L'architettura hardware dei processori Intel 80x86, ed in particolare i registri a 16 bit, implementati anche dai processori 80386 e superiori per compatibilità con quelli di categoria inferiore, impongono che la memoria sia gestita in modo segmentato, esprimendo, cioè, un indirizzo a 20 bit mediante 2 registri a 16 bit, detti registro di segmento e registro di offset. Secondo tale schema sono indirizzati il codice eseguibile (CS:IP), lo stack (SS:SP o SS:BP) e i dati (DS o ES per esprimere il segmento; l'offset può essere contenuto in diversi registri, tra cui BX, DX, SI e DI). L'inizializzazione dei registri della CPU al fine di una corretta esecuzione dei programmi è effettuata dal DOS quando il programma è caricato in memoria per essere eseguito, con regole differenti per i file .EXE e .COM.
Questi ultimi sono eseguiti sempre a partire dal primo byte del file e la loro dimensione non può superare i 64 Kb, all'interno dei quali, peraltro, devono trovare posto anche il PSP, i dati e lo stack[1]. Ne segue che un programma .COM occupa un solo segmento di memoria, e quindi tutti i registri di segmento assumono identico valore. Dette limitazioni[2] sono superate dal formato .EXE, di successiva introduzione, che, grazie ad una tabella posta all'inizio del file (la relocation table) sono in grado di dare istruzioni al DOS circa l'inizializzazione dei registri e quindi, in definitiva, sul modo di gestire gli indirizzamenti di codice, stack e dati[3].
La notevole flessibiltà strutturale consentita dalla tipologia .EXE può essere sfruttata al meglio dichiarando in modo opportuno puntatori e funzioni[4], in modo da lavorare con indirizzi a 16 o 32 bit, a seconda delle necessità. I compilatori C (o almeno la maggior parte di essi) sono in grado, se richiesto tramite apposite opzioni di compilazione, di generare programmi strutturati secondo differenti default di indirizzamento della memoria, "mescolando" secondo diverse modalità gli indirizzamenti a 32 e a 16 bit per codice, dati e stack: ciascuna modalità rappresenta un modello di memoria, cioè un modello standard di indirizzamento della RAM, che viene solitamente individuato dal programmatore in base alle caratteristiche desiderate per il programma.
Date le differenti modalità di gestione degli indrizzi di codice e dati implementate nei diversi modelli di memoria, a ciascuno di questi corrisponde una specifica versione di libreria di funzioni; in altre parole, ogni compilatore è accompagnato da una versione di libreria per ogni modello di memoria supportato. Fa eccezione soltanto il modello tiny, che utilizza la libreria del modello small: in entrambi i modelli, infatti, la gestione degli indirizzamenti è implementata mediante puntatori near tanto per il codice, quanto per i dati[5]. Ne segue che la realizzazione di una libreria di funzioni implica la costruzione di più file .LIB e quindi la compilazione dei sorgenti e l'inserimento dei moduli oggetto nella libreria devono essere effettuate separatamente per ogni modello di memoria: ciò non è richiesto solo per i modelli tiny e small, che possono condividere un'unica libreria.
Di seguito descriviamo brevemente i modelli di memoria generalmente supportati dai compilatori.
E' il modello che consente la creazione di file .COM (oltre ai .EXE). Tutti i registri di segmento (CS, SS, DS ed ES) contengono lo stesso indirizzo, quello del Program Segment Prefix del programma. Quando il programma è un .COM, il registro IP è sempre inizializzato a 100h (256 decimale) e, dal momento che il PSP occupa proprio 256 byte, l'entry point del programma coincide col primo byte del file: i conti tornano.
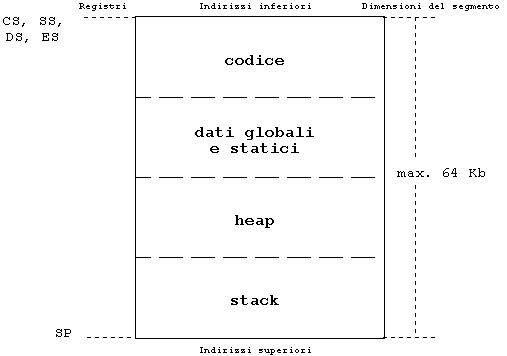
Tanto nei file .COM che nei file .EXE, codice, dati e stack non possono superare i 64 Kb e tutti i puntatori sono, per default, near. La memoria è dunque gestita secondo una "mappa" analoga a quella presentata nella figura 1.
Chi non ricordasse che cosa è lo heap e in che cosa si differenzia dallo stack rilegga il capitolo dedicato all'allocazione dinamica della memoria. Qui vale la pena di sottolineare che dati globali e statici, stack e heap condividono il medesimo segmento di memoria: un utilizzo "pesante" dell'allocazione dinamica della memoria riduce quindi lo spazio disponibile per le variabili locali e per i dati globali, e viceversa.
L'opzione del compilatore Borland che richiede la generazione del modello tiny è mt; se sulla riga di comando del compilatore è presente anche l'opzione lt viene prodotto un file .COM.
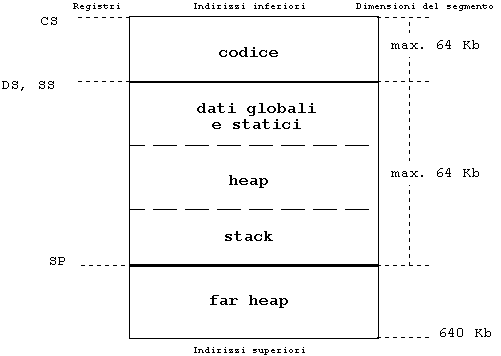
Nel modello small il segmento del codice è separato da quello per i dati. I programmi generati con l'opzione ms (del compilatore Borland, per il quale essa è il default) possono avere fino a 64 Kb di codice eseguibile, ed altri 64 Kb condivisi tra dati statici e globali, heap e stack. Come si vede dalla figura 2, anche nei programmi compilati in modalità small lo spazio utilizzato dai dati globali riduce heap e stack, e viceversa, ma il valore iniziale di DS ed SS non coincide con quello di CS, in quanto viene stabilito in base ai parametri presenti nella relocation table, generata dal linker. E' inoltre disponibile il far heap, nel quale è possibile allocare memoria da gestire mediante puntatori far.
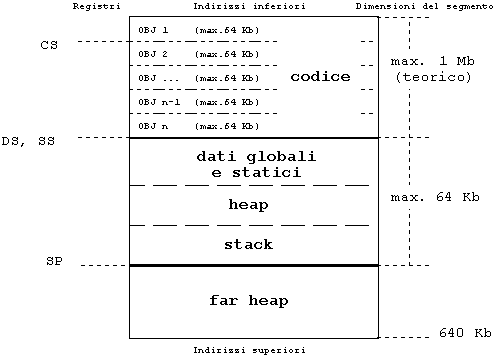
Il modello medium è adatto ai programmi di grosse dimensioni che gestiscono piccole quantità di dati: infatti, i puntatori per il codice sono tutti a 32 bit (le chiamate a funzione sono tutte far), mentre i puntatori per i dati, per default, sono a 16 bit come nel modello small. Analogamente a quest'utlimo, perciò, il modello medium gestisce un segmento di 64 Kb per dati statici e globali, heap e stack separato dagli indirizzi del codice, che può invece raggiungere la dimensione (teorica) di 1 Mb.
Si noti che il codice eseguibile, qualora superi la dimensione di 64 Kb, deve essere "spezzato" in più moduli .OBJ, ognuno dei quali deve essere di dimensioni non superiori ai 64 Kb. La generazione di più moduli oggetto presuppone che il sorgente sia suddiviso in più file, ma è appena il caso di rimarcare che la dimensione di ogni singolo sorgente non ha alcuna importanza: i limiti accennati valgono per il codice già compilato. La figura 3 evidenzia che il registro CS è inizializzato per puntare ad uno dei moduli oggetto.
L'opzione del compilatore Borland che richiede la generazione del modello medium è mm.
Nel modello medium, le funzioni dichiarate esplicitamente near sono richiamabili solo dall'interno dello stesso modulo oggetto nel quale esse sono definite, in quanto una chiamata near, gestita con un indirizzo a soli 16 bit, non può gestire "salti" intersegmento. L'effetto è analogo a quello che si ottiene dichiarando static una funzione, con la differenza che in questo caso la chiamata è ancora far, secondo il default del modello. Una dichiarazione near trae dunque motivazione da sottili considerazioni di efficienza, mentre una static può rispondere esclusivamente a scelte di limitazione logica di visibilità.
Il modello compact può essere considerato il complementare del modello medium, in quanto genera per default chiamate near per le funzioni e indirizzamenti far per i dati: in pratica esso si addice a programmi piccoli, che gestiscono grandi moli di dati. Il codice non può superare i 64 Kb, come nel modello small, mentre per i dati può essere utilizzato fino ad 1 Mb (tale limite è teorico, in quanto ogni programma, in ambiente DOS, si scontra con l'infame "barriera" dei 640 Kb).
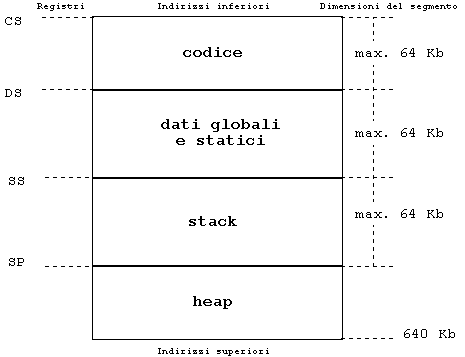
L'opzione (compilatore Borland) che richiede la generazione del programma secondo il modello compact è mc. La figura 4 evidenzia che, a differenza di quanto avviene nei modelli tiny, small e medium, DS e SS sono inizializzati con valori differenti: il programma ha perciò un segmento di 64 Kb dedicato ai dati statici e globali, ed un altro, distinto, per la gestione dello stack. Lo heap (cioè l'area di RAM allocabile dinamicamente) occupa tutta la rimanente memoria disponibile ed è indirizzato per default con puntatori far. Proprio per questa caratteristica esso è definito heap e non far heap, come avviene invece nel modello small, nel quale è necessario dichiarare esplicitamente far i puntatori al far heap e si deve utilizzare farmalloc() per allocarvi memoria.
Il modello large genera per default indirizzamenti far sia al codice che ai dati e si rivela perciò adatto a programmi di notevoli dimensioni che gestiscono grandi quantità di dati. Esso è, in pratica, un ibrido tra i modelli medium (per quanto riguarda la gestione del codice) e compact (per l'indirizzamento dei dati); codice e dati hanno quindi entrambi a disposizione (in teoria) 1 Mb (figura 5).
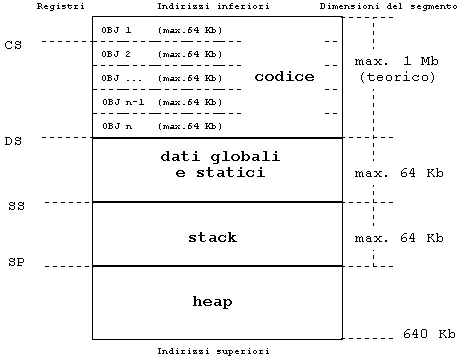
L'opzione (compilatore Borland) per la generazione del modello large è ml.
Il modello large, per le sue caratteristiche di indirizzamento, è probabilmente il più flessibile, anche se non il più efficiente. Le funzioni contenute in una libreria compilata per il modello large[6] possono essere utilizzate senza problemi anche da programmi compilati per altri modelli: è sufficiente ricordarsi che tutti i puntatori parametri delle funzioni sono far e che le funzioni devono essere prototipizzate anch'esse come far: se questi non sono i default del modello di memoria utilizzato occorre agire di conseguenza. Esempio: abbiamo un sorgente, PIPPO.C, da compilare con il modello small, nel quale deve essere inserita una chiamata a funzStr() (che accetta un puntatore a carattere quale parametro e restituisce un puntatore a carattere) disponibile nella libreria LARGELIB.LIB, predisposta per il modello large. Alla libreria è associato uno header file, LARGELIB.H, che contiene il seguente prototipo di funzStr():
char *funz(char *string);
La funzione e i puntatori (il parametro e quello restituito) non sono dichiarati far, perché nel modello large tutti i puntatori e tutte le funzioni lo sono per default. Se non si provvede ad informare il compilatore che, pur essendo il modello di memoria small, funzStr(), i suoi parametri e il valore restituito sono far, si verificano alcuni drammatici problemi: in primo luogo, lo stack è gestito come se entrambi i puntatori fossero near. Ciò significa che a funzStr(), in luogo di un valore a 32 bit, ne viene passato uno a 16; il codice di funzStr(), però, lavora comunque su 32 bit, prelevando dallo stack 16 bit di "ignota provenienza" in luogo della vera parte segmento del puntatore. La funzStr(), inoltre, restituisce un valore a 32 bit utilizzando la coppia di registri DX:AX, ma la funzione chiamante, aspettandosi un puntatore a 16 bit, ne considera solo la parte in AX, cioè l'offset. Ma ancora non basta: la chiamata a funzStr() generata dal compilatore è near, secondo il default del modello small, perciò, a runtime, la CALL salva sullo stack solo il registro IP (e non la coppia CS:IP). Quando funzStr() termina, la RETF (far return) estrae dello stack 32 bit e ricarica con essi la coppia CS:IP; anche in questo caso, 16 di quei 32 bit sono di "ignota provenienza". Ce n'è quanto basta per bloccare la macchina alla prima chiamata. E' indispensabile correre ai ripari, modificando come segue il prototipo in LARGELIB.H
char far * far funzStr(char far *string);
e dichiarando esplicitamente far i puntatori coinvolti nella chiamata a funzStr():
....
char far *parmPtr, far *retPtr;
....
retPtr = funzStr(parmPtr);
....
A dire il vero, si può evitare di dichiarare parmPtr esplicitamente far, perché il compilatore, dall'esame del prototipo, è in grado di stabilire quale tipo di puntatore occorre passare a funzStr() e provvede da sé copiando sullo stack un puntatore far costruito come DS:parmPtr; la dichiarazione far, comunque, non guasta, purché ci si ricordi di avere a che fare con un puntatore a 32 bit anche laddove ciò non è richiesto.
Per facilitare l'uso dei puntatori far nei modelli di memoria tiny, small e medium sono state di recente aggiunte alle librerie standard nuove versioni (adatte a puntatori a 32 bit) di alcune funzioni molto usate: accanto a strcpy() troviamo perciò _fstrcpy(), e così via.
Il modello huge consente di gestire (in teoria) sino ad 1 Mb di dati statici e globali, estendendo ad essi la modalità di indirizzamento implementata dai modelli large e medium per il codice. E' l'unico modello che estende ad 1 Mb il limite teorico sia per il codice che per tutti i tipi di dato (vedere figura 6).
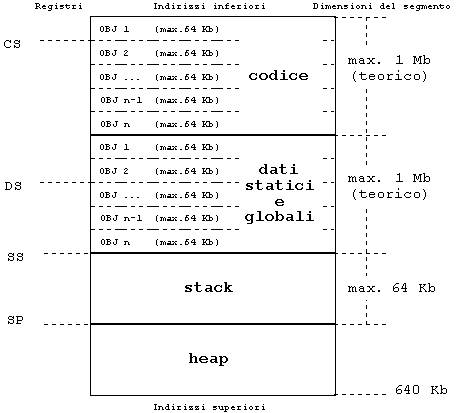
L'opzione (Borland) per la compilazione secondo il modello huge è mh.
Dal momento che la dimensione di ogni singolo modulo oggetto di
dati statici e globali non può superare i 64 Kb,
il superamento del limite dei 64 Kb è da intendersi
per l'insieme dei dati stessi; non è possibile avere un
singolo dato static (ad esempio un array) di dimensioni
maggiori di 64 Kb. Il registro DS è
inizializzato con l'indirizzo di uno dei moduli di dati statici
e globali.
 OK, andiamo avanti a leggere il libro...
OK, andiamo avanti a leggere il libro...
 Non ci ho capito niente! Ricominciamo...
Non ci ho capito niente! Ricominciamo...