
Statistiche testuali
Come esempio di procedura che utilizza le statistiche testuali si voleva proporre l'analisi di risposte ad un questionario aperto, ma dato che non si ha un database significativo e si dispone soltanto di una serie di risposte già compilate alla domanda "Cosa ne pensa dell'agenzia per cui lavora?" che non ha attinenza con la pianificazione (e per di più e in francese) si è pensato di proporre un altro esempio più attivo, cioè l'analisi di pagine scaricate o scaricabili da Internet sull'argomento "pianificazione, uso del suolo, crescita e dispersione".
Al termine della spiegazione c'è la proposta di un esercizio che l'utente può provare a fare sull'esempio presente; questo, infatti, guida l'utente ad essere indipendente nell'utilizzo del software e nell'interpretazione dei risultati.
I due pacchetti software scelti sono:
Se è possibile utilizzare Internet, si consiglia di scaricare direttamente le pagine dalla rete, in modo da avere più chiara l'idea del procedimento e delle problematiche operative che si possono riscontrare.
Se non è possibile eseguire un collegamento alla rete, sono disponibili dei dati di input scaricabili a fondo pagina. Si tratta di una serie di pagine html scaricate precedentemente da internet. L'argomento della ricerca è stato scelto come "planning, growth, land use, sprawl" (pianificazione, crescita, uso del suolo, dispersione).
Inserimento dei dati di input
Per l'inserimento dei dati di input ci sono due metodi:
- Navigando sull'argomento "planning, growth, land use, sprawl" e salvando le pagine di interesse in un'unica cartella lasciando pure il nome di default. In questo caso, una volta aperto Wordmapper, occorre utilizzare la funzione fusion pages; il programma creerà nella cartella selezionata una serie di file html chiamati "fusionx", dove x è un numero d'ordine ed un file "fusion.txt" contente tutti i testi trovati.
- Utilizzando un motore qualsiasi di ricerca, inserendo le quattro parole e salvando la pagina, a ricerca effettuata, in una cartella. Dato che solitamente un motore di ricerca visualizza circa venti link alla volta, occorre salvare anche le altre pagine "search" trovate (si consiglia di salvare in totale almeno quaranta pagine). In questo caso, durante il collegamento ad internet occorre invece utilizzare la funzione telecharge, indicare il nome del documento .txt che verrà creato dal programma (si consiglia il nome "download") e selezionare il file della pagina di ricerca salvata precedentemente.
Successivamente indicare le pagine da scaricare (linkate alle pagine "search"). Si avvia così il download automatico delle pagine; è possibile quindi evitare di scaricare pagine che già a prima vista non contengono informazioni inerenti all'argomento. Importante è quindi "pulire" la lista delle pagine da quelle che non si dovrebbero prendere in considerazione.
Ripetere l'operazione per le altre pagine "search", fino al numero ritenuto necessario. Vengono creati man mano file "download.htm" nella cartella più il file "download.txt" contenente il testo di tutte le pagine.
Alla fine del processo, cliccare fusion e selezionare tutte le pagine scaricate (fare attenzione a non selezionare le pagine di testo); il programma chiede di dare un nome al file di testo che creerà (si consiglia "Fusione"). Vengono creati tanti file "fusion.htm" quanti erano i file "download.htm", insieme ad altri file che il programma utilizza.
Ogni volta che si usa l'opzione telecharge il programma chiede se elaborare subito il grafico: dato che si hanno più pagine con cui lavorare si consiglia di effettuare il grafico al termine della fusione.
La versione demo non permette di aprire un motore di ricerca direttamente dal programma (per velocizzare la ricerca e il download delle pagine), perciò occorre agire nei due modi sopraelencati.
Terminato l'inserimento dei dati, vengono visualizzate due schermate: sopra, numerate da 1 al numero totale di pagine, c'è l'elenco delle pagine; sotto, invece, c'è la parte testuale di ogni pagina.
Si procede ora con l'analisi semantica, fermo restando che la numerotizzazione non è visibile perché viene fatta automaticamente dal programma. L'analisi di contenuto non è stata esaminata in questa sede.
Creazione di parole-chiave
Quando si sceglie l'opzione Création des mots signifiants appare una schermata che chiede se ricercare anche parole composte (scegliere sì) e con quale frequenza minima (scegliere 5). Per le parole-chiave, scegliere 3 come numero di caratteri minimi e 5 come frequenza minima. Mettere come filtro
tous le mots. Il programma chiede anche se esiste un vocabolario di parole da ignorare, ma si suppone che si è in una fase di ricerca non troppo fine, perciò lasciare il file Standard.
A questo punto viene visualizzata una lista di segmenti ripetuti (tra cui "smart growth", "urban sprawl", ad esempio), selezionarli tutti; ad ogni modo questa fase è a discrezione dell'utente: se infatti uno considera inutili alcune forme può decidere di non selezionarle. Il programma crea quindi tanti file di estensione .cod quanti sono i file html.
Di seguito si ha la possibilità di scegliere le parole-chiave; appare infatti una schermata in cui alla sinistra vi è la lista delle parole composte e semplici con frequenza minima decisa a priori (sopra in ordine di frequenza, sotto in ordine alfabetico), ed è possibile trasportare a destra le parole che l'utente considera importanti. Nel caso, si può semplicemente ordinare al programma di decidere che le parole chiave sono quelle che superano una certa frequenza, oppure si può decidere di prenderne un numero fisso (iniziando da quelle a più alta frequenza). Si è scelto quest'ultima opzione, perciò selezionare
Seléction systématique de mots par fréquence ed inserire il numero 50.
Si crea così un grafico dove a sinistra stanno le parole-chiave e a destra le connessioni tra le parole chiavi più frequenti e le
altre.
Esempio di schermata:
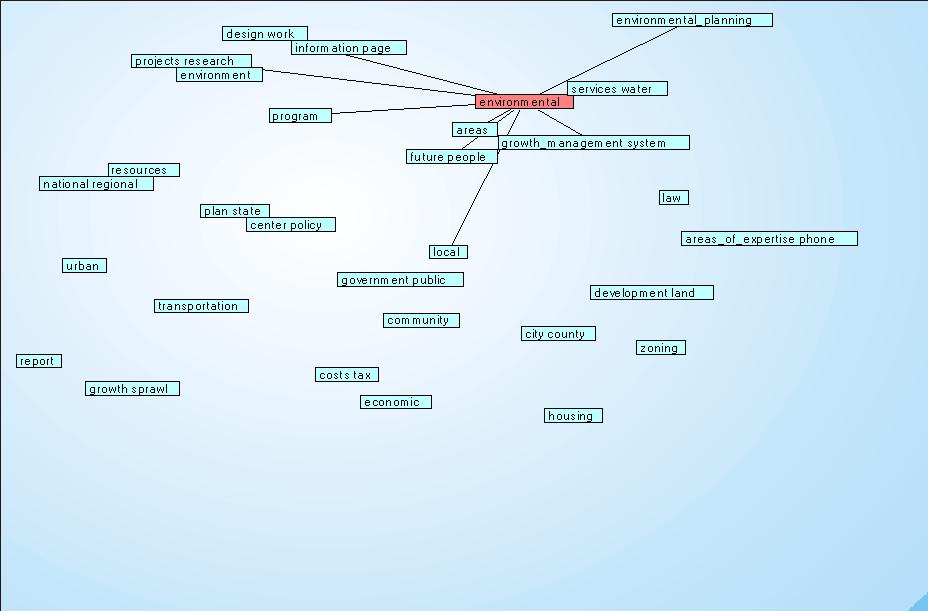 Cliccare sull'immagine per ingrandire
Cliccare sull'immagine per ingrandire
Classificazione delle parole-chiave (Clustering)
Le parole nei riquadri sono in realtà già frutto di una precedente classificazione in gruppi. Se infatti si sceglie l'opzione Affichage - cluster réduit à 1 mot si visualizza nel grafico il raggruppamento di cui fa parte la parola chiave. Il programma infatti cerca le parole chiave che si trovano più spesso le une vicino alle altre e le raggruppa sotto lo stesso cluster, in modo da capire il contesto. Si fa notare che se si scelgono poche parole-chiave la probabilità che queste siano vicine o nella stessa frase cala di molto, perciò può capitare che un cluster sia formato da una sola parola. La ricerca effettuata conduce ad un grafico di questo tipo:
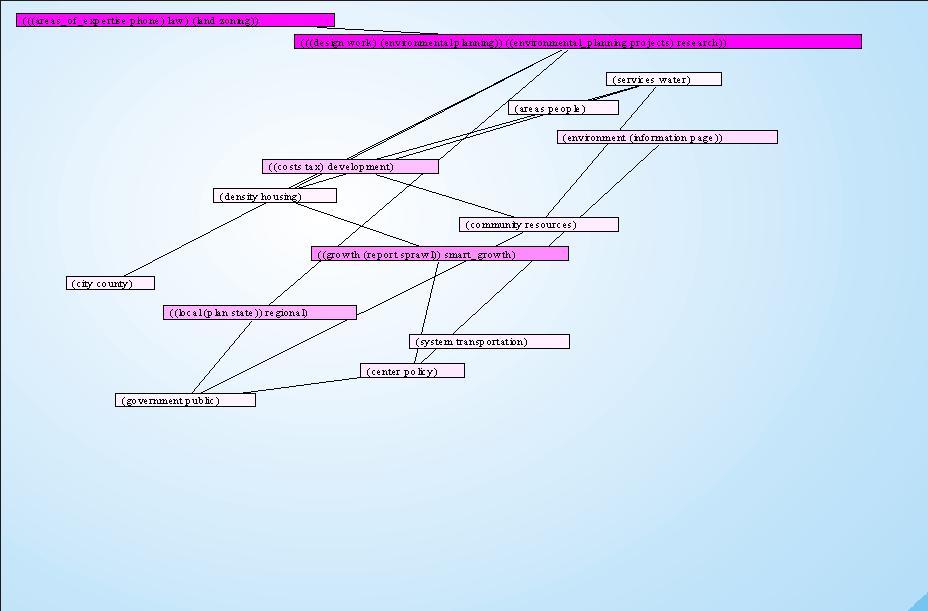 Cliccare sull'immagine per ingrandirla
Cliccare sull'immagine per ingrandirla
Se si apre un cluster (cliccando velocemente due volte) si aprirà un'altra finestra in cui vi sono le parti di testo scaricate dalle pagine Internet che riportano le parole in questione: ciò serve per velocizzare la ricerca, comprendere gli argomenti e notare pagine che contengono testi considerati inutili.
Ricerca semantica
Ciccando su una parola chiave è possibile vedere i vari contesti in cui questa parola è stata utilizzata. Ciccando ad esempio su "planning", si nota che la parola è utilizzata nei vari contesti "environmental" (perciò
aprendo il cluster vengono mostrati i testi che comprendono le due parole), "urban", "resources", "preservation", "land", "information", etc.
Quando nelle varie elaborazione si notano dei legami fra le parole o i cluster, significa che ci sono legami statistici ben precisi tra i due elementi; inoltre
il software dispone le parole nel grafico a seconda di quanto vicine compaiono nel testo, perciò è possibile operare una prima unione di cluster in grandi temi. Ad esempio, si nota che la ricerca semantica della parola "planning" porta alla visualizzazione di tre grandi temi: uno riguardante l'aspetto di pianificazione legato alla crescita e allo sviluppo (compaiono infatti parole come "land", "smart growth", "development", "state", "developer"), un secondo riguardante l'aspetto ambientale/politico ("resources", "regional", "environment", "urban", "comunità") ed infine il terzo riguardante l'aspetto di ricerca ("research", "information", "document"). In questo modo è possibile notare quali argomenti sarebbe meglio sviluppare per affilare ulteriormente la ricerca.
Ricerca semantica di "planning" (pianificazione):
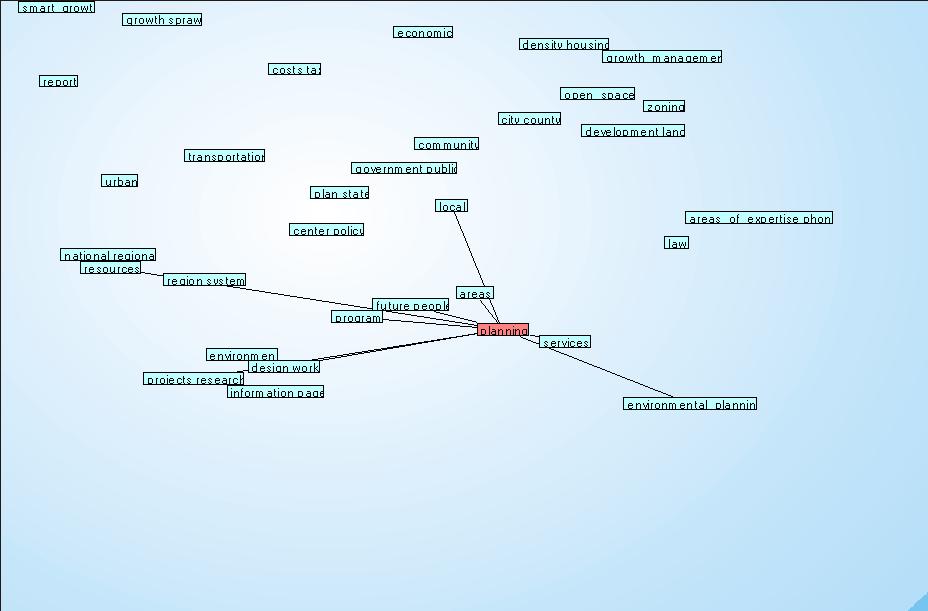 Cliccare sull'immagine per ingrandire
Cliccare sull'immagine per ingrandire
Ricerca semantica di "growth" (crescita):
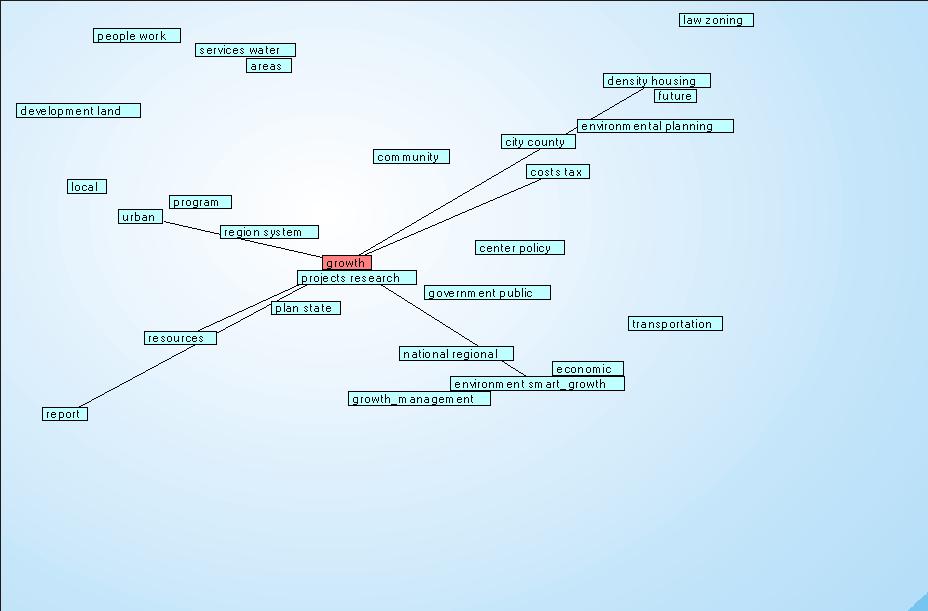 Cliccare sull'immagine per ingrandire
Cliccare sull'immagine per ingrandire
E' possibile operare varie elaborazioni statistiche, utilizzando la funzione statistique, esportando il file che viene creato in excel e costruendo grafici.
Tabella delle frequenze
Per queste due analisi si consiglia di ordinare prima di tutto le parole in ordine decrescente, poi di elaborare un grafico a forma di istogramma per meglio visualizzare la frequenza ed avere un'idea su quali siano i temi trattati più di frequente nei vari testi.
Tabella delle cooccorrenze
Per queste due analisi, dal momento che viene creato un foglio di lavoro che comprende una matrice quadrata dove i numeri all'interno indicano quanto sono "simili" le due parole o i cluster in considerazione (cioè quanto spesso sono trovati nella stessa frase o nello stesso tema). Non avendo a disposizione un software che realizzi grafici di dispersione adatte alla trattazione, si consiglia di eseguire vari grafici ad istogrammi scegliendo una riga od una colonna alla volta, di modo che risulti immediato vedere le parole che possono essere considerate vicine (cioè quelle a cui è associato un istogramma più alto) e quelle che possono essere considerate non "simili".
Il software Wordmapper è disponibile sul sito: www.grimmersoft.com.
![]()