Il Resource Description Framework RDF
permette agli utenti di descrivere sia i documenti web sia i concetti della vita reale delle persone, organizzazioni,
concetti e cose in una maniera trattabile dai computer.
Pubblicare queste descrizioni sul Web permette di creare il Web Semantico.
Gli URIs (Uniform Resource Identifiers) sono molto importanti e forniscono sia il punto focale del Framework sia i
collegamenti tra il Web e il RDF. Questo documento presenta le linee guida per il loro uso efficace.
Tratta in particolare due strategie, definite 303 URIs e hash URIs. Fornisce riferimenti a parecchi siti web che usano queste soluzioni
e discute brevemente sul motivo per cui parecchie altre proposte presentano problemi.
Stato del documento
Questa sezione descrive lo stato del presente documento al momento della sua pubblicazione. Altri documenti possono sostituirlo.
Una lista delle pubblicazioni correnti del W3C e delle ultime revisioni di questo report tecnico possono essere trovate nell'
Indice dei report tecnici del W3C all'indirizzo
http://www.w3.org/TR/.
La Pubblicazione di una Nota di un Gruppo di Interesse non implica il sostegno dell'appartenenza al W3C.
Questo documento è una bozza e può essere aggiornato, sostituito e reso obsoleto da altri documenti in ogni momento.
E' dunque inappropriato citare questo documento in altre maniere se non come un "documento in lavorazione".
Gli obblighi di pubblicazione dei Partecipanti a questo gruppo sono descritte nella seguente pagina.
Obiettivo
Questo documento è una guida pratica per gli implementatori delle specifiche RDF.
Il titolo è inspirato dall'articolo di Tim Berners-Lee "Cool URIs don't change" [Cool]. In esso vengono trattati due approcci ai dati RDF contenuti sui server HTTP. Il pubblico a cui è indirizzato questo documento, sono gli sviluppatori del web e delle ontologie che devono decidere come modellizzare i propri URIs RDF per l'uso con il protocollo HTTP. Le applicazioni che utilizzano URIs non-HTTP non sono prese in considerazione. Questo documento è una guida informativa che copre gli aspetti selezionati delle specifiche tecniche di dettaglio pubblicate precedentemente.
I 303 URIs si basano sulla httpRange-14
resolution [httpRange] del
Gruppo dell'Architettura Tecnica (TAG).
Si assume che il lettore abbia familiarità con le nozioni base del modello dati RDF [RDFPrimer].
Si assume inoltre che il lettore abbia una certa familiarità con il protocollo HTTP [RFC2616]. Il seguente Articolo di Wikipedia [WP-HTTP] può servire come un buon punto di riferimento.
Il Web Semantico è visto come uno spazio mondiale decentralizzato per la condivisione di dati leggibili dalle macchine con un minimo di costi di integrazione. Le sue due sfide centrali sono la modellizzazione distribuita del mondo con un modello dati condiviso e l'infrastruttura dove i dati e gli schemi possano essere pubblicati, trovati e riutilizzati. Gli utenti possono beneficiare dal prendere le informazioni "così come sono e subito" [Give] e in un formato dati portabile [DP].
I fornitori spesso pubblicano i dati all'interno di una interfaccia utente fissa, in HTML. Una prima domanda che sorge è piuttosto su come pubblicare le informazioni sulle risorse in un modo che permetta agli utenti e alle applicazioni software di trovarle ed interpretarle.
Sul Web Semantico, tutte le informazioni devono essere espresse come affermazioni a riguardo di risorse, come ad esempio: "I membri della ditta Example.Com sono Alice e Bob" oppure "Il numero di telefono di Bob è +1
555 262" oppure "Questa pagina web è stata creata da Alice". Le risorse sono identificate mediante gli Uniform Resource Identifiers (URIs) [RFC3986]. Questo approccio di modellizzazione è il cuore del Resource Description Framework
(RDF) [RDFPrimer]. Una bella introduzione viene data nel documento introduttivo N3 [N3Primer].
Usando l'RDF le affermazioni possono essere pubblicate sul sito web della compagnia. Altri possono leggere i dati e pubblicare le proprie informazioni, collegandosi a delle risorse esistenti. Questo forma un modello distribuito del mondo. Permette inoltre agli utenti di prendere una qualsiasi aplicazione e di vedere e lavorare con gli stessi dati, per esempio per vedere i contatti pubblicati da Alice nella sua Rubrica.
Nello stesso tempo, i documenti web sono sempre stati indicati tramite URIs (o come viene detto nel gergo comune tramite "Uniform
Resource Locators", URLs). Questo è utile in quanto possiamo facilmente creare delle affermazioni RDF a riguardo di pagine web, ma anche pericoloso poichè possiamo mischiare le pagine web con le cose, o le risorse, che sono descritte sulle pagine.
Allora la domanda è:"Quale URIs dobbiamo usare nell'RDF? Ad esempio, per identificare la pagina iniziale del sito web della Example Inc. potremmo usare http://www.example.com/. Ma quale URI ideintifica la compagnia come una organizzazione piuttosto che un sito web?
Dobbiamo inoltre indicare ogni pagina con contenuti HTML o file RDF in riferimento a questo URI? In questo documento risponderemo a queste domande in accordo con le specifiche rilevanti. Spiegheremo come utilizzare gli URIs per cose che non sono pagine web, come ad esempio persone, prodotti, posti, idee e concetti come le classi ontologiche. Daremo quindi esempi dettagliati su come il Web Semantico può (e dovrebbe) essere realizzato come parte del web.
2. URIs per i Documenti Web
Cominciamo con un esempio. Assumiamo che la Example Inc., una compagnia fittizia, che produce "Extreme Guitar
Amplifiers", abbia un sito web all'indirizzo
http://www.example.com/. Una parte del sito è un elenco di pagine bianche contenente la lista dei nomi e i dettagli di contatto per gli impiegati. Alice e Bob lavorano entrambi alla Example Inc. La struttura del sito Web potrebbe dunque essere la seguente:
http://www.example.com/
Homepage della Example Inc.
http://www.example.com/people/alice
Homepage di Alice
http://www.example.com/people/bob
Homepage di Bob
Come per tutte le cose sul web tradizionale, ogni pagina menzionata sopra è un
Documento Web. Ogni documento Web ha un proprio URI. E' da sottolineare il fatto che un documento web non è un file: un singolo documento web può essere disponibile in molti formati differenti e linguaggi mentre, un singolo file, per esempio uno script PHP, può essere il responsabile della creazione di un grande numero di documenti web con URIs differenti. Un documento web è definito come qualcosa che ha un URI e che può fornire delle rappresentazioni (in formati come HTML, JPEG o RDF) della risorsa identificata in risposta alla richiesta HTTP. Nella letteratura tecnica, come in Architettura del World
Wide Web, Volume Primo [AWWW], il termine Risorsa di Informazione (Information Resource) è usato invece del termine Documento Web (Web document).
Sul Web tradizionale, gli URIs erano usati principalmente per il collegamento ai documenti web e per accedere ad essi all'interno di un browser. La nozione di identità non era così importante nel web tradizionale e un URL identificava semplicemente quello che vedevamo quando lo digitavamo all'interno di un browser.
2.1. HTTP e la Negoziazione del Contenuto
I Client web e i server usano il protocollo HTTP [RFC2616] per richiedere la visualizzazione dei doumenti web e per rimandare indietro le risposte. Il protocollo HTTP ha un meccanismo potente per offrire differenti formati e versioni dei linguaggi dello stesso documento web conosciuto come negoziazione del contenuto.
Quando un agente lato utente (come un browser) effettua una richiesta HTTP, spedisce anche alcuni headers HTTP per indicare quale formato dei dati e quale linguaggio preferisce. Il server poi seleziona l'abbinamento migliore dal suo file system o genera il contenuto desiderato su richiesta e lo rimanda indietro al client. Per esempio, un browser potrebbe mandare questa richiesta HTTP per indicare che vuole una rappresentazione HTML o XHTML di http://www.example.com/people/alice in Inglese o in Tedesco:
GET /people/alice HTTP/1.1
Host: www.example.com
Accept: text/html, application/xhtml+xml
Accept-Language: en, de
Il server dovrebbe rispondere:
HTTP/1.1 200 OK
Content-Type: text/html
Content-Language: en
Content-Location: http://www.example.com/people.en.html
e a seguire invierebbe il contenuto del documento HTML in Inglese.
A questo indirizzo possiamo vedere la Negoziazione del Contenuto [TAG-Alt] in azione.
Il server interpreta l'header Accept-Language alla richiesta e decide di ritornare la rappresentazione in lingua inglese della risorsa in questione. Da notare che l'URI di questa rappresentazione ritornato nell'header Content-Location, non è richiesto ma è una buona pratica inserirlo ed è raccomandato (consultare per approfondimenti [CHIPS], 7.2). I client vedono che l'URI è connesso con la specifica rappresentazione (in questo caso in Inglese) e il motore di ricerca può riferirsi alle differenti rappresentazioni usando i differenti URIs. Questo implica che è possibile quindi avere multiple rappresentazioni della stessa risorsa.
La Negoziazione del Contenuto è spessok implementata con un giro particolare: invece di una risposta diretta, il server effettua il reindirizzamento ad un altro URL dove si trova la rappresentazione appropriata:
HTTP/1.1 302 Found
Location: http://www.example.com/people/alice.en.html
Il reindirizzamento è indicato da uno speciale Status Code, qui indicato con 302
Found. Il client manderà ora un'altra richiesta HTTP al nuovo URL. Attuando un approccio ad URL separati per le differenti rappresentazioni, gli autori web possono collegarsi direttamente ad una specifica rappresentazione.
RDF/XML, il formato standard di RDF, ha il suo proprio tipo di contenuto,application/rdf+xml.
La Negoziazione del Contenuto perciò permette, a coloro che pubblicano sul web, di fornire rappresentazioni HTML di un documento Web ai browser tradizionali
e di fornire rappresentazioni RDF agli agenti lato utente abilitati per la gestione del Web Semantico.
Questo permette inoltre ai server di fornire altri formati seriali di RDF come Notation3 [N3] o TriX
[TriX].
3. URIs per gli oggetti del Mondo Reale
Nel Web Semantico, gli URIs identificano non solo i documenti web, ma anche oggetti del mondo reale come le persone e le macchine o anche idee astratte che rappresentano cose inesistenti come il mitico unicorno. Noi chiamiamo queste cose oggetti del mondo reale o più semplicemente cose.
Dato un URI particolare, come possiamo trovare cosa identifica? Abbiamo bisogno di qualche indicazione per rispondere a questa domanda, perchè diversamente sarebbe veramente difficile ottenere l'interoperabilità tra sistemi informativi indipendenti. Possiamo immaginare un servizio simile ai moderni motori di ricerca, in cui potremmo verificare una descrizione della risorsa identificata. Ma questo punto è una mancanza che va contro la natura decentralizzata del web.
Al contrario, dovremmo considerare il web stesso (che risulta essere un sistema di pubblicazione delle informazioni estremamente robustoe scalabile) come un servizio per la consultazione delle descrizioni delle risorse. Ogni volta che un URI viene menzionato, possiamo utilizzarlo per ritrovare una descrizione contenente delle informazioni rilevanti e collegarsi ai dati di notevole importanza. Questo è così importante che lo riteniamo come il requisito principale per gli ottimi URIs:
1. Essere sul web.
Fornendo solamente un URI, le macchine e le persone dovrebbe essere in grado di ritrovare una descrizione della risorsa identificata dal tale URI sul web. Questo meccanismo di ricerca è importante per stabilire la condivisione della comunicazione su cosa identifica l'URI. Le macchine dovrebbero prendere dati RDF mentre le persone dovrebbero poter avere una rappresentazione comprensibile, come nell'HTML. Dovrebbe inoltre essere usato il protocollo standard di trasferimento per il web, ovvero l'HTTP.
Assumiamo che la Example Inc. voglia pubblicare i contatti dei propri impiegati sul Web Semantico un modo che i loro partner d'affari possano importarli all'interno delle proprie rubriche. Per esempio, il dato pubblicato potrebbe contenere queste affermazioni su Alice, scritte qui in Sintassi N3 [N3]:
<URI-of-alice> a foaf:Person;
foaf:name "Alice";
foaf:mbox <mailto:alice@example.com>;
foaf:homepage <http://www.example.com/people/alice> .
Che URI dovremmo usare al posto di<URI-of-alice>? Sicuramente non
http://www.example.com/people/alice, perchè potrebbe confondere una persona con un documento web e questo potrebbe creare dei fraintendimenti: L'homepage di Alice si chiama anch'essa "Alice"? Può una homepage avere anch'essa un indirizzo e-mail? e ha senso per una homepage avere come riferimento se stessa come homepage? Allora abbiamo bisogno di un altro URI. (Per ulteriori approfondimenti riguardo questo elemento, vedere al seguente indirizzo Cosa identifica un URI HTTP? [HTTP-URI2] e Quattro usi di un URL: Nome, Concetto, Locazione sul Web e Istanza del Documento [Booth]).
Successivamente il nostro secondo requisito sarebbe:
2. Essere non ambiguo.
Non deve esserci confusione tra gli identificatori del documento web e gli identificatori delle altre risorse. Gli URIs devono identificare solo uno di essi nel senso che, un singolo URI, non può essere preso in considerazione sia per i documenti web che per gli oggetti del mondo reale.
Facciamo notare il fatto che i nostri requisiti sembrano entrare in conflitto tra di loro. Se non possiamo usare gli URI di documenti per identificare oggetti del mondo reale, allora come possiamo riuscire ad ottenere una rappresentazione di oggetti del mondo reale basandoci sui loro URI? La sfida è nel trovare una soluzione che ci permetta di trovare i documenti contenenti la descrizione usando le tecnologie web standard e avendo solo l'URI della risorsa.
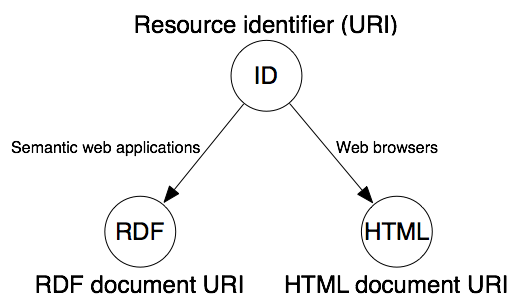
La seguente figura mostra le relazioni che ci si aspettano tra una risorsa e il documento che la rappresenta:
3.1 Distinguere tra la Rappresentazione e la Descrizione
E' importante capire che usando gli URI, è possibile identificare sia una cosa (che può esistere al di fuori del web) sia un documento web che
descrive quella cosa. Per esempio, la persona Alice, è descritta sulla sua homepage. Bob potrebbe non sembrare come una homepage, ma più verosimilmente come la persona Alice. Quindi c'è bisogno di due URI, uno per Alice e uno per la homepage o per l'RDF del documento che descrive Alice. La domanda è dove tracciare la linea tra il caso in cui entrambe le cose siano fattibili e il caso in cui solo le descrizioni sono disponibili.
In accordo con le linee guida del W3C ([AWWW], sezione 2.2.), siamo in presenza di un documento web (indicato come risorsa di informazione) se tutte le sue caratteristiche essenziali possono essere racchiuse con un messaggio. Esempi possono essere una pagina web, una immagine o un catalogo prodotti.
Nel protocollo HTTP, un codice di risposta 200 deve essere mandato quando si effettua l'accesso ad un documento web, ma c'è bisogno di un settaggio differente quando si pubblicano degli URI che devono identificare delle risorse che non sono documenti web.
Nella prossima sezione, sono descritte delle soluzioni che permettono di coniare URI per definire delle cose e che permettono inoltre ai client di ricevere una descrizione di tali cose usando delle tecnologie standard del web.
4. Due soluzioni
Ci sono due soluzioni che soddisfano i nostri requisiti per identificare gli oggetti del mondo reale: gli URIs 303 e gli URIs hash. Quale usare dipende dalla situazione. Entrambi presentano vantaggi e svantaggi.
Le soluzioni descritte successivamente si applicano alla disposizione di scenari nei quali il dato RDF e il dato HTML sono forniti separatamente come un documento RDF/XML insieme ad un documento HTML.
I metadati possono inoltre essere inseriti all'interno dell'HTML usando tecnologie come l'RDFa [RDFa Primer],
oppure microformati e altri documenti dove il meccanismo di GRDDL [GRDDL] può essere applicato. In quei casi il dato RDF è estratto dal documento HTML.
4.1. URI Hash
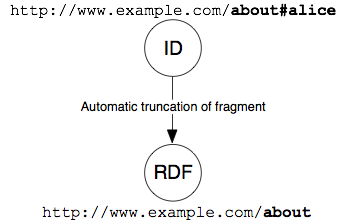
La prima soluzione è usare degli "URI hash" per le risorse che non sono documenti. Gli URI possono contenere un frammento, una parte speciale separata dal resto dell'URI da un simbolo di hash (“#”).
Quando un client vuole recuperare un URI hash, il protocollo HTTP deve togliere la parte del frammento prima di richiedere l'URI dal server.
Questo significa che un URI che include un hash non può essere recuperato direttamente e che non identifica necessariamente un documento web. Ma possiamo comunque utilizzarli per identificare altre risorse, che non rappresentano documenti, senza creare ambiguità.
Se la Example Inc. adottasse questa soluzione allora potrebbe usare questi URI per rappresentare la compagnia, Alice e Bob:
http://www.example.com/about#exampleinc
Example Inc., la compagnia
http://www.example.com/about#bob
Bob, la persona
http://www.example.com/about#alice
Alice, la persona
I client dovranno sempre tirare via la parte del frammento prima di richiedere uno qualsiasi di questi URI e risulterà quindi una richiesta di questo tipo:
http://www.example.com/about
Documento RDF che descrive Example Inc., Bob e Alice
A questo URI, la Example Inc. può fornire un documento RDF che contiene la descrizione di tutte e tre le risorse, usando l'URI hash originale per identificare le risorse.
La seguente immagine mostra l'approccio con URI hash senza la negoziazione del contenuto:
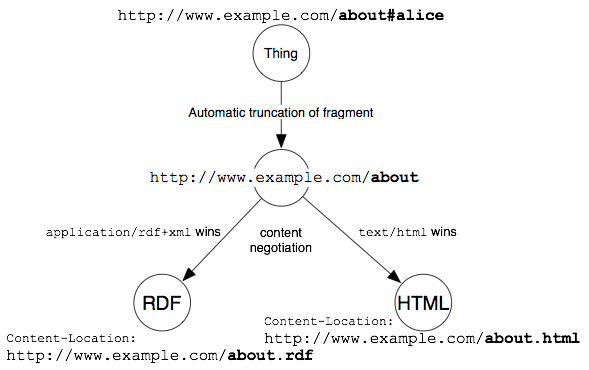
Alternativamente, la negoziazione del contenuto (vedi la Sezione 2.1.) può essere utilizzata per reindirizzare dall'URI about
ad un'altra rappresentazione HTML o RDF. La decisione su cosa ritornare è basata sulle preferenze del client e sulla configurazione del server come spiegato nella Sezione 4.7.
L'header Content-Location deve essere settato per indicare se l'hash URI si riferisce ad una parte del documento HTML o del documento RDF.
La seguente immagine mostra l'approccio con URI hash mediante la negoziazione del contenuto
4.2. URI 303 con reindirizzamento ad un generico documento
La seconda soluzione consiste nell'usare uno speciale codice di stato del protocollo HTTP, 303 See
Other, per dare l'indicazione che la risorsa richiesta non è un documento web regolare.
L'architettura web ci dice che per una risorsa che rappresenta una cosa (URI) è inappropriato ritornare un codice 200 poichè non c'è, in effetti nessuna rappresentazione valida per quel tipo di risorse. Tuttavia è utile fornire delle informazioni riguardo queste risorse. Il Gruppo per l'Architettura Tecnica del W3C's nel suo documento Risoluzione httpRange-14 [httpRange]
propone una soluzione che consiste nell'indirizzare verso un documento che ha indicazioni riguardanti la cosa di cui si è fatta richiesta.
Facendo così evitiamo l'abiguità tra l'oggetto originale del mondo reale e la risorsa che lo rappresenta.
Poichè il 303 è un codice di stato di reindirizzamento, il server può fornire la locazione di un documento che rappresenta la risorsa. Se, dall'altro lato, ad una richiesta viene risposto con uno dei codici di stato soliti del range 2XX, come il 200
OK, allora il client può sapere che l'URI identifica un documento web.
Se la Example Inc. adottasse questa soluzione, potrebbero usare anche gli URI seguenti per rappresentare la compagnia, Alice e Bob:
http://www.example.com/id/exampleinc
Example Inc., la compagnia
http://www.example.com/id/bob
Bob, la persona
http://www.example.com/id/alice
Alice, la persona
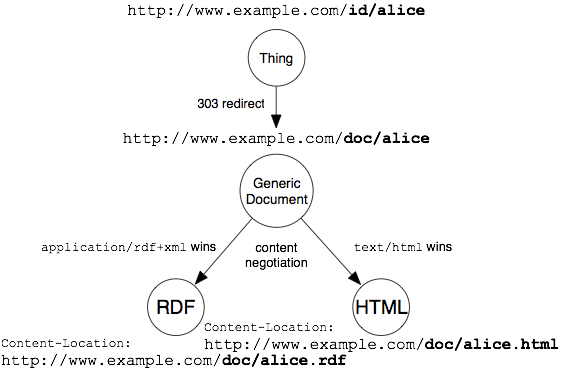
Il web server dovrebbe essere configurato per rispondere alle richieste di tutti questi URI con un codice di stato 303 e un header HTTP Location
che fornisce l'URL di un documento che rappresenta la risorsa.
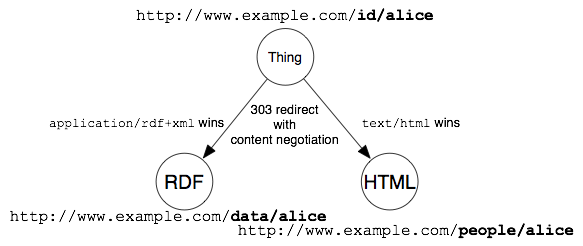
Per esempio, per reindirizzare da http://www.example.com/id/alice a http://www.example.com/doc/alice.
La negoziazione del contenuto è allora usata quando si sta cercando di recuperare la rappresentazione dall'URI di un documento usando una richiesta HTTP. Il server decide allora (vedi la Sezione 4.7) di ritornare l'HTML o RDF (o altre forme alternative) e imposta l'header Content-Location sull'URI dove può essere trovata la specifica rappresentazione.
Queste impostazioni iniziali dovrebbero essere usate quando l'RDF e HTML (e possibilmente altre rappresentazioni alternative) forniscono le stesse informazioni in differenti formati.
Quando l'informazione differisce considerevolmente nelle variazioni, dovrebbe essere usato l'approccio 303 come viene descritto successivamente.
Vedere la seguente illustrazione per la soluzione che fornisce un generico documento URI.
In queste impostazioni, il server inoltra dall'URI di identificazione all'URI del generico documento.
Questo approccio ha il vantaggio che i client possono salvare l'indirizzo e successivamente possono lavorare con il documento generico.
Un utente che abbia un client in grado di interpretare l'RDF, può salvare il link al documento, spedirlo ad un altro utente (o dispositivo) che poi può interpretarlo e prendere il formato HTML oppure la vista RDF.
Inoltre in questo modo, il server può aggiungere in futuro altre rappresentazioni nei nuovi linguaggi.
Il fatto che il client entri in possesso dell'informazione mediante l'URI di una cosa, non significa che il documento preso in considerazione sia di secondaria importanza sul web. Il contesto delle risorse che utilizzano documenti generici, è descritto in [GenRes].
4.3. URI 303 che si riferiscono a Documenti Differenti
Quando le rappresentazioni RDF e HTML delle risorse differiscono sostanzialmente, le impostazioni precedentemente discusse non dovrebbero essere utilizzate. Esse non sono infatti due versioni dello stesso documento ma sono effettivamente due documenti diversi.
Nuovamente il web server sarà configurato per rispondere a richieste con un codice di stato 303 e un header HTTP Location
che fornisce l'URL di un documento che rappresenta la risorsa.
La seguente figura mostra il reindirizzamento per la soluzione con URI 303 senza l'URI del generico documento:
Il server può impiegare la negoziazione del contenuto (vedi la Sezione 2.1.) per spedire l'URL di una descrizione HTML o di un RDF.
Le richieste HTTP per un contenuto HTML verrebbero reindirizzate all'URL HTML che abbiamo fornito nella Sezione 2. Le richieste per dati RDF verrebbero invece reindirizzate ai documenti RDF, come:
http://www.example.com/data/exampleinc
Documento RDF che descrive la compagnia Example Inc.
http://www.example.com/data/bob
Documento RDF che descrive la persona Bob
http://www.example.com/data/alice
Documento RDF che descrive la persona Alice
Ogni documento RDF conterrà affermazioni riguardanti la risorsa appropriata usando l'URI originale, ad esempio http://www.example.com/id/alice,
per identificare la risorsa descritta
4.4. Scegliere tra gli URI 303 e Hash
Qual è l'approccio migliore? Dipende. L'URI Hash ha il vantaggio di ridurre il numero di reindirizzamenti HTTP necessari, ma riduce la latenza di accesso. Una famiglia di URI può condividere la stessa parte non-hash. Le descrizioni di http://www.example.com/about#exampleinc,
http://www.example.com/about#alice e
http://www.example.com/about#bob sono ricavate con una sola richiesta alla http://www.example.com/about.
Tuttavia questo approccio ha una parte negativa. Un client interessato solo al #prodotto123 caricherà inavvertitamente anche le informazioni per tutte le altre risorse poichè sono esse contenute all'interno dello stesso file.
Dall'altro canto, gli URI 303, sono veramente flessibili poichè il bersaglio del reindirizzamento può essere configurato separatamente per ogni risorsa.
Può esserci quindi un documento descrittivo per ogni risorsa o un singolo grande documento per tutti o ogni altra combinazione possibile.
E' inoltre possibile cambiare le regole di reindirizzamento successivamente.
Quando si usano URI 303 per una ontologia, come FOAF, i ritardi della rete possono ridurre considerevolmente le performance del client. L'alto numero di reindirizzamenti può causare degli alti tempi di attesa. Un client che controlla un insieme di termini attraverso un URI 303 può causare molte richieste, anche se la prima richiesta ha già caricato tutto quello di cui c'è bisogno.
Quando si gestiscono insiemi di dati su larga scala con la soluzione 303, il client può essere tentato di scaricare tutti i dati usando molte richieste. Consigliamo di utilizzare SPARQL o altri servizi simili per rispondere a query complesse direttamente sul server, piuttosto che permettere al client di scaricare un grosso insieme di dati tramite l'utilizzo di HTTP.
Da notare inoltre che entrambi il 303 e Hash possono essere combinati tra loro, permettendo a grande insiemi di dati di venire separati in più parti e di avere un identificatore per risorse che non rappresentano documenti. Un esempio per una combinazione di 303 e Hash può essere la seguente:
http://www.example.com/bob#this
Bob, la persona con un URI combinato.
Ogni identificatore di frammento è valido, this nell'URI sopra indicato è un suggerimento che potresti copiare per le tue implementazioni.
Conclusioni.
Gli URI Hash dovrebbero essere preferiti per insiemi di risorse piccole e stabili che evolvono insieme. Il caso ideale sarebbe l'utilizzo di vocabolari a schema RDF e ontologie OWL dove i termini sono usati spesso insieme e non è previsto sia prevista una crescita dei termini nel futuro.
Gli URI Hash senza la negoziazione del contenuto possono essere implementate semplicemente caricando sul web server file RDF statici senza nessuna configurazione speciale del server. Questo rende popolari le pubblicazioni rapide RDF.
Gli URIs nella forma bob#this possono essere usati per grandi insiemi di dati che possono crescere o che sono al punto in cui è più pratico fornire tutte le risorse correlate in un singolo documento. Gli URI 303 possono essere inoltre utilizzati per questo tipo di insiemi di dati, per fornire degli URI più facilmente comprensibili ma con un impatto sul caricamento dal server e sulle performance in esecuzione.
Se sei nel dubbio, segui il tuo istinto.
4.5. Ottimi URIs
I migliori identificatori di risorse non forniscono solamente descrizioni per persone e macchine, ma sono progettati tenendo bene in mente i requisiti di semplicità, stabilità e gestibilità, come spiegato da Tim Berners-Lee nel suo articolo Cool URIs don't change
e come indicato dal team W3C nelle note Common HTTP Implementation
Problems (Sezioni 1 e 3):
Semplicità.
URI brevi e mnemonici non si corrompono facilmente quando sono spediti via mail e sono generalmente facili da ricordare, ad esempio quando si efettua il debug sul proprio Web Server Semantico.
Stabilità.
Una volta aver impostato un URI per identificare una certa risorsa, deve rimanere tale il più a lungo possibile. Pensa ai prossimi 10 anni. Magari ai prossimi 20. Mantieni indicazioni relative ad implementazioni specifiche (come .php e .asp) al di fuori dei tuoi URI.Potresti voler cambiare in futuro le tecnologie applicate.
Gestibilità.
Stabilisci i tuoi URI in una maniera che puoi facilmente gestire. Una buona pratica è quella di inserire all'interno del path l'anno corrente, in modo da poter cambiare lo schema URI ogni anno senza modificare gli URI vecchi. Tenendo tutti gli URI 303 su un sotto dominio dedicato, ad esempio http://id.example.com/alice, rende più facile la successiva migrazione del sotto-sistema di gestione degli URI.
4.6. Collegamento
Tutti gli URI collegati ad un singolo oggetto del mondo reale - identificatore di risorsa, URL di un documento in RDF, URL di un documento in HTML - devono essere inoltre collegati tra di loro per aiutare i fruitori delle informazioni a comprendere le loro relazioni.
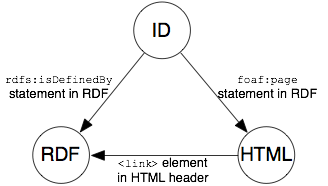
Per esempio nella soluzione ad URI 303 della Example Inc., ci sono tre URI collegati con Alice:
http://www.example.com/id/alice
Identificatore per Alice, la persona
http://www.example.com/people/alice
Homepage di Alice
http://www.example.com/data/alice
Documento RDF con la descrizione di Alice
Due di essi sono URL di documenti web. Il documento RDF collegato a http://www.example.com/data/alice potrebbe contenere in queste affermazioni
(espresse con notazione N3)
Il documento fornisce affermazioni riguardanti Alice, la persona, usando l'identificatore della risorsa.
Le prime due proprietà collegano l'identificatore della risorsa ai due URI del documento.
L'affermazione foaf:page lo collega invece al documento HTML.
Questo permette ai client in grado di interpretare l'RDF di trovare una risorsa comprensibile e, al tempo stesso, di collegare la pagina al suo argomento di riferimento e definire metadati riguardanti il suo documento HTML.
L'affermazione rdfs:isDefinedBy collega la persona al documento contenente la sua descrizione RDF e permette ai browser di distinguere la risorsa principale dalle altre risorse ausiliarie che sono semplicemente nominate nel documento.
Usiamo rdfs:isDefinedBy invece della sua sottoproprietà rdfs:seeAlso perchè il contenuto /data/alice è perentorio.
Le affermazioni rimanenti sono dati di informazioni per pagine bianche.
Il documento HTML all'indirizzo http://www.example.com/people/alice dovrebbe contenere nel suo header l'elemento <link> che punta al corrispondente elemento RDF:
Questo permette ai client web in grado di interpretare RDF di trovare informazioni in questo formato.
L'approccio corretto è indicato nelle
raccomandazioni sulle specifiche RDF/XML ([RDFXML], sezione 9).
Se il dato RDF è riguardante la pagina web, piuttosto che un'espressione dell'informazione in essa, raccomandiamo il tag rel="meta" invece del tag rel="alternate".
Il client può inoltre dedurre link ad informazioni simili direttamente dall'header HTTP. Una cosa può essere descritta da un documento web che può essere trovato alla fine di un re-indirizzamento 303 e una risorsa Content-Location è una versione specifica del documento generico e così via.
Le Ontologie per queste relazioni non sono discusse in questo documento.
La seguente illustrazione mostra come i documenti HTML e RDF dovrebbero mettere in relazione i tre URI gli uni con gli altri.
4.7. Implementare il Contenuto della Negoziazione
Il Gruppo di lavoro per la diffusione e le Best Practices per il Semantic Web ha pubblicato un documento che descrive come implementare le soluzioni qui presentate su un web server Apache. Le Indicazioni migliori per la pubblicazioni dei Vocabolari RDF [Ricette] discutono maggiormente la pubblicazione dei Vocabolari RDF, ma le idee possono essere inoltre applicate ad altri ripi di piccoli insiemi di dati RDF che sono pubblicati partendo da file statici.
Tuttavia, specialmente quando si arriva alla negoziazione del contenuto, le Indicazioni non coprono alcuni importanti dettagli.
La negoziazione del contenuto è un pò più difficile da mettere in pratica a causa dei client mixed-mode che possono gestire sia HTML che RDF, come il FireFox con il Tabulator extension.
Questi browser preannunciano la loro abilità di gestire RDF e HTML attraverso gli header Accept che usano il valore q (quality):
Accept: application/rdf+xml;q=0.7, text/html
Questo browser accetta RDF con un valore q pari a 0.7 e HTML con un valore q pari al valore di default 1.0.
Questo significa che il browser ha una leggera preferenza per l'HTML rispetto all'RDF.
Ora, una preferenza del client verso HTML non implica necessariamente il fatto che ogni server debba spedire in formato HTML.
Il server deve controllare le preferenze del client e successivamente deve prendere una decisione sulla qualità delle differenti varianti che può offrire.
Per esempio:
Se la variante HTML è una semplice traduzione di bassa qualità dell'RDF, come una tabella di valori di proprietà o una lista di triplette, allora il server dovrebbe spedire l'RDF, a meno che il client non abbia una forte preferenza per il formato HTML.
Se le varianti HTML e RDF contengono le stesse informazioni ed entrambi sono di alta qualità, allora il server dovrebbe trattare entrambe le varianti con la stessa preferenza e lasciare la scelta della preferenza al client.
Se la variante RDF contiene solo una parte dell'informazione offerta dal formato HTML, o è semplicemente tagliata via dall'HTML, allora il server dovrebbe spedire probabilmente il formato HTML a meno che il client non abbia una forte preferenza per il formato RDF.
Ci sono algoritmi per scegliere oppportunamente il formato comparando le preferenze del client con la qualità delle varianti disponibili sul server. Per esempio, il server Apache può essere configurato con il valore qs a lato server che specifica la loro qualità relativa.
Un valore qs pari a 1.0 per application/rdf+xml e pari a 0.5 per
text/html, significherebbe che la variante HTML ha approssimativamente la metà della qualità dell'RDF e potrebbe essere appropriato nel primo caso della lista precedente. Se l'HTML è una notizia e l'RDF contiene solo informazioni minime riguardanti il titolo, la data e l'autore, allora potrebbe essere appropriato dare un valore pari a 1.0 per il formato HTML e pari a 0.1 per il formato RDF.
Per determinare la variante migliore per un client particolare, il server Apache moltiplica il valore q del client per il formato HTML con il valore qs configurato per HTML. Lo stesso procedimento viene adottato per il formato RDF. Vince la variante con il numero più alto.
La documentazione di Apache, ha una sezione
con una descrizione dettagliata dell'algoritmo per la negoziazione del contenuto [ApCN]. L'intestazione HTTP Accept viene descritta in dettaglio nella sezione 14.1 delle specifiche HTTP [HTTP-SPEC].
La negoziazione del contenuto con tutti i suoi dettagli è moderatamente complesso, ma è un modo potente di scegliere la variante migliore per i client misti che possono gestire sia HTML che RDF.
5. Esempi dal web
Non tutti i progetti che lavorano con le tecnologie del Web Semantico rendono disponibili le loro informazioni sul web.
Ma un numero crescente di progetti segue le indicazioni descritte qui.
Con l'inserimento del primo URI in un browser web normale, si viene reindirizzati ad una pagina HTML su Wendy Hall. Questa pagina presenta una vista web di tutti i dati disponili su di lei. La pagina contiene inoltre il collegamento al suo URI e al suo documento RDF.
D2R Server è un'applicazione open-source che può essere utilizzata per pubblicare informazioni provenienti da database relazionali sul Web Semantico, in accordo con queste linee guida. Utilizza la soluzione ad URI 303 e la negoziazione del contenuto. Per esempio,il Server D2R utilizzato per pubblicare il Database Bibliografico DBLP pubblica parecchie migliaia di record bibliografici e di informazioni riguardanti i loro autori. Gli URI 303 utilizzati, di nuovo, si connettono mediante reindirizzamento:
Questo spiega come un indirizzo finale SPARQL può essere usato come un metodo conveniente per fornire le descrizioni di una risorsa.
Semantic MediaWiki è un motore "wiki" semantico open-source.
Gli autori possono usare una sintassi "wiki" per inserire attributi semantici e relazioni all'interno di articoli su Wikipedia.
Per ogni articolo, il software genera un URI 303 che identifica l'argomento di base e fornisce una descrizione RDF generata dagli attributi e dalle relazioni. Semantic MediaWiki apre la porta al progetto OntoWorld wiki. Ha un articolo riguardo la città di Karlsruhe:
L'URI della descrizione RDF è meno che ideale in quanto espone l'implementazione (php) e riferisce in maniera ridondante con l'RDF sia nel path che nella query. Un URI molto più utile potrebbe essere ad esempio il http://ontoworld.org/data/Karlsruhe, poichè permette l'uso della negoziazione del contenuto per fornire i dati in formato RDF, RIF (Rule Interchange Format) o qualsiasi altra cosa potremmo pensare successivamente.
6. Altre proposte per la Denominazione delle Risorse
Sono stati proposti tanti altri approcci nel corso degli anni. Mentre la maggior parte di loro sono appropriati in circostanze speciali, pensiamo che essi non incontrano i criteri della Sezione 3,
che sono di essere sul web e non essere ambigui. Tuttavia, non sono adeguati come soluzioni generali per la costruzione di un Web Semantico standard, non frammentato e decentralizzato. Discuteremo due di questi approcci con un ulteriore approfondimento.
6.1. Nuovi Schemi URI
Gli URI HTTP identificano già risorse web e documenti, ma non identificano altri tipi di risorse.
Non dovremmo allora creare un nuovo schema URI per identificare altre risorse? In questo modo potremmo facilmente distinguerle dai documenti web semplicemente guardando il primo carattere dell'URI. Ad esempio, lo schema info può essere usato per identificare libri basandosi sul numero LCCN: info:lccn/2002022641.
Magnet è uno schema URI aperto che permette una integrazione scorrevole tra siti web e strumenti utili che girano in locale sulla macchina, come ad esempio gli strumenti di gestione dei file. E' basato su valori di hash e un URI ha un aspetto simile a questo: magnet:?xt=urn:sha1:YNCKHTQCWBTRNJIV4WNAE52SJUQCZO5C.
Lo Schema URI info: è proposto per identificare informazioni valide che hanno identificatori nello spazio dei nomi pubblico esistente. Esempi sono gli URI per i numeri LCCN (info:lccn/2002022641) e il sistema decimale Dewey (info:ddc/22/eng//004.678).
L'idea di usare dei Tag URIs serve per generare degli URI privi di collisione usando un dominio e una data quando l'URI viene allocato. Anche se cambia la proprietà del dominio successivamente, l'URI rimane non ambiguo. Ad esempio:
tag:hawke.org,2001-06-05:Taiko.
XRI
definisce uno schema e un protocollo di risoluzione per identificatori astratti. L'idea è quella di usare degli URI che contengono caratteri jolly per adattarsi ai cambiamenti di organizzazione, server ecc. Esempi sono @Jones.and.Company/(+phone.number)
o xri://northgate.library.example.com/(urn:isbn:0-395-36341-1).
Per essere sinceramente utile, un nuovo schema deve essere accompagnato da un protocollo che definisce come accedere a più informazioni riguardanti le risorse identificate. Per esempio lo schema URI ftp:// identifica alcune risorse (file e server FTP) e viene accompagnato inoltre da un protocollo che spiega come accedervi (il protocollo FTP).
Alcuni dei nuovi schemi URI non forniscono nessuno di questi protocolli. Altri forniscono un servizio web che permette il reperimento delle descrizioni usando il protocollo HTTP. L'identificatore è passato al servizio che ricerca le informazioni in un databse centrale o in una maniera prestabilita.
Il problema è che una falla in questo servizio rende il sistema inutilizzabile.
Un altro ostacolo può essere la dipendenza da un corpo standardizzato. Per registrare nuove parti nello spazio info:, deve essere contattato un corpo standardizzato. Questo, o il fatto di dover pagare una licenza prima di creare un nuovo URI, rallenta molto la sua adozione.
In alcuni casi l'uso di un corpo standardizzato è desiderabile per assicurare che tutti gli URI siano unici (as esempio con i codici ISBNs).
Ma questo può essere ottenuto usando URI HTTP all'interno dello spazio dei nomi HTTP di proprietà e gestito dall'organismo di standardizzazione.
L'indipendenza dal corpo di standardizzazione, la recuperabilità, i brevetti e le questioni legali, possono influenzare l'adozione dei nuovi schemi URI. Quando si usano delle tecnologie brevettate, gli implementatori devono verificare che siano disponibili delle licenze gratuite.
Il "Riferimento tramite Descrizione" risolve radicalmente il problema degli URI liberandosene totalmente.
Invece di denominare una risorsa con un URI, vengo usati dei nodi anonimi e sono descritti tramite delle informazioni che ci permettono di trovare quello giusto. Una persona per esempio, può essere descritta mediante un nome, la data di nascita e il suo codice fiscale.
Queste informazioni dovrebbero essere sufficienti per identificare univocamente una persona.
Una pratica popolare è quella di usare l'indirizzo personale email come un pezzo di informazione identificativo e univoco.
La proprietà foaf:mbox è usata nel profilo Friend of a Friend (FOAF) a questo scopo.
Nel linguaggio OWL, questo tipo di proprietà è conosciuta come Proprietà Funzionale Inversa (Inverse Functional Property) (IFP).
Quando un agente incontra due risorse con lo stesso indirizzo email, può dedurre che entrambe si riferiscono alla stessa persona e può trattare come un'unica informazione.
Ma come implementare l'essere sul web con questo approccio? Come abilitare gli agenti a scaricare più dati riguardanti le risorse che nominiamo?
C'è una indicazione ottima per raggiungere questo obiettivo: fornire non solo l'IFP della risorsa (ad esempio l'indirizzo email della persona), ma anche una proprietà rdfs:seeAlso che punta ad un indirizzo web di un documento RDF con altre informazioni a riguardo.
Possiamo vedere che gli URI HTTP sono ancora usati per identificare l'indirizzo dove possono essere scaricate maggiori informazioni.
Tuttavia abbiamo bisogno di parecchie informazioni per riferirci ad una risorsa, oltre al valore IFP e all'indirizzo del documento RDF. Il semplice atto di effettuare il collegamento tramite un URI è diventato un processo che include il movimento di parecchie parti e questo incrementa il rischio di avere dei link corrotti e rende l'implementazione più ingombrante.
In riferimento alla pratica FOAF di evitare l'utilizzo degli URI per le persone, siamo d'accordo con il Consiglio di Tim Berners-Lee: “Vai avanti e datti un URI. Te lo meriti!”
7. Conclusione
I nomi delle risorse sul Web Semantico devono soddisfare due requisiti. Prima di tutto una descrizione della risorsa identificata deve essere recuperabile con le tecnologie web standard. Secondo, uno schema di denominazione non dovrebbe confondere le cose con i documenti che le rappresentano.
Abbiamo descritto due approcci che soddisfano questi requisiti, entrambi basati sullo schema HTTP ad URI e sul protocollo. Uno consiste nell'usare il codice di stato HTTP 303 per effettuare il reindirizzamento dell'identificatore della risorsa al documento descrittivo.
L'altro consiste nell'usare gli "URI Hash" per identificare le risorse, sfruttando il fatto che gli URI Hash sono raggiunti eliminando la parte dopo l'hash e
recuperando l'altra parte.
Il requisito di distinguere tra le risorse e le loro descrizioni, aumenta il bisogno di coordinazione tra più URI. Alcune tecniche utili sono:
l'incapsulmaneto di dati RDF all'interno di documenti HTML, l'utilizzo di affermazioni RDF per descrive le relazioni tra i diversi URI e l'uso della negoziazione del contenuto per reindirizzare verso una appropriata descrizione della risorsa.
8. Ringraziamenti
Calorosi ringraziamenti vanno a Tim Berners-Lee che ha investito molto tempo e ci ha aiutato a capire la soluzione TAG rispondendo a tutte le richieste della chat e contribuendo con le molte email tramite chiarificazioni e revisioni dettagliate di questo doccumento.
Speicali ringraziamenti vanno a Stuart Williams, Norman Walsh e a tutti gli altri membri del TAG che hanno revisionato questo documento e fornito feedback essenziali sul documento di Giugno 2007 e
Settembre 2007 riguardo a tante formulazioni che erano (accidentalmente) contrarie al punto di vista del TAG. Un altro speciale ringraziamento va ai membri del Gruppo di rilascio del Web Semantico ed in particolare a Michael Hausenblas, Vit Novacek e Ed Summers per le loro revisioni e i commenti pubblicati nel documento di Ottobre 2007.
Vogliamo inoltre ringraziare tutti gli altri che hanno revisionato le bozze di questo documento, in particolare Chris Bizer, Gunnar AAstrand Grimnes, Harry Halpin, Xiaoshu Wang, Henry S. Thompson, Jonathan Rees e Christoph Päper. A Susie Stephens che ha revisionato il documento, gestito il gruppo SWEO e che ci ha aiutato a rimanere in sella.Ad Ivan Herman che ha fatto molto per verificare che siano stati soddisfatti i requisiti del W3C e che siano stati inclusi nelle note.
Questo lavoro è stato inoltre supportato dal Ministero dell'Educazione, della Scienza, della Ricerca e della TEcnologia, della Germania Federale (BMBF), (Concessione 01 IW C01, Progetto EPOS: "Evolving Personal to Organizational Memories"; e 01 AK 702B, Progetto InterVal:"Internet
and Value Chains") e dal fondo dell'Unione Europea IST (Concessione FP6-027705, Progetto: Nepomuk).
Problemi comuni nelle implementazioni HTTP, Olivier Théreaux, Editore. World Wide Web
Consortium, 28 Gennaio 2003. Questa edizione è la http://www.w3.org/TR/2003/NOTE-chips-20030128/.
L'ultima edizione è disponibile all'indirizzo http://www.w3.org/TR/chips/.
Cosa Identificano gli URI HTTP, Tim Berners-Lee. 9 Giugno 2005.
Questo documento è disponibile all'indirizzo http://www.w3.org/DesignIssues/HTTP-URI2.html.
Nozioni introduttive: Entrare nell'RDF & nel Web Semantico Semantic usando la notazione N3. Tim Berners-Lee,
2005. http://www.w3.org/2000/10/swap/Primer
RDF Primer, Frank Manola, Eric Miller, Editori. World Wide Web
Consortium, 10 Febbraio 2004. Questa edizione è la http://www.w3.org/TR/2004/REC-rdf-primer-20040210/. L'ultima edizione è disponibile all'indirizzo http://www.w3.org/TR/rdf-primer/.
Specifiche della Sintassi RDF/XML (Revisionato), Dave Beckett, Editore. World Wide Web Consortium, 10 Febbraio 2004. Questa edizione è la http://www.w3.org/TR/2004/REC-rdf-syntax-grammar-20040210/. L'ultima edizione è disponibile all'indirizzo http://www.w3.org/TR/rdf-syntax-grammar/.
Le migliori indicazioni pratiche per la pubblicazione di vocabolari RDF, Alistair Miles, Thomas Baker, Ralph Swick, Editori. World Wide Web Consortium, 23 Gennaio 2008. Questa edizione è la http://www.w3.org/TR/2008/WD-swbp-vocab-pub-20080123/.
E' in lavorazione. L'ultima edizione è disponibile all'indirizzo http://www.w3.org/TR/swbp-vocab-pub/.
RFC 2616: Hypertext Transfer Protocol - HTTP/1.1, J. Gettys, J. Mogul, H. Frystyk, L.
Masinter, P. Leach, T. Berners-Lee. IETF, 1999. Questo documento è disponibile all'indirizzo http://www.ietf.org/rfc/rfc2616.txt.
Semantic Wikipedia, Max Völkel, Markus Krötzsch, Denny Vrandecic, Heiko Haller, Rudi Studer. University of Karlsruhe, 2006. Questo documento è disponibile all'indirizzo http://www.aifb.uni-karlsruhe.de/WBS/hha/papers/SemanticWikipedia.pdf.
URNs,
Spazio dei Nomi e Registri, Henry S. Thompson, David Orchard. World Wide Web Consortium, 17 Agosto 2006. Questa edizione è la
http://www.w3.org/2001/tag/doc/URNsAndRegistries-50-2006-08-17.html. E' in lavorazione. L'ultima edizione è disponibile all'indirizzo
http://www.w3.org/2001/tag/doc/URNsAndRegistries-50.html.
Triplette RDF in XML, Jeremy J. Carroll, Patrick Stickler, 2004. Questo documento è disponibile all'indirizzo
http://www.mulberrytech.com/Extreme/Proceedings/html/2004/Stickler01/EML2004Stickler01.html.
Hypertext Transfer
Protocol, Wikipedia contributors. Wikipedia, 8 Ottobre 2007. L'ultima versione di questo documento è disponibile al seguente indirizzo
http://en.wikipedia.org/wiki/HTTP.
10. Registro dei cambiamenti
29 Novembre 2006
1.0 Versione Iniziale.
9 Agosto 2007
1.1 Versione Revisionata. Modifiche basate sul TAG review.
28 Novembre 2007
Leo Sauermann ha incluso alcuni feedback dalle revisioni dei contributi del TAG, SWD e di Tim Berners-Lee.
8 Dicembre 2007
Danny Ayers ha corretto le bozze, attuando alcune piccole modifiche grammaticali, di idioma ed editoriali
(Ho provato a non fare nessun cambiamento che modificava sostanzialmente il contenuto sebbene alcuni ci siano andati molto vicini...).
E' stato inoltre validato l'XHMTL con il nxml-mode emacs
12 Dicembre 2007
Leo Sauermann ha incluso il link al GRDDL come suggerito da Danny Ayers e sono state aggiunte delle piccole note sugli sviluppi futuri.
Il Documento è stato rimodellato con lo stato "In lavorazione" - tutti i feedback del SWD, TAG e di Tim Berners Lee sono stati indicati in questo documento o sono state evidenziate come cose da fare usando il simbolo @@ e la classe css "todo".