ANALISI
Il World Wide Web
Il World Wide Web (WWW) è un’ architettura software che consente
l’accesso a documenti collegati fra loro e distribuiti su un numero
elevatissimo di macchine collegate tramite la rete Internet.
La rapida diffusione delle connessioni a Internet è giustificata
dall’introduzione dell’ interfaccia utente grafica di utilizzo facile, anche per i principianti.
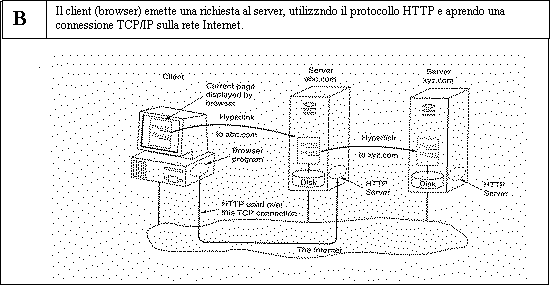
Il sistema WWW è basato sul modello client-server,
utilizza per la comunicazione il protocollo HTTP e per la scrittura delle pagine
WEB i linguaggi HTML e JAVA.
Il Lato client
Dal punto di vista utente il WEB è una vastissima collezione di documenti, chiamati pagine. Ogni pagina può contenere
collegamenti (link) ad altre pagine
dislocate in qualunque altro sistema nel mondo. L’utente accede in modo
automatico alla pagina collegata, semplicemente facendo un clic sul link. Una volta raggiunta la pagina
remota è possibile reiterare la richiesta su un altro link e così via.
Questa tecnica di utilizzo di link
fra varie pagine è detta ipertesto.
La pagina oltre al testo può contenere
icone, diagrammi, disegni,
immagini e suoni, cioè oggetti di natura differente, per cui si può
parlare di ipermedia. Ognuno di
questi oggetti può essere un link ad
altre pagine.
Il programma che si incarica di visualizzare le pagine sul client è detto browser (o sfogliatore) . Il browser
provvede a recuperare la pagina richiesta tramite il link, eventualmente collegandosi alla macchina su cui risiede la
pagina, interpreta il testo e i comandi formattati che la pagina contiene e
visualizza la pagina sullo schermo.
L’acquisizione di una pagina remota avviene attraversando la rete
Internet e utilizzando il protocollo di rete TCP/IP. Per ogni richiesta remota
è aperta una connessione TCP/IP che viene rilasciata alla
ricezione completa della pagina.
Il Lato Server
Il Server Web ha
costantemente attivo un processo in attesa di richieste di connessioni TCP/IP da parte dei client. Dopo
che una connessione è stata stabilita, il client
invia una richiesta al server che risponde con la pagina desiderata; a questo
punto la connessione viene rilasciata. Il protocollo che definisce la sintassi
delle richieste e delle risposte è detto HTTP (HyperText Transfer
Protocol). Una pagina del WEB è identificata da un
indirizzo detto URL (Uniform Resource Locator).
Un URL è ad esempio il seguente : http://www.w3.org/hypertext/WWW/TheProject.html
ed è costituito da tre parti fondamentali: il nome del
protocollo (es. HTTP, FTP, ecc.), il nome della
macchina (sito) dove la pagina risiede (es. www.w3.org),
il nome del file contenente la pagina, come percorso completo (es. hypertext/WWW/TheProject.html). I nomi dei siti e i relativi
indirizzi IP di Internet sono registrati
in un database che è gestito da un servizio di Internet detto DNS (Domain name Services): esso fornisce l’indirizzo IP corrispondente a un nome di sito e per i nuovi siti permette di non
assegnare nomi e indirizzi già utilizzati.
Il colloquio client-server
Quando un utente, da una pagina WEB attiva un link, ad esempio: http://www.w3.org/hypertext/WWW/TheProject.html, si attiva un colloquio con il server che
avviene nei seguenti passi:
1)
Il
browser determina il corrispondente URL (associato al link).
2)
Il
browser chiede al DNS l’indirizzo IP corrispondente al link (es. www.w3.org)
3)
Il
DNS risponde con l’indirizzo IP (es. 18.23.0.23).
4)
Il
browser attiva una connessione TCP/IP verso il server (IP 18.23.0.23).
5) Il client (browser) invia un
comando di GET per recuperare la pagina
(es. GET
/hypertext/WWW/TheProject.html).
6)
Il
server (all’indirizzo logico www.w3.org) invia il file TheProject.html contenente
la pagina.
7)
La
connessione TCP/IP è rilasciata.
8)
Il
browser visualizza il testo della
pagina sul monitor del client.
9)
Il
browser recupera e visualizza le
immagini della pagina.
Il protocollo HTTP
Il protocollo standard per colloquiare nel WEB tra client e server è l’ HTTP (HyperText Transfer Protocol) . Esso è
un protocollo basato sul codice ASCII, cioè sia le richieste, sia
le risposte sono basate su un formato sintattico che è un testo; non vengono
usati comandi formattati in binario. Il protocollo HTTP è basato su due gruppi di
messaggi: l’insieme di richieste (dal client al server),
l’insieme di risposte (dal server al client).
La comunicazione è basta su due tipologie di messaggi:
-
Request: è il messaggio inoltrato
dal client al server e specifica una
particolare operazione da eseguire;
-
Reply: è il messaggio di risposta
spedito dal server al client e contiene i risultati
dell’operazione (ad esempio la pagina richiesta, un messaggio di errore, un
messaggio di conferma).
Esempi di messaggi di Request sono:
GET: Richiede di acquisire una
pagina WEB .
HEAD: Richiede di leggere
l’intestazione (Header) di una pagina
WEB .
PUT: Richiede di memorizzare
sul server una pagina WEB
POST: Richiede di inviare i dati
immessi dall’utente a una risorsa nominata (es. programma di elaborazione).
DELETE: Richiede di rimuovere una
pagina WEB dal server.
LINK: Connette due risorse
esistenti.
UNLINK: Rilascia un’esistente
connessione tra due risorse.
I messaggi di request hanno una struttura del tipo: Request = <header, body >.
L’header può contenere diverse voci e
diverse opzioni ma la prima riga deve essere strutturata come segue:
Method SP Request – URI SP
Version CRLF
Il Method può essere GET, POST, ecc. e indica quale operazione deve essere eseguita dal server. Il Request-URI è la risorsa richiesta (tipicamente un file corrispondente alla pagina
WEB). Version
è la versione del protocollo, ad esempio nel caso di release 1.0 sarà “HTTP/1.0”. SP indica il carattere spazio
e CRLF (Carriage Return Line Feed)
lo spostamento a una nuova riga. Esempi di messaggi sono i seguenti:
GET
/main.html HTTP/1.0
GET
/images/test.gif HTTP/1.0
Per quanto riguarda il messaggio di risposta la struttura è la stessa:
Response = <header, body>.