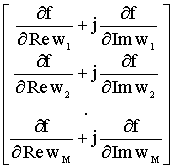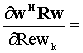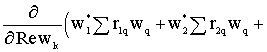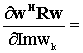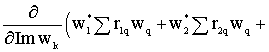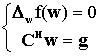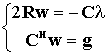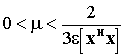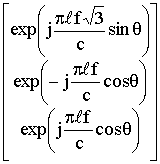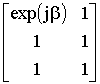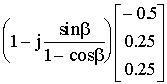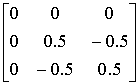
|
|
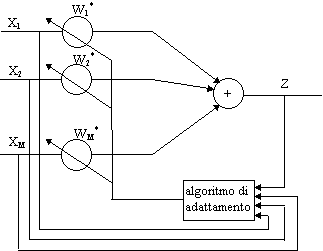
3. BEAMFORMING ADATTATIVO: L’ALGORITMO DI FROSTNel capitolo 1 avevamo introdotto un criterio di calcolo dei pesi w basato sulla ricerca del guadagno ottimo G. Questo criterio, classificato in letteratura come optimum beamforming , è basato sulla conoscenza a priori delle matrici R e Q, matrici di autocorrelazione del segnale e del rumore. Il beamforming adattativo aumenta il guadagno dell’array senza alcuna conoscenza sul rumore, aggiustando i pesi w a partire dalla sola conoscenza dei dati in ingresso come rappresentato in figura 3.1.
Figura 3 . 1 Beamforming adattativo. L’algoritmo di Frost si basa sull’idea di minimizzare la potenza totale di uscita, che è direttamente misurabile, sotto il vincolo di mantenere la risposta uniteria per segnali che arrivano dalla direzione di puntamento. In formule: Minw wH R w vincolato dH w = 1 dove d è il vettore di steering nella direzione di puntamento. Più in generale si può generalezzare e introdurre una matrice dei vincoli CH w = g, che, come minimo, deve contenere il vincolo dH w = 1. In C possono essere contenuti dei vincoli che introducono dei nulli in particolari direzioni o in generale dei vincoli sulla forma della risposta spaziale dell’array. Il problema posto diventa: Minw wH
R w
vincolato
CH w = g La matrice CH ha dimensionbe K ´ M dove assumiamo che il numero di vincoli K siano linearmente intipendenti e sia K < M. Calcoliamo il minimo con il metodo dei moltiplicatori di Lagrange : il problema vincolato si riconduce al calcolo del minimo della funzione : f(w)
= wH
R w + l1
v1 (w) + l2
v2 (w) + . . . + lK
vK (w) che si può scrivere: f(w)
= wH
R w + (CH w - g )H l dove li ³ 0 sono i moltiplicatori di Lagrange, l è il vettore K´1 dei moltiplicatori, v i (w) sono i vincoli, cioè le righe dell’equazione CH w - g . La f(w) raggiunge il minimo per quel wopt tale che rende nullo il gradiente di f. E’ necessario calcolare D w f: D
w f =
Calcoliamo il gradiente per ciascun termine di f:
..+
=
Questa ultima formula è la K-esima riga del vettore M´1 (wHR)T
+ Rw =[1]
R*w*
+ Rw = 2 Re (Rw).
=
Questa ultima formula è la K-esima riga del vettore M´1 j[ (wHR)T
- Rw ] = j( R*w*
- Rw) = 2 Im (Rw). Risulta: D w ( wH R w ) = 2 Re (Rw)
+ j 2 Im (Rw) = 2 Rw Con formule altrettanto noiose di quelle viste sopra si calcola il gradiante del secondo termine di f: D w (C*
w - g )H l
= C l
Il sistema di equazioni :
è composto da M + K equazioni, dunque può essere risolto rispetto a w e l ( rispettivamente M e K incognite). Ricavando w dalla prima e sostituendo nella seconda: w
= -
-
Ricavando l dalla seconda e sostituendo nella prima: l = - 2 ( CH R-1 C )-1 g ( ip. sia ( CH R-1 C )-1invertibile) w = R-1
C ( CH R-1 C
)-1 g
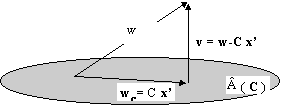
(1) E’ utile vedere w come un vettore di CM e decomporlo nei vettori: w = wc + v dove wc
è la proiezione di w nel sottospazio
delle colonne di C, (
Â(C)
), mentre v è la proiezione di w
nello spazio ortigonale alle colonne di C,
Â(C)^.
L’algebra lineare dimostra che lo spazio ortogonale di Â(C) è lo spazio nullo o nucleo
di CH
(
Â(C)
=(
Siccome la base di Â(C) è composta dalle K colonne di C ( per ipotesi le colonne di C sono linearmente indipendenti: rango di C = K), allora si può calcolare esplicitamente wc.
Figura 3 . 2 Scomposizione intuitiva di w nelle componenti wc e v. Il problema può essere posto in questo modo: trovare x’ Î CK tale che wc = C x’ . Risulta v = w - C x’ , ma v deve essere ortogonale a Â(C) e cioè per ogni y Î Â(C) deve essere yH v = 0, oppure per ogni x Î CK vale (C x )H v = 0. (C
x )H ( w - C x’
) = 0
"
x Î
CK xH
( CH w - CH
C x’ ) = 0
"
x Î
CK Queste equazioni sono vere " x Î CK se e solo se : CH
w - CH
C x’ = 0 Þ
CH C x’ = CH w Si può dimostrare che se C è una matrice M´K di rango K allora la matrice CHC è una matrice K´K, hessiana e di rango K, dunque invertibile. Allora: x’ = ( CH C )-1 CH w Possiamo calcolare wc : wc
= C ( CH
C )-1 CH w,
(2) mentre v
= w - C ( CH
C )-1 CH w . Definita Pc = C (CH C )-1 CH , matrice di proiezione, risulta: wc
= Pc w v = ( I - Pc ) w Sostituendo nella 2 il valore ottimo di w troviamo una nuova formula per wc : wc
= C ( CH
C )-1 CH R-1
C (CH
R-1 C)-1 g wc
= C ( CH
C )-1 g 3.1. L’algoritmo adattativo E’ importante notare che wc non dipende dalla matrice R, il che equivale a dire che non dipende dai segnali in ingresso
all’algoritmo, ma solo dai vincoli che abbiamo imposto. Possiamo intuire che
comunque variamo v nello spazio
w( t + 1) = wc + ( I - Pc ) [ w( t ) - m R w( t ) ] (3) m è il tasso di adattamento, mentre R w( t ) è il gradiente della potenza di uscita (wH R w). Il termine ( I - Pc) garantisce che w varia solo nella componente v così in ogni istante saranno rispettati i vincoli. E’ scomodo che nella 3 compaia R, perché questa è difficile da stimare, allora si può adottare un approccio di tipo LMS in cui a R si sostituisce una sua stima. La più semplice : R ( t) = x (t) xH (t) , sostituendo nella 3 w( t + 1) = wc + ( I - Pc ) [ w( t ) - m x (t) xH (t) w( t ) ] w( t + 1) = wc + ( I - Pc ) [ w( t ) - m x (t) z*(t) ] (4) La 4 è di più facile implementazione rispetto la 3. Frost dimostrò che l’algoritmo converge se il tasso di adattamento m verifica il vincolo:
3.2. Prima applicazione dell’algoritmo di Frost Consideriamo un array di tre microfoni disposti come i
vertici di un triangolo equilatero di lato
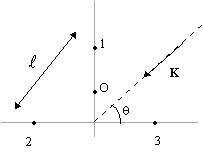
Figura 3 . 3 . Array triangolare di microfoni. Ricordiamo il vettore di steering: d(q)
=
Imponiamo due vincoli: ·potenza
di segnale unitaria per onde che incidono nella direzione q
= p/2.
dH (p/2
·potenza di segnale nulla per onde che arrivano dal centro O dell’array. Questo vincolo potrebbe avere senso se l’array è usato come microfoni in un telefono ‘viva voce’ e nel punto O è posto l’altoparlante del telefono. Siccome la onde dal punto O giungono in fase ai tre microfoni, tale vincolo si esprime imponendo che la somma dei pesi w1 + w2 + w3 sia nulla: [1 1 1] w = 0. I due vincoli costruiscono le matrici C e g di seguito. C =
Dove si è indicato b
=
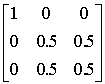
wc =
Pc =
I - Pc
=
Secondo la formula 4 e le matrici sopra riportate calcoliamo l’algoritmo di adattamento dei pesi: w01(t +1) = 0 w02(t
+1) =
w03(t
+1) = - w02 (t +1)
[1]Ricordiamo che R è una matrice hermitiana R = RH [2]Sia C una matrice complessa M´K, con K < M e rango K. Si definisce spazio delle colonne di C Â(C) il sottospazio vettoriale di tutti gli y Î CM : y = C x " x Î CK. Si dimostra che la dimensione di Â(C) è K. Si definisce spazio nullo di CH, ( CH ), ( detto anche spazio nullo sinistro di C) il sottospazio vettoriale di tutti gli x Î CM : CH x = 0. Si dimostra che la dimensione di ( CH ) è M-K. Teorema fondamentale dell’algebra lineare Â(C) =( ( CH ) )^. |