Si è già accennato al fatto che la
valutazione Prolog avviene sulla base della cosiddetta interpretazione
procedurale. In base ad essa ogni termine viene eseguito come se fosse
una procedura. I suoi argomenti costituiscono i parametri attuali della
chiamata e l'unificazione rappresenta il meccanismo di passaggio dei parametri
(legame tra i parametri formali ed i parametri attuali), i quali possono
essere sia di ingresso che di uscita.
La realizzazione dell'interprete ha richiesto l'implementazione
di:
L'EngineSexpVisitor realizza il motore d'inferenza Prolog. Questo ha il compito di dirigere la computazione tenendo traccia delle clausole dimostrate e di quelle da dimostrare. Inoltre deve salvare i vari punti di scelta che via via si accumulano durante l'esplorazione dell'albero di ricerca SLD. L'esplorazione avviene con strategia di ricerca depth-first (nell'insieme delle clausole ordinate in base all'ordine di definizione e cioè testualmente) e regola di computazione left-most con backtracking cronologico. Il compito più significativo è la gestione dei record di attivazione e dei punti di scelta. I record di attivazione sono quelli delle chiamate a procedura corrispondenti alla valutazione di ciascun termine (interpretazione procedurale). La gestione dei record di attivazione può avvenire con uno stack. Anche per i punti di scelta è opportuno usare uno stack per poter gestire adeguatamente il meccanismo di backtracking. Allora una possibile soluzione è quella di usare due stack. Un'altra soluzione prevede invece l'utilizzo di un solo stack (stack di esecuzione) contenente sia i record di attivazione che i punti di scelta. In questo caso sono necessari due puntatori allo stack:
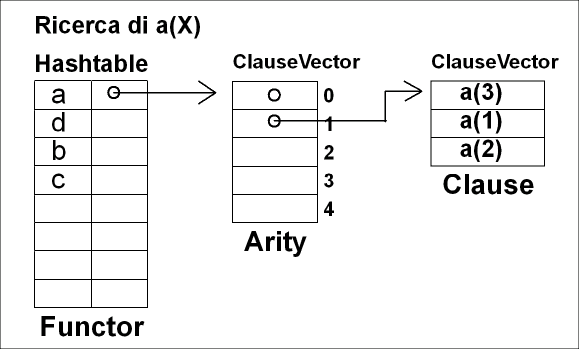
Il database di clausole è costruito sfruttando una Hashtable in cui sono memorizzati tutti i funtori. Per ogni funtore abbiamo varie liste (ClauseVector) ognuna contenente le clausole con funtore ed arity prefissate. Per collegare l'Hashtable alle liste si ha una lista intermedia di puntatori corrispondente ognuno ad una certa arity. La figura seguente dovrebbe chiarire meglio il tutto.
Il RenameVisitor è un Visitor creato per effettuare il renaming. Il renaming consiste nel rinominare le variabili Prolog di ciascuna clausola. Ciò è necessario in quanto ogni variabile Prolog ha scope limitato alla clausola in cui compare. Quindi quando si utilizza una qualunque clausola, per esempio accedendo al DataBase Prolog, bisogna per prima prima cosa sostituire tutte gli oggetti che costituiscono le variabili di quella clausola con nuovi oggetti corrispondenti ai preesistenti ma diversi da questi. Gli oggetti "variabili" sono trattati in funzione della loro identità e quindi se non si fa renaming si possono introdurre delle unificazioni che non dovrebbero esserci. Vediamo un esempio per chiarire il concetto:
DataBase -> cl1) p(X) :- X>0. cl1) q :- p(1),p(2). con query: ?- q.In questo esempio allorché si effettua la valutazione di p(1) (nel body della clausola cl2)) si accede al DataBase unificando con la clausola cl1) e quindi si provoca l'unificazione (l'argomento unificazione verrà ripreso più avanti) della variabile X con il valore 1. Se si è utilizzata la clausola cl1) senza effettuare renaming allora ad aver unificato con 1 è l'oggetto unico X, con la conseguenza che la successiva valutazione di p(2) fallisce perché l'oggetto X è già legato alla costante 1 e quindi non può più unificare con la costante 2! Ciò non è assolutamente corretto. Quindi è necessario che ogni qualvolta si accede al database per reperire la clausola cl1) la variabile X, che compare in essa, corrisponda ogni volta ad un oggetto diverso. Il renaming fa proprio questo: al primo accesso al DB viene restituita la clausola p(X) :- X>0, di essa si fa il renaming ottenendo la clausola p(X1) :- X1>0. in cui la variabile X1 è un oggetto diverso dall'oggetto X. Ad unificare con 1 è X1 e non X. Al secondo accesso si fa la stessa cosa ottenendo alla fine la clausola p(X2) :- X2>0. in cui X2 è diversa sia da X che da X1 e può quindi unificare con 2 poiché è una variabile libera. Alla fine l'interprete può concludere con successo avendo effettuato le unificazioni di X1 con 1 e di X2 con 2.
La classe Unifier implementa un algoritmo
di unificazione.
L'unificazione è "un procedimento
di manipolazione formale che stabilisce se due espressioni coincidono tramite
opportune sostituzioni". La seguente tabella riassume tutti i casi in cui
due espressioni unificano (SI) indicando le relative sostituzioni, oppure
non unificano (NO):
| <costante> C2 | <variabile> X2 | <termine composto> S2 | |
| <costante> C1 | SI se C1=C2 | SI
{X2/C1} |
NO |
| <variabile> X1 | SI
{X1/C2} |
SI
{X1/X2} |
SI
{X1/S2} |
| <termine composto> S1 | NO | SI
{X2/S1} |
SI se S1 ed S2 hanno stesso funtore e arità e gli argomenti unificano |
L'unificazione deve produrre una tabella di sostituzioni,
ovvero una associazione tra variabili e valori, in quali possono essere
a loro volta costanti, termini o variabili.
È necessario organizzare attentamente la
tabella delle sostituzioni per accedere velocemente al valore di una variabile.
Basti pensare che se unifico X con Y, poi successivamente unifico Y con
un termine, anche X deve essere legato allo stesso termine e viceversa.
Per realizzare ciò abbiamo usato il metodo
reference-dereference. Unificando due variabili unbound viene inserito
una sola sostituzione (o riferimento), per esempio X -> Y. Quando
successivamente devo unificare una di queste due variabili con qualcos'altro,
dereferenzio la variabile seguendo ricorsivamente la catena di riferimenti
fino a trovare una variabile unbound od un termine. Continuando l'esempio
precedente,
sia se devo unificare X con term che Y con term, la nuova sostituzione
prodotta è comunque Y -> term. In questo modo si semplifica
la creazione e l'utilizzo della tabella delle sostituzioni.
È possibile anche scegliere se effettuare
l'Occur Check, ovvero il controllo dei riferimenti circolari. Grazie
al metodo reference-dereference il calo delle prestazioni dovute all'introduzione
dell'Occur Check non risulta visibile.
Si è introdotta anche la possibilità di utilizzare le variabili come meta-variabili, cioè come un goal nel corpo di una clausola. Questo avviene semplicemente dereferenziando la variabile ed avviando la risoluzione sul risultato. Se il risultato è una variabile unbound viene genereato un errore di instanziazione.
A conclusione di questa sezione elenchiamo tutti gli operatori ed i termini predefiniti che sono stati implementati nell'interprete.
Gli operatori predefiniti sono riassunti dalla seguente
tabella:
|
|
|
|
|
|
|
|
|
separa antecedente e conseguente di una clausola |
|
|
|
fx | costruisce una query con risolvente dato dal suo argomento |
|
|
|
xfy | operatore or |
|
|
|
xfy | operatore and |
|
|
|
fy | operatore not: avvia una risoluzione SLDNF |
|
|
|
|
operatore di unificazione |
|
|
|
|
operatore di assegnamento di un'espressione aritmetica ad una variabile |
|
|
|
|
consente di trasformare un termine nella lista delle sue componenti |
|
|
|
|
operatore di uguaglianza fra oggetti |
|
|
|
|
operatore di disuguaglianza fra oggetti |
|
|
|
|
operatore di confronto di uguaglianza aritmetica |
|
|
|
|
operatore di confronto di disuguaglianza aritmetica |
|
|
|
|
operatore di confronto aritmetico "minore" |
|
|
|
|
operatore di confronto aritmetico "maggiore" |
|
|
|
|
operatore di confronto aritmetico "uguale o minore" |
|
|
|
|
operatore di confronto aritmetico "maggiore o uguale" |
|
|
|
|
operatore aritmetico di somma (binario) |
|
|
|
|
operatore aritmetico di sottrazione (binario) |
|
|
|
|
operatore aritmetico di somma (unario) |
|
|
|
|
operatore aritmetico di sottrazione (unario) |
|
|
|
|
operatore aritmetico di moltiplicazione |
|
|
|
|
operatore aritmetico di divisione |
|
|
|
|
operatore aritmetico di elevamento a potenza |
I termini predefiniti sono riassunti dalla seguente
tabella:
| Funtore/arità | Note |
| atom/1 | atom(T): T è un atomo non numerico |
| atomic/1 | atomic(T): T è un atomo oppure un numero (ossia T non è una struttura composta) |
| number/1 | number(T): T è un numero intero o reale |
| integer/1 | integer(T): T è un numero intero |
| var/1 | var(T): T è una variabile non istanziata |
| nonvar/1 | var(T): T non è una variabile non istanziata |
| compound/1 | compound(T): T è un termine composto |
| functor/3 | functor(T,F,N): il termine T ha come funtore principale F e come numero di argomenti N |
| arg/3 | arg(N,T,A): A è l'argomento in posizione N del termine T |
| clause/2 | clause(H,B): " ':-'(H,B) " è una clausola contenuta nel DataBase Prolog |
| assert/1 | assert(T): la clausola T viene aggiunta al DataBase (in fondo) |
| asserta/1 | asserta(T): la clausola T viene aggiunta all'inizio del DataBase |
| retract/1 | retract(T): la prima clausola nel DataBase unificabile con T viene rimossa |
| retractall/1 | retractall(T): tutte le clausole nel DataBase unificabili con T vengono rimosse |
| ground/1 | ground(T): T non è una variabile unbound oppure è un termine composto che non contiene variabili unbound |
| call/1 | call(T): T è il nuovo goal;
rende disponibile all'utente la funzione di valutazione Prolog |
| listing/1 | listing(T): stampa sullo standard output il contenuto del database relativo a Term, se Term è un atomo stampa tutte le clausole con testa uguale a Term. |
| random/3 | random(Min,Max,V): unifica a V un numero random compreso fra Min e Max |
| write/1 | write(T): stampa T sullo standard output |
| read/1 | read(T): t viene unificato con il termine letto da standard input |
| "Consultare un file" | [X]: X è il nome di un file che viene consultato |
| nl | stampa sullo standard output un "new line" |
| fail | provoca il fallimento dell'interprete |
| true | ha sempre successo |
| ! | è il cut: provoca una "potatura" dell'albero di ricerca |