Next: L'architettura di rete Up: La codifica video Previous: MPEG Contents Index
L'obiettivo perseguito nel progetto di questo codec [2] è stato quello di realizzare un algoritmo di codifica e decodifica video accessibile alla platea più ampia ed eterogenea possibile di utenti. Questo significa che l'algoritmo deve risentire il meno possibile delle eventuali limitazioni che caratterizzano il singolo utente, sia in termini di capacità del canale che di potenza di calcolo.
Deve essere permesso l'accesso tanto sui canali a banda larga quali ad esempio le reti ATM o le reti locali, quanto sulle reti a banda più limitata come ad esempio le reti geografiche. Questo è reso possibile dall'implementazione di tecniche di codifica scalabile; realizzando un bit-stream embedded, infatti ogni utente potrà scegliere i livelli da ricevere in accordo con la capacità della propria rete di accesso.
Si desidera inoltre rendere possibile in tempo reale tanto la decodifica che la codifica anche su terminali con limitata potenza di calcolo. L'algoritmo quindi è simmetrico, ed una particolare attenzione è stata posta nello scegliere tecniche di codifica che avessero un bassa complessità computazionale.
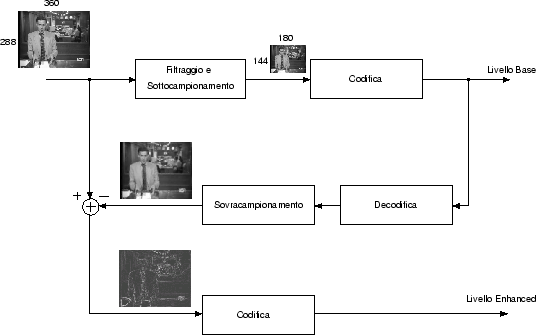
Per realizzare una codifica scalabile in risoluzione spaziale è stata scelta la tecnica della codifica piramidale laplaciana.
Tramite un serie di filtraggi e decimazioni ci si riconduce ad una sequenza
di immagini delle dimensioni di
180×144 pixel, questa viene codificata
e trasmessa, e rappresenta quello che chiameremo livello base.
Tale livello viene quindi decodificato (in modo da ottenere la stessa sequenza
che si ha in ricezione) e sovracampionato ottenendo in questo modo una sequenza
di immagini delle dimensioni di
360×288 pixel. Queste immagini
vengono confrontate con quelle della sequenza originale e viene codificata e
trasmessa la differenza tra le due sequenze, ottenendo in questo modo il livello
enhanced. In questo modo, in ricezione sarà possibile
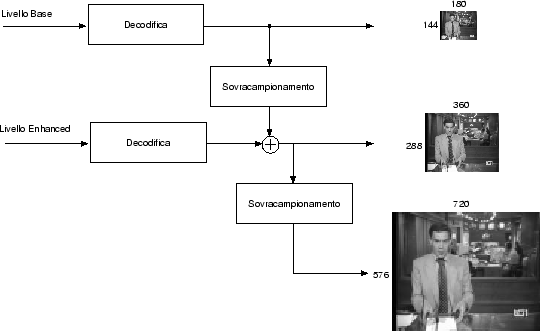
scegliere ad esempio di ricevere il solo livello base, oppure si potrà ricevere
anche il livello enhanced, nel qual caso la sequenza di livello base andrà decodificata
sovracampionata e sommata alla sequenza di livello enhanced decodificata. In
aggiunta è possibile ottenere in ricezione immagini delle dimensioni di
720×576
pixel, semplicemente sovracampionando e interpolando le immagini di livello
enhanced. In figura ![[*]](crossref.png) sono mostrati
gli schemi di principio per la codifica e la decodifica.
sono mostrati
gli schemi di principio per la codifica e la decodifica.
Riassumendo, in ricezione sono disponibili le tre seguenti risoluzioni spaziali:
É chiaro che quante più frame al secondo trasmettiamo tanto più fluida sarà la sequenza, ma allo stesso tempo tanto maggiore sarà il tasso trasmissivo. Inoltre al crescere del frame rate devono crescere di pari passo le prestazioni del codificatore e del decodificatore, infatti se ad esempio il frame rate è di 10 frame/s avremo a disposizione per la codifica/decodifica della singola frame 1/10 = 0, 1 secondi mentre se il frame rate è di 25 frame/s avremo a disposizione 1/25 = 0, 04 secondi.
Per garantire la scalabilità temporale si ricorre
ad una suddivisione delle frame in 3 livelli temporali. Nel primo livello viene
trasmessa una frame ogni 4 quattro, quindi possiamo dire che vengono trasmesse
tutte le frame con indice 4*n con n intero. Nel secondo livello
temporale invece viene ancora trasmessa una frame ogni quattro, ma in questo
caso si trasmettono le frame con indice 4*n + 2, infine nel terzo livello
temporale vengono trasmesse le frame con indice 4*n + 1 e 4*n + 3,
quindi una ogni due. In figura è mostrata
la suddivisione in flussi temporali.
Combinando questi livelli temporali è possibile ottenere 3 diversi frame rate.
indicano appunto le dipendenze
per il CR. Ciò evidenzia anche che l'unico flusso indipendente (che cioè può
essere decodificato senza ricevere i restanti flussi) è il primo, mentre il
secondo flusso richiede il primo, e il terzo li richiede entrambi.
A causa di queste dipendenze, l'ordine con il quale vengono codificate le frame è diverso da quello con il quale vengono acquisite, infatti all'uscita del codificatore avremo una sequenza di questo tipo: 0 4 2 1 3 8 6 5 7 12... . Questo introduce dei piccoli ritardi sia in fase di codifica che di decodifica, in quanto è necessario riordinare le frame.
Con la scalabilità in precisione (anche detta scalabilità in SNR) è possibile agire sul trade-off esistente tra qualità della ricostruzione e tasso trasmissivo. Per poterne illustrare il funzionamento è necessario scendere più in dettaglio nella descrizione delle tecniche di codifica.
Come algoritmo di compressione si è optato per la quantizzazione vettoriale tabellare con struttura gerarchica. La quantizzazione vettoriale tabellare consente la codifica semplicemente accedendo ad una tabella, in questa tabella si entra con il blocco di pixel da quantizzare e si ricava l'indice della codeword che quantizza quel blocco. La creazione della tabella viene fatta off-line una volta per tutte, e permette ad esempio di utilizzare metriche anche sofisticate (tenendo conto ad esempio della percezione visiva) nella valutazione della distorsione. Tuttavia non è pensabile utilizzare un'unica tabella, perché questa dovrebbe avere dimensioni estremamente grandi, per questo motivo si organizza una gerarchia di tabelle più piccole.
Per ottenere la scalabilità in precisione si ricorre alla tecnica chiamata TSVQ (Tree Structured Vector Quantization), in pratica le parole codice sono organizzate in una struttura ad albero, è possibile quindi utilizzare un prefisso qualunque degli indici completi, riducendo in questo modo il tasso (ma anche la qualità ovviamente).
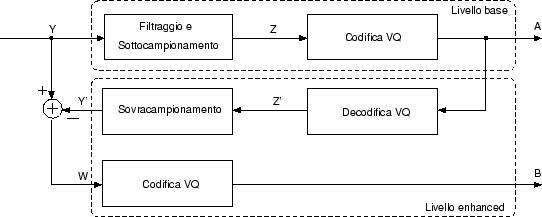
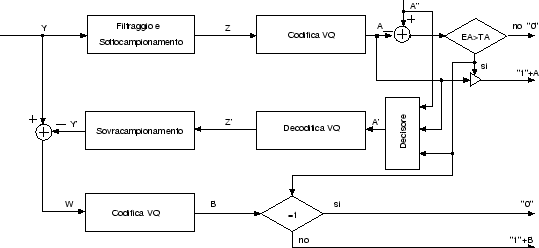
Nei paragrafi precedenti sono state introdotte per sommi capi le tecniche utilizzate in questo codec, in questo paragrafo verrà invece mostrato più in dettaglio il suo funzionamento, analizzando gli schemi di codifica e decodifica intra/inter-frame.
In tabella viene illustrato il significato
dei simboli usati negli schemi.
|
vengono mostrati gli schemi del codificatore
e del decodificatore intraframe.
Come vediamo otteniamo due flussi codificati, quello dei vettori A corrisponde agli indici delle codeword che codificano le immagini di livello di base, mentre i vettori di tipo B contengono gli indici delle codeword che codificano il livello enhanced (differenza tra l'immagine di livello base sovracampionata e quella originale a 360×288 pixel).
La quantizzazione vettoriale opera su blocchi di 2×4 pixel (ogni pixel è rappresentato da un byte) e produce indici da 1 byte (codebook da 256 codeword), per cui per la codifica intra il rapporto di compressione è pari ad 8.
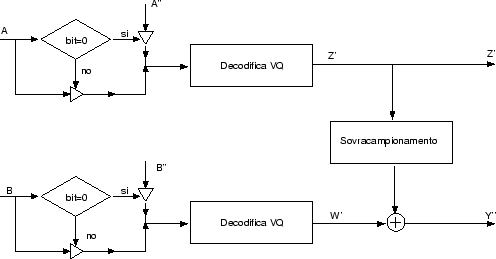
Nel caso della codifica interframe si usa la tecnica del conditional replenishment (CR), con una particolarità, la tecnica viene applicata agli indici (vettori tipo A) e non alle frame vere e proprie. Questo permette di ridurre notevolmente i calcoli in quanto tali vettori hanno dimensioni molto minori rispetto alle frame (bisogna dividere le dimensioni delle frame per il rapporto di compressione), inoltre per ridurre l'overhead dovuto ai bit che segnalano l'esito del CR, questo è applicato a blocchi di dimensioni 3×3 indici, cioè in definitiva, su macroblocchi di 6×12 pixel. Tuttavia è bene precisare che è possibile effettuare il CR sugli indici invece che sui pixel perché i codici sono stati progettati in modo che ad indici vicini corrispondano blocchi molto simili (anche se questo è vero solo localmente), quindi confrontare pixel non è molto diverso che confrontare indici.
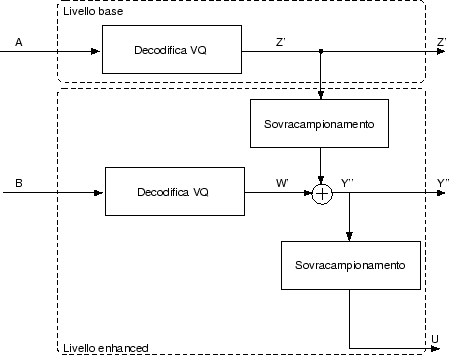
In figura sono mostrati il codificatore ed il decodificatore
interframe nel caso di conditional replenishment unidirezionale (il caso bidirezionale
è del tutto analogo).
Come vediamo dallo schema del codificatore, i blocchi di indici vengono confrontati con quelli di riferimento, se l'energia della differenza supera una certa soglia il blocco viene trasmesso (insieme ad un bit di segnalazione pari ad 1), altrimenti viene trasmesso unicamente un bit di segnalazione pari a 0.
Per quanto riguarda il livello enhanced, solo i blocchi corrispondenti ai blocchi di indici per i quali il CR non ha avuto successo vengono trasmessi, in pratica si ipotizza di poter estendere anche a livello enhanced i risultati del CR effettuato a livello base. Questa scelta permette di avere una complessità computazionale molto ridotta, tuttavia probabilmente avere CR separati sui due livelli produrrebbe risultati di qualità migliore.
Debian User 2003-06-05