Multa
renascentur quae iam
cecidere,
cadentque quae
nunc sunt in
honore
vocabula,
si volet
usus,
quem penes arbitrium
est et ius et norma
loquendi.
(Quinto Orazio
Flacco, Arte Poetica, vv.70-72)
Molti vocaboli che già
morirono rinasceranno, e cadranno quelli che ora sono in onore, se lo vorrà
l’uso, nel cui potere stanno il dominio, la legge e la norma nel parlare.
0.1....... Motivazioni e scopo della tesi
I. La lessicografia e i corpora
linguistici
1.1.1.
Definizione di corpus linguistico
1.1.2.
Strutturazione di corpora significativi
1.2. L’ Oxford Dictionary of New Words
1.2.2. Descrizione dell’ Oxford Dictionary
of New Words
II. Lessico e neologismi dell’ ODNW
2.3.1.
Cambiamenti di significato
2.3.2.
Innovazioni vere e proprie
3.2. Stuttura interna delle parole
3.5.1.
Abbreviazioni (Clipping)
3.5.3.Retroformazione
(Backformation)
L’analisi
dell’ ODNW nasce dal mio interesse per la lingua in generale, la sua evoluzione,
il suo essere sintomo di cambiamento nelle aree economiche e sociali. In
particolare ero interessata alla misurazione, se così si può dire,
dell’innovazione, della novità.
Si tratta
di una tesi sperimentale in cui da un lato si sono esaminate esaustivamente e
dettagliatamente le tipologie linguistiche esistenti (semantiche e
morfologiche), presentando una lista di tutti i lemmi presenti nel dizionario
per ciascuna tipologia indicata; dall’altro lato si è utilizzata una
metodologia sperimentale che ha permesso di sintetizzare statisticamente e
quantitativamente i fenomeni, attraverso la realizzazione di un software creato
per tale scopo.
L’ODNW,
così come la maggior parte dei dizionari odierni della lingua inglese, è stato
realizzato grazie ad un corpus linguistico, ovvero una raccolta di testi che
includano conversazioni, articoli di riviste, quotidiani, discorsi, e qualsiasi
tipo di documento che sia rappresentativo della lingua in oggetto, a cui
vengono assegnati degli identificatori, in modo che tale materiale possa essere
immagazzinato su supporti leggibili dal computer.
Sulla base
di queste conoscenze ho avuto l’idea di realizzare un software che mi ha
permesso di analizzare dal punto di vista statistico e quantitativo il
dizionario in questione.
Il software
(chiamato Lexiscan e presente sul server di Lingue all’indirizzo: http://www.lingue.unige.it/azzaro.g/files/students.html, insieme con un esempio di file di input e di output) è stato
realizzato da un tecnico informatico utilizzando il linguaggio di
programmazione C.
Vorrei
illustrare brevemente le procedure seguite per la realizzazione di tale
software.
Inizialmente
tutte le parole contenute nel dizionario sono state inserite manualmente sotto
forma di elenco in modalità testo formato Word 97. Per far funzionare il
software il file newword.doc è stato
successivamente convertito in formato testo modalità MS DOS, con il nome alfab.txt. Ad ogni parola è stato assegnato un identificatore per indicare la
categoria semantica, uno per la categoria grammaticale e uno per la tipologia
di formazione di parola. In particolare è stata assegnato numero per ciascun
campo ideologico-semantico (1-11), una lettera per indicare la categoria
grammaticale (N per nome, A per aggettivo, …), un simbolo per la formazione
delle parole ( # prefissi, + composti, & fusione,…).Il file alfab.txt, con i relativi
identificatori, è stato diviso in 5 file di 708 parole ciascuno, a causa di una
limitazione della struttura del software.
La
struttura utilizzata dalla source (sorgente)
Lexiscan e' stata orientata a matrici
bidimensionali, in quanto, la velocita' di elaborazione e' molto piu' veloce di
qualsiasi altra struttura, previe dimensioni abnormali del file procurato
dall'utente.
I tre
obiettivi sono stati inseriti in tre matrici distinte e elaborati con calcoli statistici. Il risultato finale, una
volta inserito in una matrice globale, viene ricopiato su un file di
destinazione, creato dal sorgente (Lexiscan) stesso.
Per
accedere al programma l'utente deve fornire il NOME del suo file, formattato in
modalita' testo MS DOS (.txt), per una agevolazione in lettura del programma;
deve poi invocare l'eseguibile, seguire le istruzioni che compariranno e il risultato
sara' contenuto in un file a parte.
In altre parole il software opera automaticamente un
conteggio dei lemmi e li suddivide secondo
1.
l’appartenenza ad un
determinato campo ideologico o semantico (v. cap.2 par. 2.3.3.);
2.
l’appartenenza di una parola
ad una determinata categoria grammaticale (v.cap.3);
3.
la formazione della parola
nella lingua inglese (v.cap.3).
Quindi
salva automaticamente i risultati in file in modalità testo MS DOS (.txt).
I
risultati, ottenuti in 5 file separati, vengono inseriti in un unico file (con
i comandi copia/incolla), che fornisce il totale dei risultati ottenuti.
Si procede
quindi alla creazione di tavole e tabelle che forniscono un quadro dettagliato
della situazione e con la realizzazione di appositi grafici che permettono una
chiara visione ottica di lettura dei risultati.
Quali sono
i risultati di questa indagine?
La lingua inglese possiede un vocabolario
estremamente ricco e vario che si rinnova continuamente attraverso
l’arricchimento di nuove forme e l’eliminazione di altre cadute in disuso
all’interno del sistema lessicale della lingua: grazie a questi fenomeni si ha
il mantenimento della funzione comunicativa del linguaggio tra i parlanti di
una data epoca.
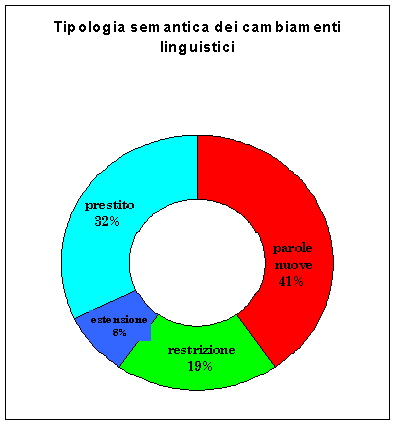
La nostra analisi dimostra che i fenomeni
profondamente innovativi sono pochi e marginali: i più rilevanti si hanno nel
campo della neologia semantica con l’accoglimento di foresterismi ad
adattamento fonomorfologico, e con veri e propri cambiamenti di significato.
In particolare abbiamo osservato che lo sviluppo
di un nuovo significato che porta alla formazione di un nuovo elemento, avviene
soprattutto attraverso la reinterpretazione dell’elemento iniziale del termine
più frequente nell’uso comune della lingua. Ad esempio:
toast “pane tostato; brindisi” oggi indica “un
tipo di lunga poesia narrativa recitata in estemporanea”.
Interessante appare un unico caso di
adattamento fonomorfologico, con semplificazione ortografica: si tratta di
youth (gioventù), che è diventato yoof, proprio come in passato gaol (prigione) è diventato jail.
Inoltre il notevole
sviluppo della ricerca scientifica e tecnologica, la specializzazione degli
ambiti disciplinari, la disponibilità di circolazione immediata delle
conoscenze sono solo alcuni tra i principali fattori che hanno determinato nel
corso del nostro secolo la coniazione di un grande numero di termini
tecnico-scientifici e la loro diffusione nell’ambito del vocabolario di cerchie
sempre più vaste di parlanti.
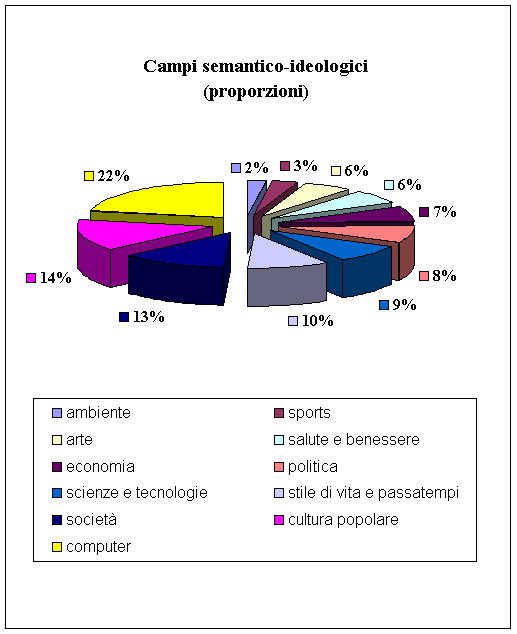
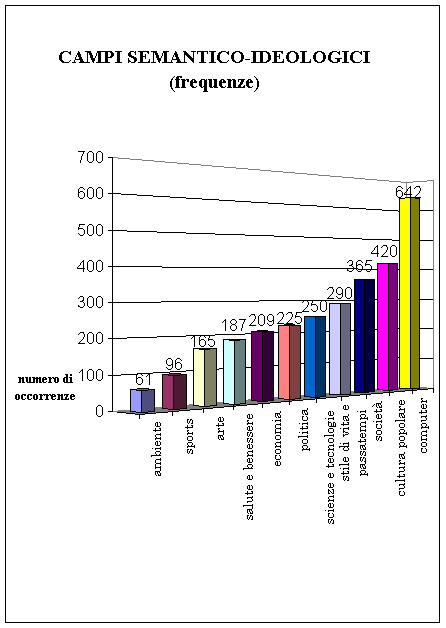
Considerando quindi a quale campo ideologico
appartengono le parole notiamo che si ha una netta prevalenza di parole che
riguardano l’area del “computer”, a causa, ovviamente, dello sviluppo
dell’informatica. Seguono la “cultura popolare”, e le “espressioni
colloquiali”, mentre di minor rilevanza sono i lemmi che riguardano l’area
ambientale”.
Se poi consideriamo nel complesso il lessico
e la formazione delle parole, prescindendo dalle basi lessicali (la cui
nascita, o morte, dipende fondamentalmente da fatti e da cambiamenti della
società, del pensiero e della cultura materiale), la norma e il sistema della
lingua inglese paiono orientarsi secondo due tendenze fondamentali:
1. da un lato la preferenza per espressioni sintetiche invece che
analitiche (composizioni, sigle, prefissazioni e suffissazioni; ad esempio foodie “buongustaio”, multi-culti “multi-culturale”, DDC “cassetta compatta digitale”);
2. dall'altro lato la
concentrazione su una lista non ampia di formativi- prefissi e suffissi- molto
produttivi e polifunzionali, come ad esempio: e-mail “posta elettronica”, bootable
“avviabile”, sustainable “riciclabile”.
Molti neologismi inoltre sono il risultato
della nominalizzazione di verbi frasali, ad esempio troviamo add-in (qualcosa che si aggiunge ad un
computer o ad un altro sistema per aumentare la sua capacità o prestazione), cash back (possibilità offerta da un
dettagliante ad un cliente di ritirare una piccola somma quando compie
un’operazione di credito o addebito: l’ammontare viene aggiunto al conto), opt out (possibilità di svincolarsi da
una regola, una clausula, ecc.).
Dal punto di vista quantitativo su un totale
di 2850 lemmi, il fenomeno della composizione tocca le 2320 parole, mentre per
la derivazione si contano 420 parole. E’ interessante notare che il cambiamento
semantico, sebbene sia il fenomeno linguistico più innovativo, consta solo di
110 parole.
Poiché il fenomeno della composizione è il
più rilevante ci sembrava opportuno mostrare i dati anche in relazione agli
altri processi morfologici.
Effettivamente osservando la tendenza nella
formazione delle parole è evidente che i composti rappresentano il fenomeno
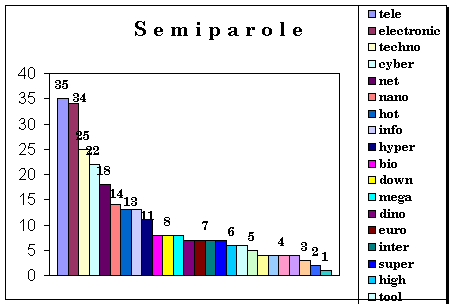
morfologico più rilevante. Con valori dimezzati seguono le semiparole e, con
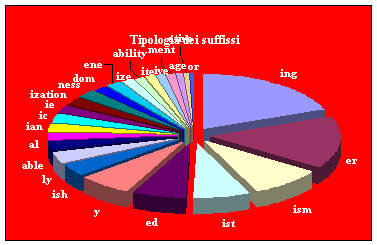
valori leggermente inferiori, i suffissi.
Di minor rilevanza, ma con risultati più
omogenei tra loro, troviamo i prestiti, i prefissi, le locuzioni e il fenomeno
della fusione.
I dati ricavati dagli studi precedenti sono
pochi e insufficienti per poter operare un reale confronto. Le teorie enunciate
in passato sono divergenti e contradditorie tra loro, anche perché numerose divergenze
e contraddizioni emergono tra i diversi autori. e, inoltre, sono state condotte
tutte su piani differenti.
Il linguista Geoffrey Leech è sorpreso dei
risultati ottenuti dalla mia ricerca ed afferma che probabilmente riflettono la
struttura stessa dei dizionari di nuove parole, che operano una selezione tra i
lemmi più interessanti in una data epoca. Infatti il nostro studio è il primo
tipo di ricerca che riunisce tutte le teorie enunciate fino ad oggi e descrive
la situazione attuale dell’inglese contemporaneo basandosi esclusivamente sull’
Oxford Dictionary of New Words.
In conclusione si può quindi discutere sulla
stessa definizione di dizionario di parole nuove.
Il concetto più importante è il “nuovo”. Che
cosa vuol dire nuovo? Qual’è il termine di paragone?
Il nostro dizionario in questo senso è
abbastanza vago, enuncia che si tratta di parole degli anni Ottanta-Novanta, ma
non stabilisce in base a quale fenomeno, a quale epoca, a quale termine di
paragone siano “nuove”.
Crediamo che ogni nuova compilazione di un
dizionario dovrebbe essere molto esplicita su questo piano in modo da fornire
una fotografia della realtà linguistica veramente oggettiva e non frutto di una
selezione basata su criteri soggettivi.
La ricerca, dunque, è aperta: si può
analizzare ancora il dizionario in maniera più dettagliata o trattare un unico
aspetto linguistico in tutte le sue caratteristiche, o osservare quali lemmi di
fatto resteranno in uso e quali scompariranno dentro 5 o più anni operando così
un reale monitoraggio dell’andamento della lingua inglese.