
Gestione di basi di dati
Qualsiasi Ente pubblico o privato si trova oggigiorno di fronte ad una enorme quantità di dati che deve poter gestire (aggiornandoli continuamente) e su cui deve poter lavorare in modo veloce. Per questo nasce la necessità di informatizzare i dati in modo efficiente.
Una base di dati e un insieme di dati che vengono organizzati e gestiti da un sistema software preciso: il DBMS ( DataBase Management System ).
Il DBMS è in grado di gestire collezioni di dati che siano grandi, condivise e persistenti, assicurando la loro affidabilità e privatezza.
Come ogni prodotto informatico, un DBMS deve essere efficiente ed efficace.
Una base di dati è una collezione di dati gestita da un DBMS.
Si precisano le caratteristiche dei DBMS e delle basi di dati che sono alla base delle definizioni date in precedenza.
Le basi di dati possono essere grandi nel senso che possono avere anche dimensioni enormi e comunque in generale dimensioni molto maggiori della memoria centrale disponibile. Ovviamente possono esistere anche basi di dati piccole ma i sistemi debbono poter gestire i dati senza porre limiti alle dimensioni, a parte quelle fisiche dei dispositivi.
Le basi di dati sono condivise, nel senso che applicazioni e utenti diversi debbono poter accedere, secondo opportune modalità, a dati comuni. E importante notare che in questo modo si riduce la ridondanza dei dati poiché si evitano ripetizioni.
Le basi di dati sono persistenti cioè hanno un tempo di vita che non è limitato a quello delle singole esecuzioni dei programmi che le utilizzano.
I DBMS garantiscono affidabilità cioè la capacità del sistema di conservare sostanzialmente intatto il contenuto della base di dati in caso di malfunzionamento hardware e software.
I DBMS garantiscono la privatezza dei dati. Ciascun utente viene abilitato a svolgere solo determinate azioni sui dati attraverso meccanismi di autorizzazione.
Per efficienza si intende la capacità di svolgere le operazioni utilizzando un insieme di risorse (tempo e spazio) che sia accettabile per gli utenti.
Per efficacia si intende la capacità della base di dati di rendere produttive in ogni senso, le attività dei suoi utenti.
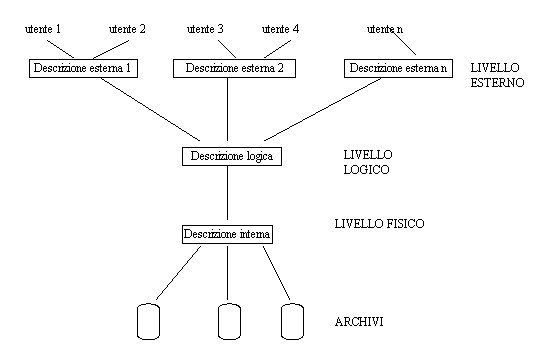
Un DBMS fornisce ai suoi utilizzatori una visione astratta della base di dati:
LIVELLO FISICO: descrive la base di dati come un insieme di elementi contenuti nella memoria di massa;
LIVELLO LOGICO: evidenzia lorganizzazione dei dati dal punto di vista del loro contenuto informativo, descrivendo la struttura di ciascun dato e i collegamenti tra dati diversi;
LIVELLO ESTERNO: i dati così come vengono descritti da un particolare utente.
I principali modelli dei dati dei DBMS includono:
MODELLO GERARCHICO:basato sulluso di strutture ad albero (e quindi gerarchie,da cui il nome), definito durante la prima fase di sviluppo dei DBMS (anni Sessanta),ma tuttora ampiamente utilizzato;
MODELLO RETICOLARE: e sorto come estensione del linguaggio di programmazione Cobol per la gestione di strutture dati complesse. Il modello reticolare e basato sui grafi, ovvero sulle strutture dati a reticolo.
MODELLO RELAZIONALE: e basato sul concetto di insieme e sulla strutturazione dei dati tramite tabelle.
MODELLO A OGGETTI: sviluppato a partire dal 1985, caratterizza i DBMS di nuova concezione. Esso estende alla base di dati alcune caratteristiche dei linguaggi di programmazione orientati ad oggetti.
I modelli più utilizzati al momento risultano essere i database relazionali, perché caratterizzati da una definizione estremamente compatta ed elegante; quindi nella nostra applicazione si sono presi in considerazione questi tipi di modelli.
BASE DI DATI RELAZIONALE
Consente di organizzare i dati in insiemi a struttura fissa.
Una relazione viene spesso rappresentata per mezzo di una tabella, le cui righe rappresentano specifici record e le cui colonne corrispondono ai campi del record; lordine delle righe e delle colonne è sostanzialmente irrilevante
|
|
Nome |
Cognome |
Indirizzo |
Telefono |
|
Record 1 |
Giuseppe |
Garibaldi |
Via dei Mille |
123456 |
|
Record 2 |
Mario |
Rossi |
Vicolo Corto 1 |
7890 |
La costruzione di una base di dati e un' operazione particolarmente critica, in cui il progettista deve poter prevedere con accortezza la struttura dati che meglio si adatta alle esigenze di applicazione della base di dati.
Il programma più diffuso per la CREAZIONE, lINSERIMENTO DI NUOVI DATI,la CANCELLAZIONE e lINTERROGAZIONE di un database è MICROSOFT ACCESS.
Un file di database (.mdb) in Microsoft Access può essere composto da varie tabelle e può essere progettato in modo tale da memorizzare le informazioni relative alle relazioni tra le varie tabelle con notevole risparmio di tempo per la fase di ricerca e una bassa probabilità di immettere dati errati.
Si riporta di seguito la terminologia che sarà necessaria per meglio comprendere le operazioni svolte nellesempio :
TABELLA (table): è un insieme di dati relativi ad uno stesso argomento. I dati di una tabella vengono presentati in forma tabellare ovvero suddivisi in colonne e righe. Le colonne vengono denominate campi e le righe record.Tutti i dati di una tabella descrivono loggetto della tabella.
CAMPO (field): rappresenta una categoria di informazioni .
RECORD : è un insieme di informazioni relative ad una determinata persona, cosa o ad un determinato evento. Ciascun record di una tabella contiene lo stesso insieme di campi e ciascun campo contiene lo stesso tipo di informazioni per ciascun record.
QUERY : è una domanda che viene posta in relazione ai dati presenti nel database. I dati che forniscono una risposta a questa domanda potrebbero provenire da una o più tabelle.La query che descrive il set di dati desiderati viene definita dallutente stesso.
DYNASET : si tratta delle varie informazioni che vengono raggruppate tramite una query; è perciò un set di record, definito da una tabella o da una query, che è possibile aggiornare.
MASCHERA (mask) : rappresenta in genere il layout più adatto per limmissione , la modifica e la visualizzazione dei record dei database.Durante la progettazione della scheda viene specificato il modo in cui i dati verranno visualizzati o stampati. Quando si apre una scheda, verranno estratti i dati dalle tabelle e visualizzati nel layout definito dall utente.
REPORT : viene utilizzato per stampare i dati nel modo più accurato possibile e presentare totali parziali e totali complessivi di un intero gruppo di record.
MACRO : consentono di automatizzare le operazioni fondamentali e di combinare insieme i vari oggetti senza alcuna programmazione. E un elenco di azioni che si desidera far eseguire al programma. E per esempio possibile aprire automaticamente un gruppo di schede contemporaneamente allapertura del proprio database. Può essere utilizzata in più punti del database. E possibile collegare una macro ad una scheda, ad un report o al comando di un menu.
MODULO (modul) : è un oggetto che contiene le procedure di Access Basic un potente linguaggio di programmazione interno.
I database hanno molte applicazioni, sono utilizzati sia da amministrazioni pubbliche che private per poter gestire dati economici, finanziari, sociali, commerciali e territoriali.
Questultima applicazione di un database, ovvero quella territoriale, è quella che verrà analizzata e descritta di seguito.
Lobiettivo che ci si propone di realizzare è di informatizzare dati, statistiche e tabelle che riguardano il territorio e i soggetti che operano su di esso in modo da poter cercare, modificare, interrogare e estrapolare campi, usando parole chiave e vari comandi, in modo veloce ed efficiente.
I database territoriali sono strumenti che possono fornire, se ben strutturati, un valido aiuto nella comprensione delle problematiche di un area di studio. Sono molto versatili in quanto consentono un adeguata analisi dello stato di fatto e l'estrapolazione di funzioni che permettono di prevedere andamenti tipici delle entità territoriali.
Un database territoriale può avere come oggetto il territorio ( quindi il comune, la provincia, il bacino idrografico ) e rispetto a questo definire gli elementi puntuali( n° abitanti, n° abitazioni, vulnerabilità idrogeologica ) e gli elementi relazionali (flusso pendolari, immigrati, emigrati, ) che lo caratterizzano.
Loggetto però può anche essere lentità individuo rispetto a cui definire gli elementi puntuali ( codice fiscale, data di nascita, comune di residenza, ) e relazionali ( comune di residenza , comune di lavoro ).

I database territoriali:
possono essere riferiti a diversi settori quali :
Trasporti
Sanità
Catasto
Idrogeologia
Uso del suolo
Popolazione
possono essere costruiti in modo da contenere dati riferiti a qualunque scala spaziale:
Scala comunale (anagrafe,reddito,..);
Scala provinciale (reddito,popolazione,..) ;
Scala di bacino (analisi acque e corsi d'acqua,..);
Scala regionale (dati territoriali,..);
Scala nazionale (rete trasporti,..);
Scala sovranazionale (es. rete ciclabile europee,..);
Per la costruzione di un efficace database, molta attenzione va posta allo studio e al tipo di dato da utilizzare.
I dati devono avere le seguenti caratteristiche:
COERENTI E COMPARABILI, per permetterne un facile utilizzo e per non avere problemi nel confrontarlo. Spesso si procede quindi alla normalizzazione del dato stesso affinché sia paragonabile ed integrabile con le banche dati di più grande utilizzo (della Regione, del Comune, della Camera di Commercio, dell ISTAT, ecc.).
OMOGENEO, con la stessa fonte di provenienza, con la stesa coerenza nelle definizioni, con uguali criteri di aggregazione, con stessi intervalli temporali e stessa numerosità Devono essere raccolti per uno SCOPO PRECISO, affinché si sia sicuri che il tipo di dato raccolto con tutte le specifiche del caso, e nel modo desiderato (questionario, inchiesta pubblica, ecc)
Devono essere in un formato DI FACILE AGGIORNAMENTO, per essere utile in ogni momento e non fine a se stesso in un preciso momento storico.
Il metodo di raccolta deve essere NOTO e TRASPARENTE, affinché si riesca a risalire a come è stato raccolto.
ACCESSIBILE: questo non è semplicemente una questione fisica, ma un problema di interesse e di risonanza. Troppo spesso linformazione non è comprensibile a tutti gli utenti oppure non ha alcun interesse diretto per grosse parti della comunità, quindi si deve cercare di adattare linformazione ad un pubblico più vasto e rappresentare i dati più chiari possibile.
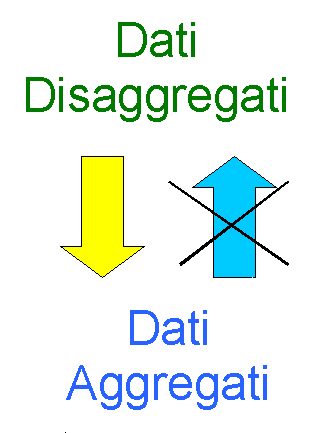
Conviene sempre possedere dati il più possibile disaggregati con la possibilità di ottenere quelli aggregati (indicatori). I dati disaggregati sono i più difficili da reperire perché richiedono un notevole sforzo di tipo economico.
Queste
specifiche sul dato sono oggigiorno fondamentali per non essere paradossalmente
sommersi da una enorme quantità di informazione che complica il processo
decisionale se a questa non è associata una ricerca della qualità su come
viene recepito il dato.
Nella
maggior parte dei casi,il problema non è la mancanza di dati, bensì dove
reperirli e come trattarli.
Per avere dati sicuri sono stati creati degli enti od organismi statali e privati che si occupano da sempre di raccogliere dati:
ENTI ISTITUZIONALI, ISTAT, Ministeri, Regioni, Province, Comuni
ENTI PUBBLICI o TITOLARI DI SERVIZIO PUBBLICO: Camere di Commercio, ACI, CISPEL ENEL, INAIL, TELECOM, RAI .
SOCIETA E ASSOCIAZIONI DI CATEGORIA: Associazioni, Consorzi
STRUTTURE SCIENTIFICHE: CNR, Università, CENSIS, Fondazioni..
Esistono altri tipi di informazioni utilizzabili nelle basi di dati, questi vengono denominati metadati:
I metadati sono definiti come data about
data , ovvero, dati sui
dati e, in altre parole, dati utilizzati per descrivere altri dati. I
metadati sono quindi le informazioni che descrivono la forma ed il contenuto
dell oggetto cui si riferiscono.
La funzione dei metadati è quella di
permettere (o comunque facilitare) il raggiungimento dei seguenti obiettivi:
Ricerca, ovvero saper individuare l'esistenza di un documento primario.
Localizzazione, ovvero poter rintracciare una particolare versione del documento primario.
Selezione, ovvero analisi, valutazione e filtro di una serie di documenti primari senza dover accedere al loro contenuto.
Gestione
delle risorse informative, ovvero poter gestire le raccolte di
documenti primari grazie a strumenti come banche dati o cataloghi.
Tra i vari metadati che esplicano meglio un
dato è richiesta, dalle norme europee, la presenza di almeno un Quality
Element che descrive, appunto, la qualità del dato. In tutto si hanno a
disposizione quattro elementi di qualità:
la discendenza, ossia la descrizione della storia dell'insieme dei dati;
lutilizzo, ovvero
linsieme delle applicazioni per le quali il dato è stato utilizzato;
i parametri di qualità
che indicano le caratteristiche dellinsieme dei dati confrontate con un
campione ideale di riferimento;
lomogeneità,
consistente in una descrizione testuale e qualitativa di uniformità dei
parametri di qualità
Nella gestione dei database risulta fondamentale riconoscere il livello di aggregazione dei dati a disposizione .
A seconda del tipo di aggregazione è possibile ottenere un certo tipo di informazione.
I dati di partenza ottimali sono ovviamente quelli disaggregati, come ad esempio, nella nostra applicazione di tipo censuaria sulla popolazione, i dati individuali.
Come è stato evidenziato nellesempio è possibile ottenere qualsiasi tipo di informazione a partire dai dati disaggregati .
|
Individui |
Classi di età |
Istruzione |
Stato occupazionale |
Settore di occupazione |
Comune di residenza |
Comune di lavoro |
|
1 |
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
|
|

|
Comune di residenza |
Popolazione residente |
|
1 |
|
|
|
|
|
k |
|
Loperazione sopra illustrata è possibile in quanto il contenuto informativo di un database disaggregato è sicuramente superiore a qualsiasi database che contiene dati aggregati.
Bisogna tenere presente lo scopo che si propone nella creazione di un database : creare un database per entità richiede un costo significativo in termini economici e di tempo che può non essere giustificato dallobiettivo dellanalisi.
Ad esempio se lobiettivo è determinare gli spostamenti complessivi tra comuni non sarà necessario reperire dati individuali ma solamente dati aggregati secondo comune di origine e destinazione; se lo scopo è invece conoscere gli spostamenti secondo il mezzo di trasporto sarà fondamentale ricavare dati ad un livello di aggregazione inferiore.
E evidente che interrogare una tabella di dati aggregati non consente di riottenere le informazioni disaggregate.
|
Comune di residenza |
Popolazione residente |
Settore occupazionale |
|
1 |
|
|
|
|
|
|
|
k |
|
|
|
Individui |
Classi di età |
Istruzione |
Stato occupazionale |
Settore di occupazione |
Comune di residenza |
Comune di lavoro |
|
1 |
|
|
|
| ||
|
2 |
|
|
|
| ||
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
http://www.istat.it/ Istituto Nazionale di Statistica
http://www.ring.lombardia.it/ Annuario statistico Regionale Lombardia
http://cens.istat.it/ Censimento intermedio dellindustria e dei servizi
http://demo.istat.it/ Statistiche demografiche Popolazione residente comuni italiani
http://cidoc.iuav.it/sintesi/ Servizio statistico che riporta dati istat a livello nazionale
http://www.lom.camcom.it/ Camere di commercio (Lom)
http://netserv.mnet.it/upitel/ Rete telematica delle province italiane
http://www.provincia.milano.it/ambiente/acquesuolo/acquesuperficiali/sias.html Sias(sistema informativo acque superficiali) Milano
http://www.provincia.milano.it/progettispeciali/sif/piezometrie.htm sistema informativo falda Milano
http://www.adbpo.it/ Autorità di bacino fiume Po
http://www.lom.camcom.it/dati/aspo/ Archivio statistico provinciale delloccupazione in Lombardia
http://www.tagliacarne.it/cidel/index.htm CIDEL (Centro Informatizzato di Documentazione sulle Economie Locali)
Siti
Stranieri
http://www.epa.gov/
EPA (United States Environmental Protection Agency)
http://www.epa.gov/eims/eims.html
EMIS (Environmental Information Management System)

 |
 |
 |
