SOMMARIO:
5
MULTIPLEXER DINAMICO SCALATO (M8V3)
6
MULTIPLEXER DINAMICO SCALATO SATURATO (M8V4)
8
CONFRONTI TRA LE DIVERSE SOLUZIONI
1
INTRODUZIONE
Analizziamo
le possibili realizzazioni di un sommatore di tipo Manchester, cercando di
massimizzare le prestazioni e di minimizzare l’occupazione d’area.
Diamo un
breve accenno alla struttura del sommatore, in quanto già discusso a lezione.
Abbiamo in ingresso due vettori a n bit (A,B) e un bit di riporto (Cin), mentre
in uscita n bit di somma (S) e un bit di riporto (flag). Il sommatore al suo interno prevede una
sequenza di n moduli che chiameremo bit slice. Si noti la struttura
modulare che può essere sfruttata, componendo semplicemente le bit slice tra
loro. Se per esempio volessimo realizzare un Manchester a 32 bit, basterà
connettere tra loro 32 slice.
Si noti la struttura
modulare che può essere sfruttata, componendo semplicemente le bit slice tra
loro. Se per esempio volessimo realizzare un Manchester a 32 bit, basterà
connettere tra loro 32 slice.
La bit slice è costituita da 4 componenti
fondamentali: un and per il calcolo del terminine di generazione, uno xor per
il termine di propagazione, un altro per la somma ed il multiplexer.

|
Termine di generazione |
|
|
Termine di propagazione |
|
|
Riporto |
|
|
Somma |
|
Possiamo caratterizzare diversi tipi di sommatori a
seconda di come pensiamo il multiplexer:
a) In logica statica
b) In logica dinamica
2 CELLE STANDARD
|
A |
B |
Y |
|
0 |
0 |
0 |
|
1 |
0 |
1 |
|
0 |
1 |
1 |
|
1 |
1 |
0 |
Una volta suddiviso il problema (divide et impera)
e riconosciuto le risorse elementari di cui necessitiamo (NOT,AND,NAND,XOR),
seguiamo un approccio bottom-up. Implementiamo i diversi circuiti in modalità
mista standard cells e asic. Per ottenere ottime prestazioni e
un’alta densità di transistori costruiamo delle celle in logica fcmos,
partendo dalla più complessa, cioè l’xor.
L’uscita si deve scaricare quando i due ingressi sono entrambi alti o
bassi. Quindi ho il parallelo di due rami dove su uno ci saranno 2 nmos
pilotati da A e B, dall’altro sempre due nmos
pilotati dal loro complemento. La rete di pull-up è presto fatta ,
essendo complementare alla rete di pull-down. La compattiamo il più possibile,
cercando di ottenere tempi di propagazione bassi. Simuliamo l’xor connettendo
come carico in uscita l’inverter, cioè circa 2fF. Otteniamo dei tempi di
propagazione (50% dell’escursione massima) espressi nella netlist e la
correttezza funzionale, come mostrato in figura.
|
Area=1338mm2
|
|
|
gate xor2(a,b,y) t: delta=148.e-12 i: a=L b=H o: y=H i: a=H b=L o: y=H t: delta=249.e-12 i: a=H b=H o: y=L i: a=L b=L o: y=L t: delta=0 i: o: y=X load:
a=1.0 b=1.0 |


Abbiamo cercato di lasciare uno spazio per i tre
segnali P, G, C che si propagano orizzontalmente.
Per le altre porte abbiamo mantenuto la stessa
altezza e abbiamo cercato di compattare il più possibile la larghezza.
|
Area=360mm2
|
Area=828mm2
|
Area=516mm2
|
|
gate
inverter(a,y) t: delta=36.e-12 i: a=L o: y=H t: delta=70.e-12 i: a=H o: y=L t: delta=0 i: a=X o: y=X load:
a=1.0 |
gate
and2(a1,a2,y) t: delta=137.e-12 i: a1=L o: y=L i: a2=L o: y=L t: delta=251.e-12 i: a1=H a2=H o: y=H t: delta=0 i: o: y=X load:
a1=1.0 a2=1.0 |
gate
nand2(a1,a2,y) t: delta=54.e-12 i: a1=L o: y=H i: a2=L o: y=H t: delta=187.e-12 i: a1=H a2=H o: y=L t: delta=0 i: o: y=X load:
a1=1.0 a2=1.0 |



3 MULTIPLEXER STATICO (M8V1)
Realizziamo
il multiplexer in senso “classico” con i 3 nand e l’invertitore.

Implementiamo il tutto prima in vhdl:
|
entity man8 is
port(a0,a1,a2,a3,a4,a5,a6,a7,
b0,b1,b2,b3,b4,b5,b6,b7,
cin :in bit;
s0,s1,s2,s3,s4,s5,s6,s7,
flag: out bit); end man8; architecture man8_body of man8 is
component slice
port (in0,in1,cin : in
bit;
cout,sout : out bit); end
component; signal c0,c1,c2,c3,c4,c5,c6 :bit; begin
opa1: slice port map (a0,b0,cin,c0,s0);
opa2: slice port map (a1,b1,c0,c1,s1);
opa3: slice port map (a2,b2,c1,c2,s2);
opa4: slice port map (a3,b3,c2,c3,s3);
opa5: slice port map (a4,b4,c3,c4,s4);
opa6: slice port map (a5,b5,c4,c5,s5);
opa7: slice port map (a6,b6,c5,c6,s6);
opa8: slice port map (a7,b7,c6,flag,s7); end man8_body; entity slice is
port (in0,in1,cin : in
bit;
cout,sout : out bit); end slice; |
architecture slice_body of slice is
component xor2
port (a,b: in bit;
y: out bit); end
component; component mux2 port
(in0,in1,sel : in bit;
y : out
bit); end
component;
component halfadder port
(in0,in1 : in bit;
c ,s: out bit);
end component; signal p,g:bit; begin
invo1: halfadder port map (in0,in1,g,p);
invo2: mux2 port map (g,cin,p,cout);
invo3: xor2 port map (p,cin,sout); end slice_body; entity mux2 is
port (in0,in1,sel : in
bit;
y:out bit); end mux2; architecture mux2_body of mux2 is
component inverter
port (a: in bit;
y: out bit); end
component; |
component nand2
port(a1, a2 : in BIT;
y : out BIT); end
component; signal n0,n1,selneg:bit; begin
invo1: inverter port map (sel,selneg);
nando2: nand2 port map
(in0,selneg,n0);
nando3: nand2 port map
(in1,sel,n1);
nando4: nand2 port map
(n1,n0,y); end mux2_body; entity halfadder is port
(in0,in1 : in bit;
c ,s: out bit); end halfadder; architecture halfadder_body of halfadder is
component xor2
port (a,b: in bit;
y: out bit); end
component;
component and2
port(a1, a2 : in BIT;
y : out BIT); end
component; begin
invo1: xor2 port map (in1,in0,s);
nando2: and2 port map
(in1,in0,c); end halfadder_body; |
Simuliamo con Als e verifichiamo la
correttezza funzionale del circuito. Il tempo di propagazione stimato è di
2.8ns del termine somma S7. Costruiamo il layout utilizzando il silycon
compilers di Electric e otteniamo la facet a fianco. Notiamo come questa presenti un
bassa densità di transistor(82000mm2), non conforme
agli obiettivi prefissati. Soprattutto delude il routing, in quanto la
realizzazione delle celle è stata fatta prevedendo un tracciamento orizzontale
ed interno alle celle.

Eseguiamo un tracciamento custom e otteniamo
la seguente bit slace di area 5000mm2:

Si noti l’estrema modularità e compattezza della
realizzazione. Inoltre è anche abbastanza leggibile, infatti in ordine abbiamo:
and per il calcolo di G, xor per P, inverter e 3 nand per il multiplexer e di
nuovo uno xor per la somma.
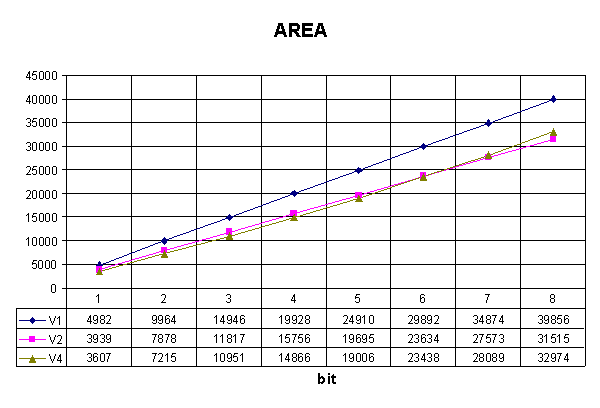
Componendola possiamo realizzare un Manchester a 8 bit di appena 39856mm2, circa il 51% in meno di prima.
L’occupazione di area segue la seguente legge: ![]() . Analizziamo il caso peggiore di ritardo, cioè quando il
riporto in ingresso si propaga sino all’uscita, secondo la seguente
transizione:
. Analizziamo il caso peggiore di ritardo, cioè quando il
riporto in ingresso si propaga sino all’uscita, secondo la seguente
transizione:
|
A |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
|
B |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
|
Cin |
1 |
|
||||||
|
S |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
Flag |
1 |
|
||||||
|
|
|


Notiamo come
il tempo ti propagazione nel caso peggiore sia circa 3.5ns. Osserviamo due cose: la prima è la crescita
lineare del tempo di propagazione. La seconda come il ritardo del flag è
diverso dagli altri riporti, in quanto la capacità di carico simulata è quella
di un inverter, mentre gli altri hanno quella di un nand. Possiamo perciò
stimare il seguente andamento:

E’ stata effettuata un ulteriore
verifica sulla correttezza funzionale del dispositivo. Si veda per questo il
capitolo 9.
4 MULTIPLEXER DINAMICO (M8V2)
Abbiamo visto come sono stati definiti i termini G e
P nell’introduzione. Si vede immediatamente come essi non possono mai essere
simultaneamente alti. Così è possibile costruire un multiplexer più semplice in
logica dinamica di tipo PE mista a quella Pass-transistor, senza preoccuparsi
dei problemi che generalmente comporta il collegare in cascata più porte della
stessa natura, in quanto il valore viene precaricato al valore alto dal pmos. Il Cin e il Cout sono
negati, quindi la struttura sarà ancora modulare, ma dovremo inserire
all’inizio e alla fine della catena un inverter, per riportare il tutto in
logica positiva. Consideriamo Cin sincrono come eventuale uscita di un altro
sommatore della stessa specie, mentre i segnali P e G possono variare in modo
asincrono limitatamente alla fase di precarica. Possono tuttavia verificarsi
corse critiche nel momento in cui il P tarda a commutare allo stato basso, in
quanto rischio di propagare in fase di valutazione un Cin che non volevo.
Quindi il P e G devono aver terminato il proprio transitorio prima della
valutazione. Così facendo otteniamo la seguente bit slice di area 3607mm2:
Il Cin e il Cout sono
negati, quindi la struttura sarà ancora modulare, ma dovremo inserire
all’inizio e alla fine della catena un inverter, per riportare il tutto in
logica positiva. Consideriamo Cin sincrono come eventuale uscita di un altro
sommatore della stessa specie, mentre i segnali P e G possono variare in modo
asincrono limitatamente alla fase di precarica. Possono tuttavia verificarsi
corse critiche nel momento in cui il P tarda a commutare allo stato basso, in
quanto rischio di propagare in fase di valutazione un Cin che non volevo.
Quindi il P e G devono aver terminato il proprio transitorio prima della
valutazione. Così facendo otteniamo la seguente bit slice di area 3607mm2:

Chiaramente visibile la zona
dove e’ stato inserito il multiplexer. Si osservi l’ultimo xor. Abbiamo invertito i termini che si
riferivano al Cin per non inserire un ulteriore inverter, ottenendo così ancora
il valore della somma corretto. Il sommatore
risulta di area 31515mm2:
|
|
|


Analizziamo ora i tempi di propagazione. Si noti il particolare andamento parabolico. Non prendiamo in considerazione il termine C7, perché pilota una capacità minore rispetto agli altri.

Questo andamento risulta dal fatto che la linea, che scarichiamo nel caso peggiore, è di tipo RC distribuita. Il tempo di propagazione finale è dato dal segnale S7, dovuto al fatto che l’xor è più lento nel calcolo della somma rispetto al multiplexer, pari a 6nsec. E’ stata effettuata un ulteriore verifica sulla correttezza funzionale del dispositivo. Si veda per questo il capitolo 9.
5 MULTIPLEXER DINAMICO SCALATO (M8V3)
Per ovviare a questo andamento parabolico ricorriamo
alla scalatura dei transistori che sono comandati dal termine P e G.  Ovviamente la scalatura
richiede un dimensionamento dedicato ad ogni singolo mos (Pi),
pertanto viene a meno la modularità del
progetto. Ciò che voglio ottenere è una scarica uguale per tutti.
Intuitivamente si spiega l’andamento parabolico del tempo di ritardo anche dal
fatto che il generico Ci , prima di potersi scaricare, deve
attendere la scarica di tutti quelli a monte. Utilizzando una similitudine
idraulica, è come se avessimo tanti rubinetti con la stessa portata e un canale dimensionato per la portata di un
solo . Dobbiamo fare in modo che:
Ovviamente la scalatura
richiede un dimensionamento dedicato ad ogni singolo mos (Pi),
pertanto viene a meno la modularità del
progetto. Ciò che voglio ottenere è una scarica uguale per tutti.
Intuitivamente si spiega l’andamento parabolico del tempo di ritardo anche dal
fatto che il generico Ci , prima di potersi scaricare, deve
attendere la scarica di tutti quelli a monte. Utilizzando una similitudine
idraulica, è come se avessimo tanti rubinetti con la stessa portata e un canale dimensionato per la portata di un
solo . Dobbiamo fare in modo che:
![]()
in
prima approssimazione possiamo scrivere per la generica corrente Ici
:
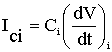
cioè
ottengo:

Fissiamo la corrente dell’ultima stadio 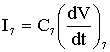 .
.
Siccome voglio ottenere la medesima scarica per
tutte le correnti ho:
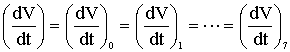
Quindi posso esprimere la generica corrente Ii
come:

Sapendo che la corrente del mos è proporzionale al
fattore di forma, ottengo:
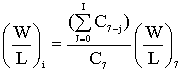
Con
Electric estraggo le capacità parassite Ci e usando questa formula
ottengo la seguente tabella:
|
MOS (P) |
Capacità parassita |
W/L |
L |
W |
|
7 |
1.31 |
1 |
3 |
3 |
|
6 |
4.06 |
4.1 |
2 |
8 |
|
5 |
4.15 |
7.3 |
2 |
15 |
|
4 |
4.24 |
10.5 |
2 |
21 |
|
3 |
4.35 |
13.8 |
2 |
28 |
|
2 |
4.44 |
17.2 |
2 |
34 |
|
1 |
4.63 |
20.7 |
2 |
41 |
|
0 |
4.79 |
24.4 |
2 |
49 |
|
Inverter |
3.95 |
27.4 |
2 |
55 |
In modo analogo devono essere dimensionati gli nmos
G e Clock. Purtroppo notiamo come l’andamento non è di tipo lineare come ci si
aspettava. Evidentemente Electric non
riesce ad estrarre tutte le capacità parassite del mos.
Risulta molto difficile stimare queste capacità
parassite, in quanto dipendono dalla frequenza, dalla tensione applicata (Cdb
e Csb) e dallo stato di conduzione del canale. Ma vogliamo
tentare lo stesso attraverso un modello empirico. Analizziamo il seguente
circuito a fianco. Ci troviamo nel caso di
propagazione descritto in precedenza attraverso il termine P. Ricordiamo come
il tempo di scarica di un condensatore tramite un nmos, in questo caso quello
comandato da Cin, sia uguale a:
Ci troviamo nel caso di
propagazione descritto in precedenza attraverso il termine P. Ricordiamo come
il tempo di scarica di un condensatore tramite un nmos, in questo caso quello
comandato da Cin, sia uguale a:

cioè:
![]()
Eliminiamo tutte le capacità parassite estratte da
Electric, in quanto voglio trovare una espressione per quelle che non
considera. Queste saranno considerate
in seguito. Trovo Tphl . Inserisco una capacità C0 in
parallelo a Ctot , sino a quando non ho un tempo di propagazione
doppio rispetto al precedente.
![]()
Questo è vero se C0=Ctot .
Così facendo ottengo la seguente tabella:
|
W (L=2) |
Capacità C0 (F) |
|
3 |
10.1 |
|
5 |
11.3 |
|
7 |
12.3 |
|
9 |
13.4 |
|
11 |
14.7 |
|
14 |
16.3 |
|
17 |
18.1 |
|
22 |
21 |
|
27 |
24.1 |
|
33 |
29.1 |
Interpoliamo
linearmente i risultati:

Scaliamo il circuito come in precedenza, ma sommando
alle capacità estratte da electric queste. Bisogna però prestare attenzione al
fatto che la capacità che dovrò considerare per il generico Pi,
dipenderà da quelle che lo seguono, ma anche da esso stesso. Imponiamo per
l’ultimo stadio un W/L=3/2 a cui corrisponde una capacità di crescita di 9.783F
. A questa va sommata quella di electric, cioè 1.31F e otteniamo 11.1F. Lo
stadio che lo precederà, dovrà scaricare
11.1F+4.06F(Electric)+[1.23(W/L)+7.983](la propria). Questa capacità divisa la
capacità del primo stadio moltiplicata per il fattore di forma del primo stadio
è proprio W/L cercato, cioè:

cioè,
considerando per tutti i mos un Li=2:
![]()
trovo
poi la capacità totale C6 , come:
![]()
per
la stadio successivo avrò:
![]()
Si
itera questo procedimento per tutti gli
altri stadi e troviamo:
|
MOS (P) |
Capacità Electric |
Capacità totale |
W(L=2) |
|
7 |
1.31 |
11.1 |
3 |
|
6 |
4.06 |
28 |
8 |
|
5 |
4.15 |
48 |
13 |
|
4 |
4.24 |
72.6 |
20 |
|
3 |
4.35 |
102 |
28 |
|
2 |
4.44 |
137 |
37 |
|
1 |
4.63 |
179 |
49 |
|
0 |
4.79 |
229 |
62 |
|
Inverter |
3.95 |
- |
78 |
E’ chiaro che così facendo l’inverter risulta
sovrastimato. In questo modo otteniamo il seguente layout di area 36183mm2:
|
|
|



Risulta evidente come il l’andamento non sia
lineare. Un primo problema è quello che
nel distribuire il multiplexer nel circuito ho modificato, inevitabilmente,
l’area di source e drain cambiando così il valore che avevo anzitempo stimato.
Un secondo problema più drammatico, è il fatto che il primo transistore si
scarica troppo rapidamente, senza attendere l’arrivo della corrente da parte
degli altri mos. Questo credo che sia
dovuto ha diversi fattori. Il primo che i mos hanno tempi accensione
differenti, il secondo che esiste un comportamento resistivo (la linea dei mos
è simile ad una linea di RC distribuite) che il modello empirico non considera.
Utilizzando un’analogia idraulica, è come se la resistenza provocasse un rallentamento della corrente
simile all’attrito così che, quando accendiamo i rubinetti, anche se il canale
è dimensionato correttamente, il primo fa in tempo a scaricarsi in gran parte
prima che sia giunta la corrente di quelli a valle. Questo viene supportato da
due fatti. Proviamo a scaricare più lentamente il primo mos tramite il termine
P, e non con il cin, e imponiamo che tutti gli altri siano già alti, otteniamo
un andamento lineare (abbiamo preso in considerazione il circuito del paragrafo
successivo in quanto i pass transistor entrano subito in conduzione). Inoltre se noi proviamo a dimensionare i pass
transistor con le stesse modalità, ma con correnti più importanti l’andamento
diventa lineare.
(abbiamo preso in considerazione il circuito del paragrafo
successivo in quanto i pass transistor entrano subito in conduzione). Inoltre se noi proviamo a dimensionare i pass
transistor con le stesse modalità, ma con correnti più importanti l’andamento
diventa lineare.
|
|

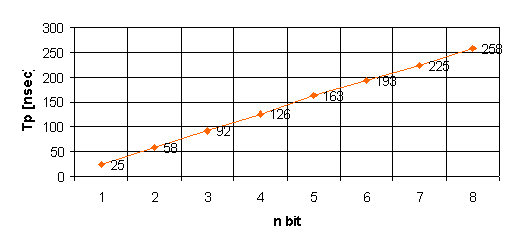
Notiamo come l’andamento sia diventato lineare,
utilizzando lo stesso metodo di scalutura, imponendo all’ultimo stadio un (W/L)=(10/2).
Quindi quello che possiamo fare è imporre un ritardo al primo mos che si
scarica troppo rapidamente. Molto semplicemente dimensioniamo l’inverter con un
nmos opportuno (7/2). Così facendo
otteniamo:
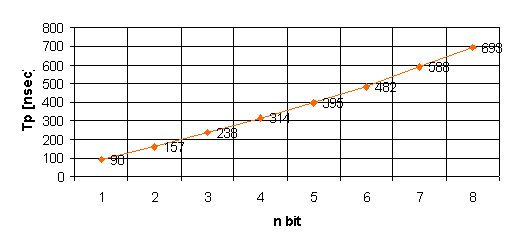
Il ritardo complessivo è dovuto al termine S7 ed è
pari a 1.015ns. E’ evidente che però perdiamo notevolmente in area, non aumenta
più linearmente.

6 MULTIPLEXER DINAMICO SCALATO SATURATO (M8V4)
Notiamo come se diminuiamo la tensione di precarica,
i pass transistor sotto la soglia Vdd-Vt entrano subito in conduzione o
comunque sia attraversano una fase di interdizione minore. In quanto dopo la
fase di precarica ho Vs= Vd= Vg= Vdd.
Quindi fino a quando Vsg>Vt non conduce. Se facciamo
in modo che Vs=Vd=Vdd-Vt e Vg=Vdd
ottengo Vsg=Vt .
Cioè basta una piccola differenza ai suoi capi ed entra subito in conduzione.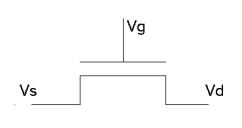 Otteniamo un miglioramento
del 18% rispetto a prima.
Otteniamo un miglioramento
del 18% rispetto a prima.

Ma vogliamo fare di più.
Modifichiamo l’xor responsabile del ritardo. Lo costruiamo in logica pseudonmos
per tre motivi: occupa meno area, più veloce e ha una capacità in ingresso più
piccola, quindi la scarica del riporto diventa più veloce. Perdiamo
evidentemente in immunità ai disturbi. Ricordiamo che i termini del Cin sono
invertiti, in quanto ho il suo negato e così, come in precedenza, evito di
inserire un ulteriore inverter.
|
|
|


Così facendo però i termini S6…S1 sono più lenti
rispetto al termine di Flag, quindi decidiamo di estendere l’xor in logica
pseudonmos anche a questi termini. Da un lato così recuperiamo il tempo di
propagazione del Flag, dall’altro abbiamo capacità in ingresso minore, quindi
più veloce la scarica del riporto. Inoltre cambiamo l’inverter in uscita,
realizzandolo in logica pseudonmos a carico saturato per velocizzare ancora di
più il termine Flag (dimensionato in modo da avere una simmetria intorno a
1.75V (0.9V,2.68V) ed avere una capacità più piccola a monte). Riscaliamo il
circuito come descritto in precedenza e otteniamo un tempo di propagazione di
soli 357ps con una occupazione di area di appena 32974mm2. Il caso peggiore l’abbiamo quando accendiamo i pass transistor.
Questo non è dovuto all’inverter in ingresso a cui non è stato applicato il
carico saturato, in quanto il pass transistor che lo segue al più può scrivere
un valore alto debole, ma ad effetti parassiti analizzati nel paragrafo
successivo.

|
|
|

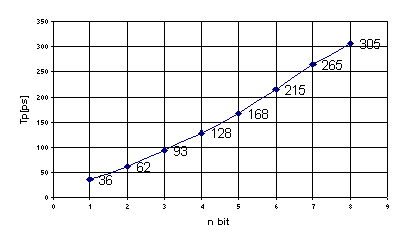
Perdiamo molto con questa scelta in immunità ai
disturbi in quanto diminuisco di una soglia logica l’uscita alta e qualcosa di
più quella bassa. In realtà il tempo di propagazione è dato dalla cella xor che
pilota il termine P dallo stato alto a quello basso, circa 455ps. A sinistra si
vede come il P0 scarica C0, in quanto non fa in tempo a
spegnersi. Avremmo dovuto realizzare uno xor più veloce, ma a priori non era
ipotizzabile il raggiungimento di tempi così veloci.
|
|
|


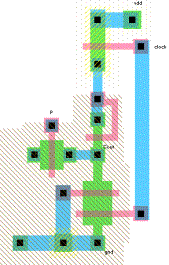
7 POSSIBILI OTTIMIZZAZIONI
Notiamo come se teniamo gli ingressi nulli fino ad
un certo istante (8ns), si ha un innalzamento della tensione.

Il circuito elementare responsabile è dato dal solo
Pmos di carica.
|
|
|


Questo fenomeno è dovuto ad effetti reattivi di
diversa natura: in parte alla corrente di sottoglia e in parte a
ridistribuzioni di carica quando noi spegniamo il pmos. Sappiamo inoltre come
alcune di queste capacità parassite, quelle di giunzione, hanno un andamento
simile a quelle del diodo, quindi variano in funzione della tensione applicata.
Essendo il circuito a vuoto (per il Manchester in alta impedenza) queste
capacità non sono trascurabili e pertanto danno luogo a questo fenomeno.
Infatti ponendo come carico una capacità, questo effetto risulta notevolmente
ridimensionato. Se si osserva la figura si nota come il problema si presenta
quando ![]() . Quindi una prima soluzione, può essere quella di abbreviare
la fase di interdizione, diminuendo la tensione di soglia, oppure la tensione Vg
, come mostrato in figura.
. Quindi una prima soluzione, può essere quella di abbreviare
la fase di interdizione, diminuendo la tensione di soglia, oppure la tensione Vg
, come mostrato in figura.
|
|
|


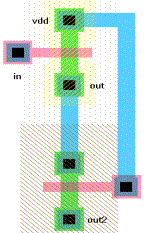
Ponendo un nmos in serie, la ridistribuzione di
carica coinvolge la sua uscita in modo molto minore. Se poi dimensioniamo i 2
mos, opportunamente riusciamo a desensibilizzare l’uscita out2 completamente da
questo fenomeno reattivo.
|
|
|

|
|
|
Abbiamo eliminato quelle salite che si vedevano.
|
|
|


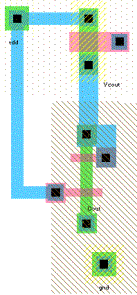
Un cosa analoga accade quando accendo il pass
transistor del termine P (si veda il transitorio tra 8n e 8.5n). Analizziamo il
seguente circuito:
|
|
|
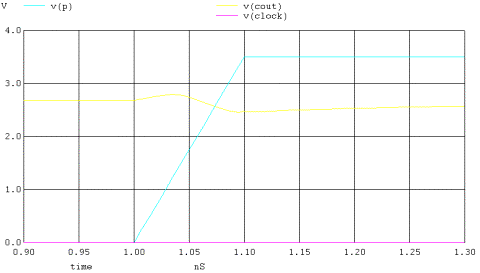
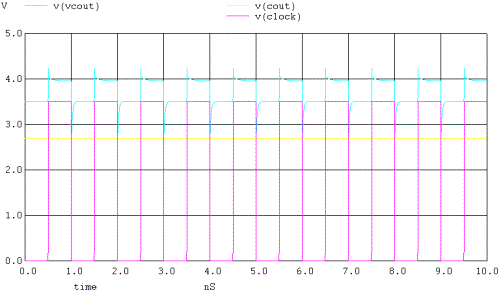
A frequenza elevate e con una rampa del termine p
più rilassata,questo picco si presenta in modo evidente dando luogo a quel
fenomeno visto in precedenza. Anche qui possiamo adottare una soluzione del
tutto analoga alla precedente.
|
|
|


Ovviamente la realizzazione di questa soluzione
comporta una scalatura ancora più impegnativa della precedente.
8 CONFRONTI TRA LE DIVERSE SOLUZIONI
|
|
V1STAT |
V2DIN |
V3DINS |
V4DINSSAT |
AREA [mm2]
|
39856 |
31515 |
36183 |
32974 |
|
|
+20.9% |
-4.4% |
+9.7% |
|
|
Tp [ps] |
3500 |
6000 |
1015 |
455 |
|
Freq[Mhz] |
285 |
83 |
492 |
1099 |
|
|
-74% |
-92% |
-55% |
|
|
CONS.[mW] |
6.9 |
2.3 |
6.5 |
15.1 |
|
|
-54% |
-85% |
-57% |
|
|
IMMUNITA’ DISTURBI (qualitativamente) |
***** |
**** |
**** |
* |




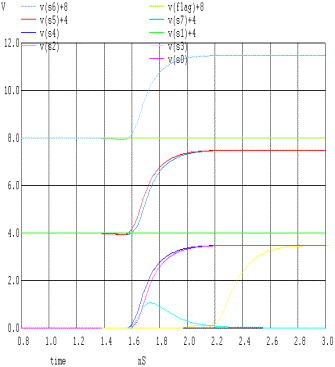
9 TEST
Eseguiamo dei test per verificare la correttezza logica dei circuiti con 3 casi random, per le sole versioni V1 e V2, in quanto le altre sono una estensione del circuito V2.
|
Cin |
0 |
|
||||||
|
A |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
|
B |
0 |
1 |
0 |
0 |
1 |
1 |
1 |
0 |
|
S |
1 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
|
Flag |
0 |
|
VERSIONE 1 |
VERSIONE 2 |
|
|
|

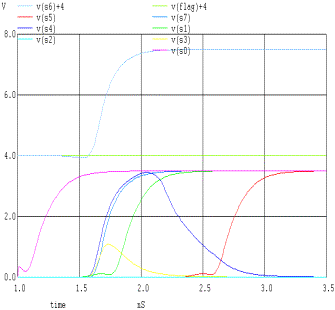
|
Cin |
1 |
|
||||||
|
A |
1 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
|
B |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
|
S |
1 |
1 |
0 |
0 |
0 |
1 |
1 |
1 |
|
Flag |
0 |
|
VERSIONE 1 |
VERSIONE 2 |
|
|
|

|
Cin |
0 |
|
||||||
|
A |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
|
B |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
1 |
|
S |
0 |
1 |
1 |
0 |
0 |
1 |
0 |
1 |
|
Flag |
1 |
|
VERSIONE 1 |
VERSIONE 2 |
|
|
|

