Costruzione di un interprete Come si costruisce un interprete? Questa relazione
cerca di rispondere a questa domanda. Lo fa descrivendo sia i passi teorici
necessari, sia quelli realmente affrontati nel corso del progetto.
Il primo passo teorico è quello di capire
cos'è e come si definisce un linguaggio. Se introduciamo un insieme
di simboli, l'alfabeto, allora possiamo definire un linguaggio come "un
particolare insieme di frasi formate dai simboli dell'alfabeto".
Ma come fare a descrivere quell'insieme se è infinito? È
necessario introdurre una notazione che consenta di descrivere l'insieme
in modo finito e non ambiguo. Il linguaggio viene descritto allora tramite
la grammatica che lo definisce. Di seguito si darà un breve
accenno all'argomento, per una trattazione dettagliata si veda la pagina
dedicata all'argomento sul sito del corso.
Una grammatica G è l'insieme di 4 enti: un
insieme VN di meta-simboli detti anche simboli non terminali, un insieme
VT di simboli terminali, lo scopo S della grammatica (un elemento di VN
detto start-symbol), un insieme P di produzioni, ovvero di regole di riscrittura.
Un linguaggio L(G) generato dalla grammatica G = {VT,VN,S,P} è l'insieme
delle frasi s tali che:
s appartiene a VT* e S =>*
s, ove
VT*=chiusura di VT, ovvero insieme di tutte le stringhe componibili
con i simboli di VT,
S =>* s significhe che s è derivabile a partire dallo scopo
S applicando zero o più applicazioni di produzioni.
Le grammatiche sono suddivise in 4 tipi, in
base alla classificazione proposta da Noahm Chomsky. La classificazione
è basata su un insieme di restrizioni sulle produzioni.
Le grammatiche di tipo 0 sono
quelle in cui non si hanno restrizioni.
Le grammatiche di tipo 1 sono
anche dette grammatiche dipendenti dal contesto e sono caratterizzate dal
fatto che l'applicazione delle produzioni non porta mai alla diminuzione
della lunghezza di una frase.
Le grammatiche di tipo 2 sono
anche dette grammatiche libere dal contesto o algebriche,
anche in esse l'applicazione di una regola di produzione non porta mai
alla diminuzione della lunghezza della frase.
Le grammatiche di tipo 3 sono
anche dette regolari (possono essere lineari a destra o sinistra).
I vari tipi di grammatiche sono in relazione gerarchica
fra loro, ovvero le grammatiche di tipo 4 sono anche di tipo 3, quelle
di tipo 3 sono anche di tipo 2, etc.
Nella descrizione dei linguaggi di programmazione
generalmente si usano grammatiche libere da contesto in quanto queste consentono
di derivare le frasi del linguaggio in modo semplice e automatizzabile.
Quest'ultimo fatto è molto importante perché consente una
facile realizzazione di compilatori ed interpreti.
Dopo aver definito la grammatica da cui deriva il
linguaggio è possibile avviare l'implementazione dell'interprete
(o del compilatore). Interprete e compilatore possono essere schematizzati
nel modo seguente:
figura 1.
I componenti indicati sono:
un analizzatore lessicaleAL
che ha il compito di ricevere in ingresso la stringa S e fornire
in uscita i tokens T, cioè deve costruire le parole del linguaggio
a partire dalla semplice sequenza di caratteri;
un analizzatore sintatticoAS
che riceve dall'AL i tokens (ciascuno dei quali rappresenta un possibile
simbolo terminale della grammatica G) e verifica che la sequenza
di questi costituisca una frase del linguaggio oppure no, costruendo contestualmente
una riscrittura della frase stessa in una forma particolare che costituisce
la rappresentazione interna RI della frase
nell'interprete (solitamente si usa una particolare struttura ad albero
detta APT, ovvero abstract
parse tree);
un valutatoreV che riceve dall'AS
la forma interna e fornisce in uscita il risultato di una valutazione,
ovvero associa la frase in ingresso al valore corrispondente nel dominio
semantico scelto (un valore numerico o di verità Val, il
codice macchina Code, oppure altro ancora).
Usando un linguaggio di programmazione ad oggetti l'AL
può essere pensato come un'entità (oggetto) che possiamo
chiamare lexer e che riceve in ingresso una stringa. Il lexer è
dotato del metodo next(): ad ogni chiamata di tale metodo l'oggetto lexer
processa la stringa selezionando e restituendo un token. In questo modo
è possibile ottenere la successione dei tokens utilizzando un semplice
ciclo che ad ogni iterazione effettui una chiamata del metodo next() dell'oggetto
lexer.
I tokens costituiscono l'input dell'AS, quindi sarà
esso a contenere il ciclo con le chiamate a next(). A sua volta l'AS potrà
essere realizzato come un oggetto che chiameremo parser. Il suo
compito sarà quello di implementare il processo di derivazione delle
frasi del linguaggio a partire dallo scopo della grammatica. In sostanza
il parser deve implementare un automa riconoscitore del linguaggio. Il
problema del riconoscimento delle frasi di un linguaggio è tutt'altro
che semplice. Vediamo di capirne il motivo. È possibile associare
a ciascun tipo di grammatica un particolare tipo di automa in grado di
riconoscere le frasi appartenenti ad un linguaggio che sia generato da
quel tipo di grammatica. Tutto ciò è riassunto nella seguente
tabella:
Linguaggio generato da
Riconosciuto da
Note
Grammatica di tipo 0
Macchina di Touring con nastro espandibile senza limite
Il riconoscimento di una frase potrebbe richiedere tempo infinito
Grammatica di tipo 1
Macchina di Touring con nastro limitato
Nessuna nota
Grammatica di tipo 2
Automa a stati finiti con stack
Facile da implementare
Grammatica di tipo 3
Automa a stati finiti
Facile da implementare
I linguaggi di tipo 2 ed 3 consentono un'operazione
di riconoscimento molto più semplice e quindi efficiente. Per questo
motivo i liguaggi di programmazione sono normalmente generati da grammatiche
di tipo 2 e 3 (queste ultime sono solitamente usate per sottoparti del
linguaggio come ad esempio gli identificatori ed i numeri).
Stabilito l'automa bisogna decidere come implementarlo.
L'implementazione può avvenire in vari modi:
in modo ricorsivo, tramite una coppia di funzioni che rappresentano
la funzione di stato futoro e la funzione di uscita: all'avvio si chiamerà
la funzione di stato futuro passandogli come parametri lo stato zero (iniziale)
ed il primo simbolo in ingresso (token);
tramite un algoritmo iterativo;
tramite la definizione di una funzione per ogni stato;
tramite un interprete per automi a stati finiti (ASF),ovvero
implementando una macchina che riceve una descrizione dell'ASF (che sarà
data dalle tabelle degli stati futuri e dell'uscita) ed è in grado
di effettuare il riconoscimento della stringa seguendo i passi descritti
dall'ASF (si tratta di una macchina di Touring universale);
tramite tecniche table driven, in cui si il riconoscimento della
frase è guidato da una tabella riassuntiva delle transizioni di
stato in funzione del simbolo;
...
L'analisi ricorsiva discendente consente
di realizzare un riconoscitore per un linguaggio definendo una procedura
per ogni simbolo non terminale X della grammatica. Ogni procedura ha il
compito di "consumare" la parte di frase corrispondente al linguaggio generato
a partire dal simbolo X (L(X)). Se il simbolo X si sostituisce un un simbolo
terminale la procedura associata ad X consuma il simbolo terminale. Se
invece il simbolo terminale X si sostituisce con un simbolo non terminale
Y allora la procedura associata ad X delega la procedura associata ad Y
a consumare L(Y). Esempio:
X ::= x | x Y
Y ::= y | y X
allora la frase "xyx" viene riconosciuta nel modo seguente (X sia lo
scopo):
la procedura X() verifica che il simbolo corrente è x e lo consuma,
poi trova y e chiama la procedura Y();
la procedura Y() verifica che il simbolo corrente è y e lo consuma,
poi trova x e chiama la procedura X();
la procedura X() verifica che il simbolo corrente è x e lo consuma,
poi trova il terminatore e si ferma con successo.
L'interprete implementato nell'ambito di questo progetto
utilizza un riconoscitore (parser) basato prorpio sull'analisi ricorsiva
discendente.
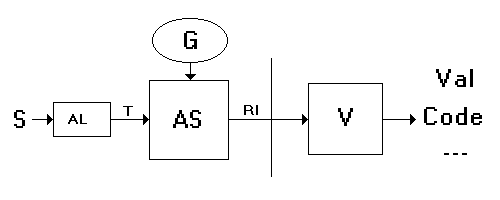 figura 1.
figura 1.