Strutture dati in Java
Il programma che viene qui presentato è un semplicissimo software a linea di
comando di archiviazione di film in grado di effettuare ricerche e ordinamenti e
di salvare
lo stato dell'archivio in un file di stato denominato "stato.txt". Nel file si
fa uso di strutture dati come TreeMap, LinkedList e Hashtable
e le implementazioni usate sono quelle standard di della libreria java.util.*.
Prima di descrivere il programma è opportuno chiarire per sommi capi cosa siano
le strutture dati ed in particolare quelle citate. Una struttura dati
in generale altro non è che un contenitore in cui noi in qualche modo
poniamo dati. In Java il dato riposto è sempre un oggetto e a sua volta
la struttura dati è oggetto. Questa perfetta coerenza consente in pochi
passi di costruire strutture dati anche abbastanza intricate e connesse fra
loro. Ciò che differenzia le varie strutture dati sono diversi fattori:
come vengono allocate in memoria, la capacità ed eventualmente la capacità
di espandersi, la velocità di ricerca, ammettere o meno dati duplicati
o dei "null" ecc. Principalmente si dividono in due categorie : str. statiche e
str. dinamiche. Le strutture statiche sono per esempio gli array mono e multi
dimensionali. Quando vengono inizializzati predispongono fin dall'inizio tutta
la memoria necessaria per essere riempiti completamente . Si immagini ora la
seguente situazione: bisogna costruire un archivio, magari di film, che non
ammetta duplicati fra i titoli e di cui
ovviamente non si conosce a priori l'estensione; si chiede dunque di costruire
un software che gestisca un archivio di film il cui numero è del tutto
aleatorio e magari varia tra 0 e 1000. Una soluzione potrebbe essere quella
di allocare un array di oggetti film grande 1000.......è chiaro come
questa sia una soluzione del tutto inefficiente : si immagini di dover
archiviare
10 film => ho perso 990 posizioni dell'array completamente inutilizzate ma
che occupano memoria! D'altra parte se volessi archiviarne 1000+1 il mio array
sarebbe pieno e dovrei riallocarlo. Ciò che si evince da questo banale esempio è
che seppur una struttura dati statica garantisca una "immediata"( O(1) ovvero in
tempo costante ) intercettazione del dato, è anche vero che la sua flessibilità
ed efficienza in una situazione di questo tipo sono scarse per non dire pessime.
Per porre rimedio
a questa situazione sono nate le strutture dati dinamiche che garantiscono al
costo di tempi di ricerca più lunghi una flessibilità decisamente
maggiore. L'esempio più semplice di str. dinamica è la LinkedList: prima
di tutto
che cos'è una lista ? In Java è ovviamente un oggetto ma che contiene
altri oggetti (si potrebbe iterare ricorsivamente all'infinito ma non è il
caso!). Per
immaginarla si pensi ad un treno in cui ogni vagone "vede" il vagone
precedente e quello successivo e a sua volta quello successivo "vede"
il suo precedente (previous ) ed il suo successivo ( next ) sino ad arrivare
alla
locomotiva o se vogliamo inizio o testa (head) della lista che punta ovvero è
collegata al suo precedente e davanti non ha nessuno. Perchè linked ?
ovviamente perchè i vagoni sono collegati anche se questo collegamento
è di un vagone con altri due e mai di un vagone collegato con tre o più vagoni.
Ne risulta uno schema del tipo : "io sono un vagone so chi ho davanti
so chi ho dietro e so chi contengo". Avevamo detto che le str. sono contenitori
di dati : nel caso del vagone il contenuto sono i passeggeri o le merci , nel
caso della lista ogni nodo-vagone della lista contiene come è facile
indovinare un oggetto. La struttura che ne risulta graficamente è la
seguente:
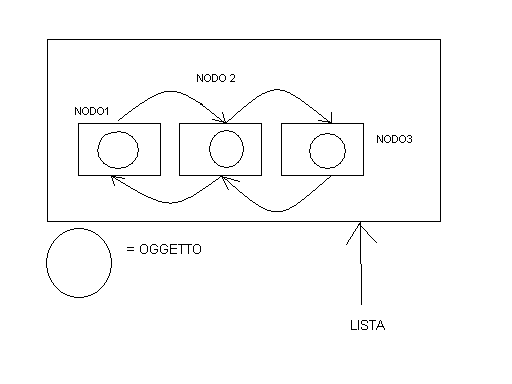
La straordinarietà di questa struttura è che posso mettere e togliere
vagoni-nodi che contengono passeggeri-oggetti quando voglio anche in
corsa-runtime. Non ho un treno-lista di lunghezza fissa ma sono io che di volta
in volta ne cambio lunghezza e contenuto.
Ricordandoci poi che ogni nodo può contenere un oggetto, nulla vieta di
porre in un nodo una lista, cioè fare una lista i cui oggetti sono a
loro volta liste , se volete una matrice variabile(qui non uso il paragone per
evitare situazioni grottesche tipo vagone che contiene una ferrovia , o vagone
che punta ad un treno...). Altro elemento
importante delle liste è la possibilità di usare l'iteratore</font>. Ritornando
al nostro trenino per immaginare l'iteratore pensate al controllore che viaggia
sul treno e che può scorrere l'intero treno partendo da dove si trova , avanti e
indietro. L'iteratore di fatto è
un'oggetto che può scorrere la lista nelle due direzioni (solo se è
un iteratore di lista e non un iteratore e basta, per chiarimenti si rimanda
alla documentazione di Java) e fare alcune operazioni di lettura e rimozione
di nodi. Ciò che è subito evidente è che per raggiungere
un certo nodo il povero iteratore-controllore deve camminare per tutta (partendo
da cima o in fondo) la lista-treno fino a beccare l'oggetto-passeggero che è
da leggere-controllare o eliminare (nel caso in cui il passeggero fosse
sprovvisto
di biglietto....): in tal modo si evince come la flessibilità si paghi
con il mal di piedi dell'iteratore-controllare che si deve iterare-camminare
magari un bel po' di nodi-vagoni prima di giungere all'obbiettivo . Comunque
utilizzando un iteratore di lista, è possibile far partire l'iteratore
da un indice particolare trattando la lista come simil array. Questa pratica
tuttavia spesso non è possibile e si è costretti a far partire
l'iteratore dall'inizio visto che quasi sempre non si sa in che posizione è
il nodo-vagone da leggere o rimuovere, il che obbliga a partire da capo e
controllare
vagone per vagone. Il concetto di str. dinamica si basa proprio sul fatto di
non sapere a priori la quantità dei dati , quindi pensare di conoscere
l'indice del nodo dell'oggetto che ci interessa è altamente improbabile!
Passiamo adesso alla Hashtable: la Hashtable è una tabella che attraverso una
funzione di hash associa una chiave univoca ad un oggetto. La chiave è un
oggetto come per es. una
stringa, ed è univoca ovvero non possono esserci chiavi uguali . Sulle
funzioni di hash ci sarebbe da dire moltissimo ed esiste tutta una letteratura
sull'argomento a cui rimando per possibili chiarimenti ; di semplice possiamo
dire che essendo la hashtable una str. dinamica essa si espande e ogni volta
che lo fa deve "rehashes itself" cioè rimappa le sue chiavi
in memoria in modo da mantenere la consistenza dei dati. Andare maggiormente
nei dettagli significherebbe introdurre concetti teorici non banali. Come
è facile immaginare la hashtable avrà un qualche metodo per riconoscere
le proprie chiavi , quale? Per riconoscere le chiavi ogni oggetto che
costituisce una chiave deve restituire un hashcode ovvero un codice hash univoco
che di fatto è un int. Se volessi
mettere come chiave una String non ci sono problemi visto che la classe String
è scritta in modo che restituisca un hashcode. Il metodo utilizzato è
hashcode(). Questo metodo associa un hashcode all'oggetto passato come
parametro.
Se si volesse porre come chiave un nostro oggetto, magari un film, bisognerebbe
fare in modo che il nostro oggetto restituisca un hashcode univoco, come fare
? è sufficente ridefinire nel nostro oggetto il metodo di firma "public
int hashcode()" assicurandoci che il codice ritornato sia effettivamente
univoco, come ? utilizzando una caratteristica univoca dell'oggetto in
questione.
Nel nostro caso sicuramente il film di unico ha il titolo quindi è opportuno
restituire come hashcode l'hashcode associato alla stringa di titolo ovvero
porre nell'oggetto film:
public class Film{ // alcuni campi String titolo; // costruttore, metodi public int hashcode() { return titolo.hashcode(); } }
In tal modo quando metterò l'oggetto film come chiave l'hashtable troverà
come codice della chiave film l'hashcode associato alla stringa del titolo del
film. Un' altra soluzione sarebbe stata quella di porre come chiave la stringa
stessa del titolo e come oggetto il film stesso. Si può fare qualcosa di meglio:
se mettessi come chiave l'anno di uscita del film cioé una stringa, come oggetto
cosa metterei? il solo film no perché potrei avere più film dello stesso anno e
dunque? e dunque
come oggetto porrò una linkedlist di tutti i film di quell'anno. Ecco
come le chiavi di un hashtable si riferiscono a delle linkedlist. Come
si diceva all'inizio con pochi passi si è fatto uso di più strutture
dati contemporaneamente. L'utilità delle hashtable risiede nella possibilità di
fare ricerche in quasi O(1) ovvero un tempo molto veloce per una struttura
dinamica. Se avessi a disposizione una lista avrei come minimo O(n) o log(n) per
una struttura ad albero binario
o in altri casi n*log(n). Bisogna riporre attenzione ad un fatto: se
avessi due hashtable con chiavi una stringhe di anni e l'altra stringhe di
registi
entrambe punterebbero a liste di film le quali a loro volta avranno nodi che
punteranno a film: dato che tutti i film saranno in comune si potrebbe pensare
che ci sia un overhead computazionale dovuto al fatto che si hanno 2 hashtable
le cui chiavi puntano a liste duplicate di film ........ma così non è
nel momento in cui modificassi un oggetto estraendolo da una hashtable le
conseguenze
verrebbero risentite anche dall'altra hashtable , perché? Perché
quando si è parlato delle liste si è detto che esse sono contenitori
di oggetti , ma l'oggetto contenuto nelle liste della prima o nella seconda
hashtable di fatto è lo stesso, sono liste diverse che "puntano"
allo STESSO oggetto e non due liste con oggetti duplicati. Se
si memorizza un oggetto e lo si mette in una lista quando questo viene messo
in una seconda lista non è creato un nuovo oggetto copia ma sono i nodi
delle liste che puntano allo stesso oggetto! Se volessimo ridisegnare adesso
in modo più appropriato la lista dovremmo fare così:

Per chiaririsi le idee si legga il seguente sorgente ed il suo output:
import java.util.*;
public class Provetta {
LinkedList lista1;
LinkedList lista2;
public static void main (String[] argv)
{
(new Provetta()).start();
}
public Provetta()
{
// creo due liste
lista1= new LinkedList();
lista2= new LinkedList();
}
public void start(){
Film f = new Film();
// ci metto lo stesso oggetto
lista1.add(f);
lista2.add(f);
System.out.println(lista1);
System.out.println(lista2);
f.titolo="Io speriamo che me la cavo";
System.out.println(lista1);
System.out.println(lista2);
}
}
OUTPUT
[Titolo: ignoto; Anno: ignoto; Casa: ignoto; Regista: ignoto Premi : ignoto]
[Titolo: ignoto; Anno: ignoto; Casa: ignoto; Regista: ignoto Premi : ignoto]
[Titolo: Io speriamo che me la cavo; Anno: ignoto; Casa: ignoto; Regista:
ignoto Premi :ignoto]
[Titolo: Io speriamo che me la cavo; Anno: ignoto; Casa: ignoto; Regista: ignoto
Premi : ignoto]
L'ultima struttura dati che ci rimane da analizzare brevemente è la TreeMap.
Si tratta in sostanza di una hashtable in cui si possono ordinare le chiavi. Se
la si inizializza
con il costruttore a cui si passa un comparatore, le chiavi saranno ordinate
secondo il comparatore , altrimenti utilizzando il costruttore di default verrà
utilizzato l'ordine naturale delle chiavi. Per ordine naturale si intende che
il valore ritornato da compareTo che in tal caso deve essere presente
nell'oggetto, pena una ClassCastException . In definitiva se voglio utilizzare
un comparatore
esterno inizliazzo la TreeMap con il primo costruttore citato diversamente se
utilizzo il costruttore di default le chiavi devono avere un ordine naturale
ovvero devono implementare l'interfaccia Comparable. Esistono altre
strutture dati tra cui la Hashtable debole, la HashMap, la Mappa, i Set e le
Enumerazioni, ma queste strutture pur avendo caratteristiche salienti, se ne
rimanda l'eventuale
studio di queste nella bellissima documentazione messa a disposizione da Sun.
Il programma legge da file a scelta lo stato
dell'archivio e attraverso varie voci che scoprirete nel sorgente è in grado di
leggere la lista dei film di fare ricerche
e di modificarla a voi il divertimento.