiede tre parametri per essere eseguito correttamente, rispettivamente: indirizzo e-mail del destinatario, breve testo racchiuso tra virgolette in modo da poterlo estendere su più linee, oggetto della e-mail, anch'esso racchiuso tra virgolette.
Passiamo ad analizzare il codice. Oltre alle solite variabili per
definire i valori di ritorno, notiamo subito la presenza di alcune
variabili per ``configurare'' lo script: $SMTP_SERVER, $NC
e $MITTENTE. Il significato di queste variabili è,
rispettivamente: indirizzo del server smtp da utilizzare, percorso
completo dell'eseguibile di netcat (tramite l'utility
which) e indirizzo e-mail del mittente.
Successvamente, lo script memorizza i parametri posizionali forniti
con $1, $2 e $3 nelle variabili $DESTINATARIO,
$TESTO e $OGGETTO per maneggiarli più comodamente. Arrivati
a questo punto, iniziano le novità. La riga
![]() identifica un HD in
cui tutte le righe comprese tra
identifica un HD in
cui tutte le righe comprese tra
![]() ed
ed
![]() sono
trasformate in standard input del comando
sono
trasformate in standard input del comando
![]() .
.
Le righe dell'HD sono comandi standard del protocollo
SMTP4.3; in particolare, la riga
![]() è una stringa di ``presentazione'' che
invia al server di posta il nostro hostname, ottenuto tramite il
comando hostname.
è una stringa di ``presentazione'' che
invia al server di posta il nostro hostname, ottenuto tramite il
comando hostname.
Nella sezione precedente abbiamo analizzato un semplice script che ci consentiva di inviare e-mail. Lo script aveva il difetto di dover esser lanciato con una sintassi molto rigida, infatti occorreva richiamarlo fornendo esattamente tre parametri in un ben preciso ordine. Questa restrizione fastidiosa e limitativa potrebbe essere evitata se si potessero usare le opzioni come nei programmi compilati (Ad esempio ls, rm, tar e molti molti altri).
Ancora una volta, Bash ci viene in aiuto (Anche altre shell
lo fanno), mettendoci a disposizione il comando interno
getopts.
Andiamo con ordine ed introduciamo alcune peculirità; utilizzando
getopts all'interno di uno script, vengono implicitamente
create le variabili $OPTIND (L'indice dell'argomento in esame,
che non viene reimpostato automaticamente) e $OPTARG (il
contenuto del facoltativo argomento di un'opzione). Vediamo ora un
quadro che riassume la sintassi del comando:
getopts STRINGA_DELLE_OPZIONI NOMESTRINGA_DELLE_OPZIONI rappresenta la sequenza di opzioni che il nostro script deve avere; ad esempio, se volessimo fornire allo script le opzioni -a, -b e -c, la seguenza sarebbe
NOME, invece, rappresenta la variabile in cui salvare la
lettera dell'opzione in esame. Qualora getopts incontrasse
un'opzione non presente in STRINGA_DELLE_OPZIONI,
inserirebbe in NOME il carattere
![]() .
.
Dovrebbe esser ormai chiaro che getopts analizza le opzioni
una alla volta, dunque per analizzare i valori passati occorre
utilizzarla insieme con un ciclo. Tra quelli studiati nella sezione
3.1, il ciclo while è senz'altro il più indicato.
Non finisce qui! A seconda dell'opzione esaminata occorre prendere
decisioni differenti, quindi dobbiamo effettuare una selezione, in
questo caso, case è l'istruzione più appropriata. Vediamo
dunque come combinare le cose nel caso:
...
while getopts ":ab:c" OPZIONE; do
case $OPZIONE in
a)
fai_qualcosa_con_a
;;
b)
VARIABILE_PER_b=$OPTARG
fai_qualcosa_con_b
;;
c)
fai_qualcosa_con_c
;;
?)
echo "Opzione non valida"
;;
*)
echo "C'è stato qualche errore!"
;;
esac
done
shift $(( $OPTIND - 1 ))
Vediamo dunque come modificare l'esempio della sezione precedente in
modo da renderlo più utilizzabile.
#!/bin/bash
#
# Spedire e-mail con uno shell script (2)
EXIT_SUCCESS=0
EXIT_FAILURE=1
# indirizzo del server di posta
SMTP_SERVER="localhost"
# percorso completo dell'eseguibile di nc
NC="$(which nc)"
# l'indirizzo del mittente
MITTENTE="nico@localhost"
utilizzo () {
echo "$(basename $0) -d <destinatario> -t <testo> -o <oggetto>"
exit $EXIT_FAILURE
}
while getopts ":d:t:o:" OPZIONE; do
case $OPZIONE in
d)
DESTINATARIO=$OPTARG
;;
t)
TESTO=$OPTARG
;;
o)
OGGETTO=$OPTARG
;;
*)
utilizzo
;;
esac
done
shift $(( $OPTIND - 1 ))
if [ -z "$DESTINATARIO" -o -z "$TESTO" -o -z "$OGGETTO" ]; then
utilizzo
fi
$NC -w 5 "$SMTP_SERVER" "25" &> /dev/null <<EOF
HELO $(hostname)
MAIL FROM: <$MITTENTE>
RCPT TO: <$DESTINATARIO>
DATA
Subject: $OGGETTO
To: $DESTINATARIO
From: $MITTENTE
$TESTO
.
EOF
exit $EXIT_SUCCESS
L'unica novità rispetto alla precedente versione è, come era da
aspettarsi, la presenza di getopts. Abbiamo passato a
getopts la stringa
![]() , in questo modo, grazie
al : iniziale abbiamo soppresso ogni messaggio di errore,
inoltre abbiamo istruito il comando ad analizzare i parametri
posizionali alla ricerca delle opzioni -d (destinatario),
-t (testo) e -o (oggetto), ognuna delle quali
necessita di un argomento. Attraverso l'istruzione case
assegnamo l'argomento di una opzione ad una specifica variabile, in
modo da poterlo riutilizzare; inoltre, dato che non ci interessa
essere molto specifici riguardo ad un eventuale errore, abbiamo
tralasciato il caso ?), dato che questo può essere inglobato
in quello di default *).
, in questo modo, grazie
al : iniziale abbiamo soppresso ogni messaggio di errore,
inoltre abbiamo istruito il comando ad analizzare i parametri
posizionali alla ricerca delle opzioni -d (destinatario),
-t (testo) e -o (oggetto), ognuna delle quali
necessita di un argomento. Attraverso l'istruzione case
assegnamo l'argomento di una opzione ad una specifica variabile, in
modo da poterlo riutilizzare; inoltre, dato che non ci interessa
essere molto specifici riguardo ad un eventuale errore, abbiamo
tralasciato il caso ?), dato che questo può essere inglobato
in quello di default *).
Alle volte potrebbe rendersi necessario includere in uno script del
testo presente in un altro file; questo testo potrebbe essere del
codice e quindi dovrebbe anche essere interpretato correttamente dalla
shell. La questione può essere risolta facilmente utilizzando il
comando interno
![]() o
o
![]() .
.
Un tale tipo di inclusione può essere necessario qualora decidessimo
di dotare un nostro script di un file di configurazione. Ad esempio
nell'esempio precedente esistono delle variabili dipendenti dal
calcolatore su cui viene eseguito, sarebbe auspicabile, dunque, avere
un sistema per spiegare allo script, ad esempio, quale server di posta
utilizzare, oppure quale argomento passare al comando SMTP
HELO.
Vediamo come affrontare questa evenienza.
# Questo è un commento # server SMTP da utilizzare SMTP_SERVER="il_mio_server_di_posta" # HELO da utilizzare # Modificare a seconda delle esigenze HELO="il_mio_host" # fine di /etc/bash_mail.conf
Potremmo anche consentire ad ogni singolo utente di modificare i
paramentri di configurazione dello script; per fare ciò, prevediamo
anche l'esistenza di un file
![]()
# File di configurazione per utente # server SMTP da utilizzare # SMTP_SERVER="un_altro_server" # HELO da utilizzare # Modificare a seconda delle esigenze # HELO="un_altro_helo" # Indirizzo del mittente MITTENTE="Domenico Delle Side <nicodds@Tiscali.IT>" # fine di $HOME/.bash_mail.conf
Ora riprendiamo l'esempio e modifichiamolo in modo da utilizzare i
file di configurazione appena scritti.
#!/bin/bash
#
# Spedire e-mail con uno shell script (3)
EXIT_SUCCESS=0
EXIT_FAILURE=1
NC=$(which nc)
if [ -f "/etc/bash_mail.conf" ]; then
. /etc/bash_mail.conf
# oppure
# source /etc/bash_mail.conf
else
SMTP_SERVER="localhost"
HELO=$HOSTNAME
fi
if [ -f "$HOME/.bash_mail.conf" ]; then
. $HOME/.bash_mail.conf
else
MITTENTE="<${USER}@${HOSTNAME}>"
fi
utilizzo () {
echo "$(basename $0) -d <destinatario> -t <testo> -o <oggetto>"
exit $EXIT_FAILURE
}
while getopts ":d:t:o:" OPZIONE; do
case $OPZIONE in
d)
DESTINATARIO=$OPTARG
;;
t)
TESTO=$OPTARG
;;
o)
OGGETTO=$OPTARG
;;
*)
utilizzo
;;
esac
done
shift $(( $OPTIND - 1 ))
if [ -z "$DESTINATARIO" -o -z "$TESTO" -o -z "$OGGETTO" ]; then
utilizzo
fi
$NC -w 5 "$SMTP_SERVER" "25" &> /dev/null <<EOF
HELO $HELO
MAIL FROM: $MITTENTE
RCPT TO: <$DESTINATARIO>
DATA
Subject: $OGGETTO
To: $DESTINATARIO
From: $MITTENTE
$TESTO
.
EOF
exit $EXIT_SUCCESS
Successivamente viene verificata la presenza del file di
configurazione dell'utente che lancia lo script,
![]() ($HOME viene espansa dalla shell
nella home directory dell'utente che esegue lo script). Qualora il
file fosse presente, ne sarebbe incluso il contenuto, in questo modo
le variabili generiche eventualmente impostate con l'inclusione
precedente verrebbero reimpostate ai valori presenti nel file
dell'utente. Se invece il file fosse assente, lo script si limiterebbe
ad impostare la variabile $MITTENTE.
($HOME viene espansa dalla shell
nella home directory dell'utente che esegue lo script). Qualora il
file fosse presente, ne sarebbe incluso il contenuto, in questo modo
le variabili generiche eventualmente impostate con l'inclusione
precedente verrebbero reimpostate ai valori presenti nel file
dell'utente. Se invece il file fosse assente, lo script si limiterebbe
ad impostare la variabile $MITTENTE.
Per il resto, lo script è analogo all'esempio della sezione
precendente.
trap è un comando interno alla shell che consente di definire un comando da eseguire allorché lo script in esecuzione riceva un segnale.
In breve, un segnale è un evento generato da un sistema
Unix al verificarsi di una particolare condizione. Un segnale
è in genere utilizzato dal sistema operativo per dialogare con i
processi; un processo che riceve un segnale, ad esempio, può a sua
volta decidere un'azione da intraprendere.
Ritorniamo a trap e analizziamone la sintassi:
trap [-lp] [AZIONE] [SEGNALE]Procediamo con ordine, le opzioni facoltative (-l, -p) fanno agire trap in maniera particolare; l'opzione -l viene passata da sola a trap e consente di ottenere la lista di tutti i segnali supportati, -p, invece, consente di vedere le azioni associate ad ogni segnale, o, qualora fossero specificati dei segnali, solo quelle associate a questi. Ad esempio, il comando trap -l ci fornisce il risultato:
[nico@deepcool nico]$ trap -l 1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR 31) SIGSYS 32) SIGRTMIN 33) SIGRTMIN+1 34) SIGRTMIN+2 35) SIGRTMIN+3 36) SIGRTMIN+4 37) SIGRTMIN+5 38) SIGRTMIN+6 39) SIGRTMIN+7 40) SIGRTMIN+8 41) SIGRTMIN+9 42) SIGRTMIN+10 43) SIGRTMIN+11 44) SIGRTMIN+12 45) SIGRTMIN+13 46) SIGRTMIN+14 47) SIGRTMIN+15 48) SIGRTMAX-15 49) SIGRTMAX-14 50) SIGRTMAX-13 51) SIGRTMAX-12 52) SIGRTMAX-11 53) SIGRTMAX-10 54) SIGRTMAX-9 55) SIGRTMAX-8 56) SIGRTMAX-7 57) SIGRTMAX-6 58) SIGRTMAX-5 59) SIGRTMAX-4 60) SIGRTMAX-3 61) SIGRTMAX-2 62) SIGRTMAX-1 63) SIGRTMAXIl parametro AZIONE (anch'esso opzionale) serve a specificare, come chiarisce il nome stesso, l'azione da intraprendere al ricevere del segnale SEGNALE (opzionale), in genere questa è una lista di comandi da eseguire. Il segnale SEGNALE può essere specificato sia tramite una delle costanti simboliche definite in <signal.h>4.5, sia attraverso il numero che identifica il segnale. In tabella 4.1 è presente una breve lista di segnali standard.
Ad esempio, se volessimo far sì che nel nostro terminale venga
stampato un messaggio ogni volta che si riceva un segnale di
interrupt, basterebbe scrivere:
trap 'echo -e "\nQuesto un messaggio impostato con trap (SIGINT)"' SIGINTDopo averlo eseguito, infatti, ad ogni pressione della combinazione di tasti CTRL-C otteniamo il messaggio scritto:
[nico@deepcool nico]$ trap 'echo -e "\nQuesto un messaggio impostato > con trap (SIGINT)"' SIGINT [nico@deepcool nico]$ (CTRL-C) Questo un messaggio impostato con trap (SIGINT) [nico@deepcool nico]$ (CTRL-C) Questo un messaggio impostato con trap (SIGINT) [nico@deepcool nico]$ (CTRL-C) Questo un messaggio impostato con trap (SIGINT) [nico@deepcool nico]$ (CTRL-C) Questo un messaggio impostato con trap (SIGINT)Se ora volessimo tornare alla situzione iniziale, basterebbe digitare il comando:
trap SIGINTCiò riporterebbe l'azione da intraprendere al ricevimento di un interrupt al default della shell.
#!/bin/bash
#
# Uso di trap
EXIT_SUCCESS=0
TMPFILE=$HOME/.tmpfile.$$
trap 'rm -f $TMPFILE' SIGINT
echo "Creo il file $TMPFILE..."
touch $TMPFILE
echo "Premi CRTL-C per uscire"
while [ -f $TMPFILE ]; do
echo "$TMPFILE esiste ancora"
sleep 1;
done
echo "$TMPFILE non esiste più"
exit $EXIT_SUCCESS
All'inizio dello script definiamo la variabile $TMPFILE e
definiamo un azione da compiere su questo al ricevere di un segnale di
interrupt:
![]() . Successivamente, dopo
alcuni messaggi di cortesia, creiamo il file temporaneo $TMPFILE
con l'utility touch ed entriamo in un
ciclo nel quale la condizione è data da
. Successivamente, dopo
alcuni messaggi di cortesia, creiamo il file temporaneo $TMPFILE
con l'utility touch ed entriamo in un
ciclo nel quale la condizione è data da
![]() . Ad ogni
iterazione del ciclo viene stampato un messaggio che conferma
l'esistenza del file temporaneo e si manda in pausa per 1 secondo
l'esecuzione dello script grazie al comando
sleep.
. Ad ogni
iterazione del ciclo viene stampato un messaggio che conferma
l'esistenza del file temporaneo e si manda in pausa per 1 secondo
l'esecuzione dello script grazie al comando
sleep.
Alla pressione della combinazione di tasti CTRL-C, il file temporaneo
verrà cancellato, dunque la condizione valutata dal ciclo
while sarà falsa, causandone la fine. Lo script termina
stampando un ulteriore messaggio e ritornando alla shell il valore
$EXIT_SUCCESS.
|
|
| Introduzione allo Shell Scripting |
|
|
![\includegraphics[]{fig/array}](img34.png)
![\includegraphics[]{fig/here}](img49.png)