|
txt2sound
a new audio interaction with the written words based on the graphic forms of letters.
|

|
| ::introduction:: |
::how:: |
::concept:: |
::algorithm:: |
::conclusion:: |
::bibliography:: |
Introduction 
The work submitted by egø for con|text is an algorithm to create sound from written text (as image format). The algorithm is based
on the idea of the optophone1 developed also by
P.B.L. Meijer (see [4]). When egø wrote his algorithm, he didn't know the existence of the
optophone and of the research made by Mr. Mejer, however, for this occasion, he
wants to propose the algorithm in this context without any intention of stealing
other peoples ideas. The words converted to sound are capital letters,
because the form of these letters comes from the oldest signs of our western culture (see [3]).
|
|
How it works
It starts from an image with the written text: the algorithm create a map of the image from the spatial frequencies
domain
to the audio frequencies domain (see figure below). Vertical axis is the frequency (here is from 0 to 11
kHz) while horizontal axis is time.
|
|
|

|
|
Let's consider a column of the image: it is made by pixels with values from 0 to 1
(zero is a white pixel and one is a black pixel)2.
The lowest pixel in the column corresponds to the lowest frequency and so the highest pixel in the column
corresponds to the highest frequency. The algorithm makes a sum of the various frequencies (sinusoids) by relating to
each sine wave the amplitude of the corresponding pixel (from zero to one). For example, in a vertical line | the column is made
by pixels equal to one: so it is a superimposition of all the frequencies as in the formula:
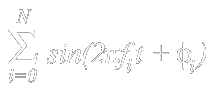
that is a white noise (white noise is made by uncorrelated superimposition of all frequencies). Instead, if the image contains a horizontal line
_ only one frequency will be heard. The map between text and sound is a linear map (this is due to the properties of the Fourier
transform; [6]), so, from the generated sound, we are able to get its original meaning, to recover the
written words with the use of a spectrograph3.
|
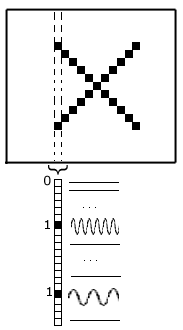
How the algorithm works.
|
The concept
Only the "graphical" aspect of words, the single letters, the sign, determine a different audio perception; this coding method
become a sort of a Morse code which is no more limited to the pulsating of a single frequency, but extended to all
audible (and not)
frequencies. Gadamer formerly said that "in written text it is asserted the separation of language from its effective being spoken" [1],
now words, letters, are no more related to sounds of past culture [3], there are no more "labial" sounds,
"guttural" sounds, etc... the whole is shifted towards a new sound, that Perniola would call "inorganic"
("sounds, spaces, objects, words: when they are removed from their usefulness, they acquire an undetermined and fresher aspect, more
splendent" [2]). A sound that is "out of the person", reducing words to
the superimposition of pure tones.
Listening to words like MAMA [ mp3],
LOVE [mp3],
SEX [mp3],
ART [mp3],
KILL [mp3]
in their new sound can left us dazed, puzzled; we are no more able to distinguish those words, those sounds that we would immediately
associate with the basic feelings they convey.
Also mathematical signs full of symbolism like "+" [mp3] or "-" [mp3]
now become almost identical. Paradoxically only the blank space, the absence of information, the nothingness, with its
symbolism, stays
unchanged and so it is able to show us a way, to lead us in the listening of these new sounds. mp3],
LOVE [mp3],
SEX [mp3],
ART [mp3],
KILL [mp3]
in their new sound can left us dazed, puzzled; we are no more able to distinguish those words, those sounds that we would immediately
associate with the basic feelings they convey.
Also mathematical signs full of symbolism like "+" [mp3] or "-" [mp3]
now become almost identical. Paradoxically only the blank space, the absence of information, the nothingness, with its
symbolism, stays
unchanged and so it is able to show us a way, to lead us in the listening of these new sounds.
|
"In written text it is asserted the separation of language from its effective being spoken".
Hans-Georg
Gadamer
|
The algorithm
Now let's see how the algorithm works by using a pseudocode notation
[5] (working implementations obviously change depending on the programming language used):
1. col[] = getColumnFromImage(); // col[] is a vector containing the pixels
// values of the column.
2. a[] = [flip(col[]), col[]]; // the column is extended with even symmetry
// to be computed in the FFT algorithm.
3. a[] = randomComplexNumbers[]*a[]; // the element in the vector for the FFT
// computation must have random phases
// (randomComplexNumber[] is a vector of random
// complex numbers whose absolute value is one).
// Random phase is needed because we want the
// different sines to be uncorrelated (otherwise, for
// example, white noise can't be built).
4. x[] = iFFT(a[]); // inverse fft algorithm (from frequency to time domain).
// now x contains the audio signal.
|
|
...and these 4
steps are repeated for each column of the image.
|
Final work
Finally, a famous aphorism by the poet Paul Claudel summarizes and concludes this egø's work.
The
poem is not made from these letters that I drive in like nails, but of the white which remains on the paper.
Paul Claudel
 mp3 mp3
(English
translation found on the web of
"O mon âme! Le
poème nest point fait de ces lettres que je plante comme des clous, mais du
blanc qui reste sur le papier").
|
"The
poem is not made from these letters that I drive in like nails, but of the white which remains on the paper".
Paul Claudel |
Bibliography
[1]. Hans-Georg
Gadamer "Verità e metodo" ed. Studi Bompiani
1983 (pp. 441-490). [Available in English as "Truth
and Method"]
[2]. Mario
Perniola "Il Sex appeal dellinorganico"
("the sex appeal of the inorganic") ed. Einaudi
1994, pp. 82-89 (pp.
162-168).
[3]. Adrian
Frutiger "Segni & Simboli"
ed. Stampa alternativa/Graffiti 1998 (pp. 121-133). [Available in English as
"Signs
and Symbols"]
[4]. P.B.L.
Meijer, "An Experimental System for Auditory Image
Representations", IEEE Transactions on Biomedical Engineering, Vol. 39, No.
2, pp. 112-121, Feb 1992. Available on the web here.
Check also his project "the
vOICe".
[5]. Thomas
H. Cormen, Charles E. Leierson, Ronald L. Rivest "Algorithms"
MIT press 1990 (pages 1-20, 776-800).
[6]. Alan
V. Oppenheim, Ronald W. Schafer "Discrete-Time
Signal Processing" Prentice Hall 1999 (pages 541-575, 629-650).
|
|