
1. Introduzione.
Questo articolo riassume l'attivita' della Texas Intruments Italia nel campo delle Memorie di Quadro o Field Memories (FMEM) per applicazioni televisive. Tale attivita', che la Texas Instruments Italia intende continuare nel prossimo futuro, prese le mosse nel 1991 da una famiglia di prodoti similari sviluppati dalla consorella giapponese, sviluppandosi poi in maniera del tutto autonoma ed originale. In particolare, viene descritto l'ultimo dispositivo della famiglia di FMEM progettate e prodotte in Italia: il TMS4C2972/3, realizzato in tecnologia 16Mbit DRAM.
Come evidenziato in figura 1, la TI e' presente in questo particolare mercato da molti anni, con una serie di dispositivi via via piu' complessi ed adatti a soddisfare esigenze applicative piu' sofisticate, ma comunque tra loro compatibili verso il basso (sia in termini di prestazioni che di pin out), cosi' da evitare problemi di discontinuita' nell'approvviggionamento per i clienti.E' gia' in fase di definizione un ulteriore dispositivo, molto flessibile ed adatto alle piu' svariate applicazioni, chiamato per ora UvFM (Universal Field Memory), che, si prevede, dovrebbe essere l'ultima memoria di questo tipo. Infatti, dai primi anni del prossimo decennio, e' probabile che la tecnologia permetta di integrare in un unico chip sia la memoria che la logica di processo di segnale (DSP con memoria DRAM 'embedded')
2. Le FMEM e le loro applicazioni.
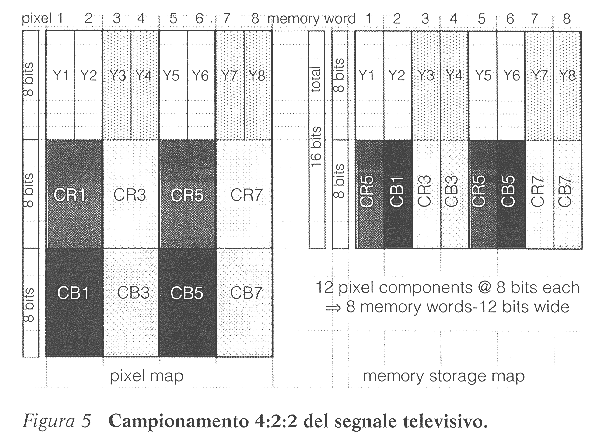
Per capire la necessita' di una Memoria di Quadro nei televisori, bisogna rifarsi allo standard di trasmissione televisivo. Il sistema PAL, per esempio, trasmette 625 linee (di cui 575 utili) per quadro, suddivise in due semi-quadri di 312.5 (287.5 utili) linee ciascuno. Nel primo semi-quadro sono trasmesse tutte le linee 'dispari' dell'immagine completa e nel secondo semi-quadro sono trasmesse tutte le linee 'pari' della stessa immagine. L'occhio provvede poi a 'ricostruire' l'intero quadro per mezzo del fenomeno della persistenza dell'immagine sulla retina. La frequenza di trasmissione dell'immagine e' di 25Hz (50Hz, se si prende in considerazione il semi-quadro), al limite della percezione del movimento dell'occhio umano, e pone non pochi problemi di qualita', specialmente nel caso di schermi televisivi di grandi dimensioni. Il fenomeno piu' vistoso e' quello del tremolio dell'immagine nel suo complesso (large area flicker). Un altro fenomeno, legato invece all'alternarsi delle linee pari e dispari nei due semi-quadri successivi, e' il tremolio delle linee orizzontali (line flicker). L'uso delle FMEM permette non solo una significativa riduzione dei difetti suddetti, ma anche una netto miglioramento del rapporto segnale/rumore, mediante l'uso di tecniche del trattamento digitale del segnale.



3. La Field Memory TMS4C2972/3.
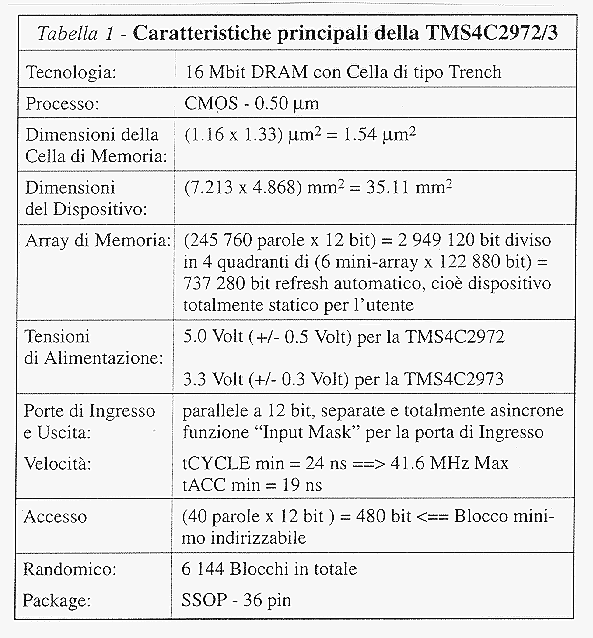
La Field Memory TMS4C2972/3 e' l'ultima nata della famiglia di FMEM della Texas Instruments ed e' basata sulla tecnologia della 16Mbit DRAM.

Si tratta in realta' di due dispositivi che differiscono tra loro soltanto per la tensione di alimentazione: 5 Volt per la TMS4C2972 (Figura 6) e 3.3 Volt per la TMS4C2973. In Tabella 1 ne sono riassunte le principali caratteristiche tecniche e funzionali.
3.1. L'architettura del dispositivo.

Con riferimento alla figura 7, la memoria centrale e' suddivisa in quattro quadranti, ciascuno dei quali contiene sei matrici di celle di memoria da 256 righe e 480 colonne. Lungo due lati di ciascuna matrice, parallelamente alle righe, sono disposti 240 sense-amplifiers a cui afferiscono, alternativamente sui due lati, le 480 colonne. In particolare, i sense amplifiers adiacenti a due matrici sono condivisi dalle colonne di tali matrici, essendo collegabili alle colonne dell'una o dell'altra matrice per mezzo di opportuni selettori. Un qualunque accesso alla memoria centrale avviene selezionando una riga per quadrante ed attivando i sense-amplifiers adiacenti alle matrici a cui appartengono le righe selezionate. Ogni accesso coinvolge quindi tutte le celle di memoria, relative alle righe selezionate, le quali possono essere scritte, lette o riscritte (refresh) attraverso i sense-amplifiers. Mentre nel caso del refresh tutte le 480 celle di memoria per riga selezionata vengono coinvolte nell'operazione, nel caso delle operazioni di scrittura e di lettura l'accesso si limita solo ad un quarto di dette celle ed avviene per mezzo di 120 linee di dati che, correndo orizzontalmente sopra un intero quadrante, collegano, tramite opportuni selettori, un sense-amplifier ogni quattro tra quelli attivati in base alla riga selezionata, con due memorie tampone disposte verticalmente sui due lati di ciascun quadrante, cioe' con la parte 'master' dei Data Register. Ai lati di ciascun quadrante sono presenti sessanta registri completi della parte 'slave' e dei relativi puntatori di indirizzamento (in particolare, le linee di dati di ordine pari sono collegate ai registri disposti su di un lato del quadrante mentre quelle di ordine dispari afferiscono ai registri disposti sull'altro lato del quadrante), per un totale di 120 registri per quadrante e 480 in tutto il dispositivo. Tale gruppo di registri, corrispondenti a un totale di 40 parole di 12 bit, e' l'unita' minima di memoria accessibile separatemente nella TMS4C2972/3 ed e' detto 'blocco'. Ciascun registro e' diviso in due parti, una che esegue le operazioni relative alla scrittura in Memoria, l'altre quelle relative alla lettura, di un singolo bit. In scrittura (parte inferiore della figura 8), ciascun registro e' caricato sequenzialmente attraverso l'ordinata abilitazione delle pass-gate 'Write Address Pointer'. Dopo 40 cicli del Clock di scrittura tutti i (40x12) = 480 registri sono stati caricati ed il loro contenuto viene scaricato in parallelo mediante le pass-gate WMS nello stadio Slave di ciascuno di essi, in modo che il caricamento dei dati sequenziali possa continuare. I dati permangono nello Salve fino a che l'Array di Memoria non sia libero da altre operazioni ed in grado di eseguire una scrittura in parallelo dei 480 dati, mediante i segnali e le pass-gates WREQ e PRE_.

Il lettura (parte superiore della figura 8), la procedura e' simmetrica: mentre i dati sono letti sequenzialmente dallo Slave mediante l'ordinata abilitazione della pass-gate 'Read Address Pointer', il Master del registro viene caricato in parallelo da una operazione di lettura dall'Array di Memoria, attraverso le pass-gate RCM. Ogni 40 cicli del Clock di lettura i registri Slave vengono caricati in parallelo dai relativi Master (attivazione delle pass-gate RMS), per poter proseguire la lettura sequenziale. Quando una richiesta di Reset Read (ripartenza della lettura dall'indirizzo zero) viene inoltrata al dispositivo, l'Array di memoria potrebbe risultare occupato in altre operazioni, ma, in questo caso, la FMEM non ha a disposizione i normali 40 cicli di Clock di lettura per effettuare l'operazione richiesta. Per evitare l'attesa (read latency), i registri di lettura sono provvisti di doppi Master (Cache), che hanno il compito di memorizzare il primo Blocco di 40 parole, in modo da renderlo immediatamente disponibile. Infine la funzione di Input Mask. Questa e' realizzata mediante l'approccio del read_before_write. Ad ogni operazione di scrittura nell'Array di Memoria, viene premessa una operazione di lettura, il cui risultato non viene pero' trasferito nei Master dei registri di lettura. I dati cosi letti vengono utilizzati, mediante la pass-gate Mask, per modificare quelli provenienti dai registri Slave di scrittura, a seconda se il dato in questione debba essere mascherato (dato valido quello gia' residente in memoria ed appena riletto) oppure no (dato valido quello proveniente dallo Slave). I Data Register assolvono cosi' alla funzione di interfaccia tra la memoria centrale e il resto della circuiteria logica CMOS, consentendo di leggere o scrivere 120 bit alla volta da ciascun quadrante per un totale di 40 parole, di parallismo 12 bit, sui quattro quadranti di cui si compone la memoria centrale. Se da un lato, verso la memoria centrale, tutti i registri di dati operano in parallelo, dall'altro, verso l'esterno, tali registri sono letti e scritti sequenzialmente. L'architettura del dispositivo consente di suddividere i 12 bit che compongono una parola in 4 gruppi da 3 bit ciascuno e di associare univocamente ad ogni gruppo di 3 bit due gruppi di Data Register disposti sullo stesso asse verticale. In pratica, solamente per quanto riguarda il trasferimento dei dati da e verso i Data Register, e' possibile rivedere il dispositivo come la giustapposizione di 4 unita' identiche operanti ciascuna su 3 bit. Questa architettura, rispetto ad una tradizionale, traendo vantaggio dalla vicinanza degli elementi tra i quali i dati vengono scambiati (principio di localita') consente una cospicua riduzione nel numero e nella lunghezza dei collegamenti (routing) che si riflette in un aumento delle prestazioni (minori capacita' parassite) e in un risparmio in termini di area di silicio.
3.2. La funzione dell'Arbitro.
Come detto, quella dell'Arbitro e' una funzione tipica e caratteristica delle FMEM, che provvede a risolvere i conflitti di accesso all'Array di Memoria. Vi sono cinque tipi di richieste di accesso all'Array di Memoria, controllate da tre differenti oscillatori, che possono giungere contemporaneamente: Reset Write, Write di fine Blocco, Reset Read, Read di fine Blocco, Refresh. La seconda e la quarta sono controllate rispettivamente dai Clock (esterni ed asincroni) di scrittura e lettura, ed hanno entrambe periodicita' pari a 40 cicli del Clock di controllo. La prima e la terza sono anch'esse controllate rispettivamente dai Clock di scrittura e lettura ma sono aperiodiche e quindi equivalenti a segnali asincroni per l'Arbitro. Infine la quinta e' controllata dal terzo Clock che e' interno al dispositivo, ed e' usato anche come 'motore' dell'Arbitro. Nel caso peggiore di contemporaneita' di tutte le richieste, tenendo conto che le operazioni di scrittura in realta' prevedono un doppio accesso a causa dell'approccio read_before_write sopradescritto, l'arbitro deve eseguire sette accessi in Memoria nel tempo massimo di 40 cicli del piu' veloce dei Clock interessati. In altre parole, in (24ns x 40 cicli) = 960 ns, cioe' circa 137ns ad operazione (in realta' un po' meno, per tener conto dei necessari margini di progetto). Il tempo a disposizione per l'accesso in memoria, non risulta essere facilmente rispettabile, dato il tipo di tecnologia e il notevole numero di dati da gestire in parallelo, il che solitamente rallenta l'operazione di scrittura. Si e' cosi' preferito introdurre una rete a priorita' nell'Arbitro in modo da ridurre il numero massimo di operazioni da effettuare nel tempo di 40 cicli di Clock. In pratica, si e' notato che una operazione di Reset Read rende sempre inutile l'esecuzione di una eventuale operazione pendente di Read per fine Blocco, e che una operazione di Refresh puo' essere rimandata al successivo ciclo di 960ns senza che per questo il contenuto della memoria venga perduto. In tal modo e' sempre possibile ridurre il caso peggiore a soli 6 accessi e quindi aumentare a 160ns il tempo disponibile per una singola operazione.
4. Conclusioni.
La famiglia di dispositivi sopradescritta si e' rivelata molto utile al miglioramento della qualita' della ricezione del segnale televisivo. La Texas Instrumenta Italia e' convinta che nei prossimi anni la necessita' di FMEM aumentera' e la loro applicazione si diffondera' anche ai televisori a basso costo. Essenziale a questo scopo e' sia la riduzione del costo del dispositvo medesimo, sia la sua flessibilita', cioe' la possibilita' di servire con un sol prodotto diversi tipi di applicazioni e diversi sistemi di campionamento. La nuova FMEM di cui la TI sta definendo le caratteristiche insieme ai suoi maggiori clienti, va' appunto nella direzione di soddisfare queste esigenze del mercato.
Bibliografia [1] H. WATEROLTER. "Improved Picture Quality (IPQ): The full-option IPQ module". Report No. HTV/AN92007. Philips Product Concept & Application Laboratory. Hamburg. 1992 [2] B. LAUE, G. MLLER, J. WOHLERDT. "100Hz Flicker-free feature module with memory controller SAA9088". Report No. HTV9002. Philips Product Concept & Application Laboratory. Hamburg. 1990. [3] A. ZIEMER. "PALplus - Ready for Take-Off !". IFA 1993. [4] EBNER, MARCOM, RIEMAN, SILVERBERG, STOREY, VREESWIJK, WESTERKAMP. "PALplus - The European system for wide screen TV". IFA 1993. [5] E. D'AMBROSIO, M. FRAGANO, G. IMONDI, M. LANCIANO, S. MENICHELLI, G. NASO. "A 2.9 Megabit Field Memory Especially Suitable for PALplus Applications". IEEE Transactions on Consumer Electronics. August 1994. Volume 40. Number 3. pagg. 718-726. [6] . SKOWRONEK, G. IMONDI. "UvFM: A Universal Field Memory for Supporting a Large Range of Digital Video Applications". Texas Instruments Corporate R&D Conference. Plano (Texas). August 1996.Elio D'Ambrosio consegue la laurea in ingegneria elettronica nell'aprile 1989, presso l'Universita` "Federico II" di Napoli, con una tesi sperimentale sulle tecniche di stabilizzazione di tensione in alimentatori "switching". Segue poi un corso di formazione presso il centro studi dell'IRI-Finmeccanica di Roma, e viene assunto in Ansaldo Trasporti SpA. Nel 1990 e' assunto alla Texas Instruments Italia, in forza al dipartimento di Ricerca e Sviluppo, partecipando fin dall'inizio alla progettazione di dispositivi di memoria a semiconduttore. Membro della IEEE, Society on Consumer Electronics, Elio ha al suo attivo un brevetto rilasciato in U.S.A., e quattro articoli pubblicati su ICCE, IEEE e nelle proceedings della TI Asia-Pacific Technical Conference. Nel tempo libero, gioca al calcio e va in windsurf.
Giuliano Imondi e' nato a Pordenone nel 1948 e si e' laureato con lode in Ingegneria Elettronica presso l'Universita' di Napoli nel 1977. In Texas Instruments dal 1978, dove e' attualmente 'IC Design Project Manager', si e' sempre occupato di Ricerca e Sviluppo, acquisendo ampia esperienza di progettazione in tutte le tecnologie MOS. Ha al suo attivo numerose pubblicazioni e piu' di venti brevetti. Giuliano e' sposato ed ha un figlio. Numerosi i suoi interessi fuori del lavoro tra cui spicca l'amore per la Storia Romana, di cui e' un vero esperto.
Stefano Menichelli e' nato a Roma nel 1961. Ha conseguito la laurea in Ingegneria Elettronica nel 1988 presso la Facolta' di Ingegneria dell'Universita' "La Sapienza" di Roma. Dal 1990 lavora al Dipartimento di Ricerca e Sviluppo della Texas Instruments Italia come ingegnere progettista di circuiti integrati. Ha una consolidata esperienza nella progettazione circuitale di memorie a semiconduttore Flash EEPROM e DRAM. Ha partecipato allo sviluppo di numerosi dispositivi e per oltre due anni ha svolto la sua attivita' all'estero presso le sedi della Texas Instruments di Houston (USA) e di Miho (Giappone). E' al momento impegnato nello sviluppo della tecnologia per la produzione di memorie Embedded Flash EEPROM. Precedenti esperienze lavorative riguardano il campo dell'informatica e in particolare lo sviluppo di software per applicazioni scientifiche.
Giovanni Naso si e' laureato con lode in Ingegneria Elettronica presso l'Universita' di Roma nel 1983. Dal 1984 al 1987 ha lavorato nel settore Automazione Impianti presso la Videocolor-Thomson. Nel 1987 ha iniziato il suo lavoro presso il dipartimento di ricerca e sviluppo della Texas Instruments Italia. E' stato assegnato per due anni al dipartimento di progettazione di Memorie Non Volatili di Houston per lo sviluppo di memorie FLASH EEPROM. Nel 1991 e' stato membro di un team per la progettazione di memorie Multiplexed EPROM per applicazioni automotive. Dal 1992 al 1994 e' stato membro di un team per la progettazione di memorie di quadro per la televisione ad alta definizione. Attualmemte e' team leader di un gruppo di progettazione di memorie Embedded SRAM per applicazioni DSP.
Pasquale Pistilli si laurea in ingegneria elettronica nel Dicembre 1992 presso l'Universita' degli Studi di Roma "Tor Vergata" discutendo la tesi sperimentale "Progetto e realizzazione del sistema di correzione d'errore per una memoria di massa ad alta velocita'" sviluppata in collaborazione con il reparto R&D della Texas Instruments Italia. Collabora poi per circa un anno con la Texas Instruments come consulente esterno per la realizazzione di una memoria di massa con correzione d'errore basata su memorie Flash. Viene assunto presso il reparto R&D della Texas Instruments nel 1994 come progettista software per lo sviluppo di un sistema per il riconoscimento di caratteri manoscritti. Attualmente e' impiegato come progettista per lo sviluppo di memorie ROM e FLASH. Pasquale e' titolare di 3 brevetti e numerose pubblicazioni. Nel tempo libero gioca a calcio e si dedica alla coltivazione di bonsai.
Ulrich Skowronek e' nato a Berlino ed ha studiato Electrical Engineering in Germania e negli Stati Uniti, conseguendo un M.S.E.E. alla Northeastern University. In Texas Instruments, dopo aver lavorato nell'Engineering e nel Product Marketing, e' attualmente responsabile, come Business Development Manager per le Digital Video Memories, della definizione di future memorie dedicate alle applicazioni video. In precedenza, Ulrich ha lavorato per il Ministero della Ricerca e Tecnologia della Germania, per la Digital Equipment Corp. e per il Massachusetts Institute of Technology. Ulrich e' sposato ed ha due figli.
Due livelli indietro alla mia home page
Un livello indietro alla pagina degli articoli