Come funziona World Wide WebWorld Wide Web tra tutte le applicazioni disponibili sulla rete Internet è quella che gode della maggiore diffusione presso gli utenti, e che ne rappresenta per così dire la 'punta di diamante'. Per moltissimi utenti essa coincide addirittura con Internet. Se questa sovrapposizione, come sappiamo, è tecnicamente scorretta, è pur vero che la maggior parte delle risorse attualmente disponibili on-line si colloca proprio nel contesto del Web. D'altra parte, anche se consideriamo il complesso di innovazioni tecnologiche che negli ultimi anni hanno investito la rete modificandone il volto, ci accorgiamo che la quasi totalità si colloca nell'area Web. Per queste ragioni abbiamo ritenuto opportuno dedicare un intero capitolo alla descrizione del funzionamento di World Wide Web e dei vari linguaggi e sistemi su cui esso si basa. Come sappiamo l'architettura originaria del Web è stata sviluppata da Tim Berners Lee. Alla sua opera si devono l'elaborazione e l'implementazione dei principi, dei protocolli e dei linguaggi su cui ancora oggi in gran parte riposa il funzionamento di questa complessa applicazione di rete. Tuttavia, quando fu concepito, il Web era destinato ad una comunità di utenti limitata, non necessariamente in possesso di particolari competenze informatiche ed editoriali, e non particolarmente preoccupata degli aspetti qualitativi e stilistici nella presentazione dell'informazione. Per questa ragione nello sviluppo dell'architettura Web furono perseguiti espressamente gli obiettivi della semplicità di implementazione e di utilizzazione. Queste caratteristiche hanno notevolmente contribuito al successo del Web. Ma con il successo lo spettro dei fornitori di informazione si è allargato: World Wide Web è diventato un vero e proprio sistema di editoria elettronica on-line. Ovviamente l'espansione ha suscitato esigenze e aspettative che non erano previste nel progetto originale, stimolando una serie di revisioni e di innovazioni degli standard tecnologici originari. L'aspetto che ha suscitato maggiore interesse è il potenziamento della capacità di gestione e controllo dei documenti multimediali pubblicati su Web, e dunque dei linguaggi utilizzati per la loro creazione. Un ruolo propulsivo in questo processo è stato assunto dalle grandi aziende produttrici di browser. Nel corso degli anni tanto Microsoft quanto Netscape, man mano che nuove versioni dei loro browser venivano sviluppate, hanno introdotto innovazioni ed estensioni, al fine di conquistare il maggior numero di fornitori di servizi e dunque di utenti (infatti le nuove caratteristiche, almeno in prima istanza, erano riconosciute e interpretate correttamente solo dai rispettivi browser). Questa corsa all'ultima innovazione, se molto ha migliorato l'aspetto e la fruibilità delle pagine pubblicate su Web, ha avuto degli effetti deleteri sul piano della portabilità dei documenti [81]. Qualcuno in passato ha addirittura paventato una balcanizzazione di World Wide Web [82]. Per ovviare al rischio di una 'babele telematica', ed evitare che le tensioni indotte dal mercato limitassero l'universalità di accesso all'informazione on-line, è stato costituito il World Wide Web Consortium (W3C). Si tratta di una organizzazione no profit ufficialmente deputata allo sviluppo degli standard tecnologici per il Web che raccoglie centinaia di aziende, enti e centri di ricerca coinvolti più o meno direttamente nel settore. Il lavoro si articola per commissioni e gruppi di lavoro, che producono bozze tecniche di lavoro (working drafts). Ogni proposta viene poi sottoposta ad un processo di verifica e di revisione, finché non viene approvata dal consiglio generale e diventa una 'raccomandazione' (recommendation), alla quale è possibile far riferimento per sviluppare software. In questi ultimi anni il W3C ha prodotto una serie di specifiche divenute, o in procinto di divenire, standard ufficiali su Internet. Tutti i materiali prodotti dal W3C sono di pubblico dominio, e vengono pubblicati sul sito Web del consorzio. La maggior parte delle tecnologie di cui parleremo nei prossimi paragrafi sono state elaborate o sono tuttora in corso di elaborazione in tale sede. Naturalmente la nostra trattazione si limiterà a fornire delle semplici introduzioni che non pretendono di esaurire i temi trattati. Il nostro scopo è di fornire ai lettori più curiosi e consapevoli alcune nozioni su quello che c'è dentro la scatola, e di suscitare curiosità e stimoli ad approfondire i temi trattati. A tale fine, oltre alla bibliografia, ormai sterminata, sull'argomento, rimandiamo al sito del W3C, il cui indirizzo è http://www.w3.org, e a quello della IETF, alla URL http://www.ietf.org; in entrambi i siti è possibile reperire aggiornamenti costanti, documentazione e rapporti sull'attività di innovazione e di standardizzazione. Due concetti importanti: multimedia e ipertestoI primi argomenti che è necessario affrontare in una trattazione sul funzionamento di World Wide Web sono i concetti di ipertesto e di multimedia. Il Web, infatti, può essere definito come un ipertesto multimediale distribuito: è dunque chiaro che tali concetti delineano la cornice generale nella quale esso e tutte le tecnologie sottostanti si inseriscono. Ormai da diversi anni i termini ipertesto e multimedia sono usciti dagli ambiti ristretti degli specialisti, per ricorrere con frequenza crescente nei contesti più disparati, dalla pubblicistica informatica fino alle pagine culturali dei quotidiani. Naturalmente tanta inflazione genera altrettanta confusione, anche perché in fatto di tecnologie la pubblicistica mostra spesso una assoluta mancanza di rigore, quando non ci si trova di fronte a vera e propria incompetenza. Questo paragrafo intende fornire, in poche righe, una breve introduzione a questi concetti: alcuni minimi strumenti terminologici e teorici necessari per comprendere il funzionamento di World Wide Web. In primo luogo è bene distinguere il concetto di multimedialità da quello di ipertesto. I due concetti sono spesso affiancati e talvolta sovrapposti, ma mentre il primo si riferisce agli strumenti della comunicazione, il secondo riguarda la sfera più complessa della organizzazione dell'informazione. Con multimedialità, dunque, ci si riferisce alla possibilità di utilizzare contemporaneamente, in uno stesso messaggio comunicativo, più media e/o più linguaggi [83]. Da questo punto di vista, possiamo dire che una certa dose di multimedialità è intrinseca in tutte le forme di comunicazione che l'uomo ha sviluppato e utilizzato, a partire dalla complessa interazione tra parola e gesto, fino alla invenzione della scrittura, dove il linguaggio verbale si fonde con l'iconicità del linguaggio scritto (si pensi anche - ma non unicamente - alle scritture ideografiche), e a tecnologie comunicative più recenti come il cinema o la televisione. Nondimeno l'informatica - e la connessa riduzione di linguaggi diversi alla 'base comune' rappresentata dalle catene di 0 e 1 del mondo digitale - ha notevolmente ampliato gli spazi 'storici' della multimedialità. Infatti attraverso la codifica digitale si è oggi in grado di immagazzinare in un unico oggetto informativo, che chiameremo documento, pressoché tutti i linguaggi comunicativi usati dalla nostra specie: testo, immagine, suono, parola, video. I documenti multimediali sono oggetti informativi complessi e di grande impatto. Ma oltre che nella possibilità di integrare in un singolo oggetto diversi codici, il nuovo orizzonte aperto dalla comunicazione su supporto digitale risiede nella possibilità di dare al messaggio una organizzazione molto diversa da quella cui siamo abituati da ormai molti secoli. È in questo senso che la multimedialità informatica si intreccia profondamente con gli ipertesti, e con l'interattività. Vediamo dunque cosa si intende con il concetto di ipertesto. La definizione di questo termine potrebbe richiedere un volume a parte (ed esistono realmente decine di volumi che ne discutono!). La prima formulazione moderna dell'idea di ipertesto si trova nel già ricordato articolo del tecnologo americano Vannevar Bush, As We May Think, apparso nel 1945, dove viene descritta una complicata macchina immaginaria, il Memex (contrazione di Memory extension). Si trattava di una sorta di scrivania meccanizzata dotata di schermi per visualizzare e manipolare documenti microfilmati, e di complicati meccanismi con cui sarebbe stato possibile costruire legami e collegamenti tra unità informative diverse. Secondo Bush un dispositivo come questo avrebbe aumentato la produttività intellettuale perché il suo funzionamento imitava il meccanismo del pensiero, basato su catene di associazioni mentali. La sintesi tra le suggestioni di Bush e le tecnologie informatiche è stata opera di Ted Nelson, che ha anche coniato il termine 'ipertesto', agli inizi degli anni sessanta. Nel suo scritto più famoso e importante, Literary Machines - un vero e proprio manifesto dell'ipertestualità - questo geniale e anticonformista guru dell'informatica statunitense descrive un potente sistema ipertestuale, battezzato Xanadu [84]. Nella utopica visione di Nelson, Xanadu era la base di un universo informativo globale e orizzontale - da lui definito docuverse (docuverso) - costituito da una sconfinata rete ipertestuale distribuita su una rete mondiale di computer. Il progetto Xanadu non è mai stato realizzato concretamente, nonostante i molti tentativi cui Nelson ha dato vita. Ma le sue idee sono confluite molti anni più tardi nella concezione di World Wide Web. In questa sede non possiamo affrontare compiutamente tutti gli aspetti teorici e pratici connessi con questo tema, ma solo fornire alcuni elementi esplicativi. In primo luogo, per comprendere cosa sia un ipertesto è opportuno distinguere tra aspetto logico-astratto e aspetto pratico-implementativo. Dal punto di vista logico un ipertesto è un sistema di organizzazione delle informazioni (testuali, ma non solo) in una struttura non sequenziale, bensì reticolare. Nella cultura occidentale, a partire dalla invenzione della scrittura alfabetica, e in particolare da quella della stampa, l'organizzazione dell'informazione in un messaggio, e la corrispondente fruizione della stessa, è essenzialmente basata su un modello lineare sequenziale, su cui si può sovrapporre al massimo una strutturazione gerarchica. Per capire meglio cosa intendiamo basta pensare ad un libro, il tipo di documento per eccellenza della modernità: un libro è una sequenza lineare di testo, eventualmente organizzato come una sequenza di capitoli, che a loro volta possono essere organizzati in sequenze di paragrafi, e così via. La fruizione del testo avviene pertanto in modo sequenziale, dalla prima all'ultima pagina. Certo sono possibili deviazioni (letture 'a salti', rimandi in nota), ma si tratta di operazioni 'innestate' in una struttura nella quale prevale la linearità. L'essenza stessa della razionalità e della retorica occidentale riposa su una struttura lineare dell'argomentazione. Un ipertesto invece si basa su un'organizzazione reticolare dell'informazione, ed è costituito da un insieme di unità informative (i nodi) e da un insieme di collegamenti (detti nel gergo tecnico link) che da un nodo permettono di passare ad uno o più altri nodi. Se le informazioni che sono collegate tra loro nella rete non sono solo documenti testuali, ma in generale informazioni veicolate da media differenti (testi, immagini, suoni, video), l'ipertesto diventa multimediale, e viene definito ipermedia. Una idea intuitiva di cosa sia un ipertesto multimediale può essere ricavata dalla figura seguente.
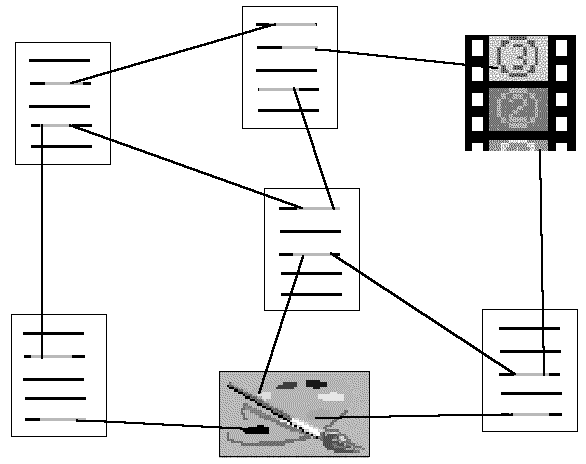
I documenti, l'immagine e il filmato sono i nodi dell'ipertesto, mentre le linee rappresentano i collegamenti (link) tra i vari nodi: il documento in alto, ad esempio, contiene tre link, da dove è possibile saltare ad altri documenti o alla sequenza video. Il lettore (o forse è meglio dire l'iper-lettore), dunque, non è vincolato dalla sequenza lineare dei contenuti di un certo documento, ma può muoversi da una unità testuale ad un'altra (o ad un blocco di informazioni veicolato da un altro medium) costruendosi ogni volta un proprio percorso di lettura. Naturalmente i vari collegamenti devono essere collocati in punti in cui il riferimento ad altre informazioni sia semanticamente rilevante: per un approfondimento, per riferimento tematico, per contiguità analogica. In caso contrario si rischia di rendere inconsistente l'intera base informativa, o di far smarrire il lettore in peregrinazioni prive di senso. Dal punto di vista della implementazione concreta, un ipertesto digitale si presenta come un documento elettronico in cui alcune porzioni di testo o immagini presenti sullo schermo, evidenziate attraverso artifici grafici (icone, colore, tipo e stile del carattere), rappresentano i diversi collegamenti disponibili nella pagina. Questi funzionano come dei pulsanti che attivano il collegamento e consentono di passare, sullo schermo, al documento di destinazione. Il pulsante viene 'premuto' attraverso un dispositivo di input, generalmente il mouse, una combinazioni di tasti, o un tocco su uno schermo touch-screen. In un certo senso, il concetto di ipertesto non rappresenta una novità assoluta rispetto alla nostra prassi di fruizione di informazioni testuali. La struttura ipertestuale infatti rappresenta una esaltazione 'pluridimensionale' del meccanismo testo/nota/riferimento bibliografico/glossa, che già conosciamo sia nei manoscritti sia nelle pubblicazioni a stampa. In fondo, il modo di lavorare di uno scrittore nella fase di preparazione del suo materiale è quasi sempre ipertestuale, così come l'intertestualità soggiacente alla storia della letteratura e allo sviluppo dei generi (dove 'letteratura' e 'generi' vanno presi nel loro senso ampio di produzione testuale, non esclusivamente dotata di valore estetico) costituisce un ipertesto virtuale che si genera nella mente di autore e lettore. Tuttavia, le tecnologie informatiche consentono per la prima volta di portare almeno in parte in superficie questo universo pre-testuale e post-testuale, per farlo diventare una vera e propria forma del discorso e dell'informazione. L'altro aspetto che fa dell'ipertesto elettronico uno strumento comunicativo dalle enormi potenzialità è la interattività che esso consente al fruitore, non più relegato nella posizione di destinatario più o meno passivo del messaggio, ma capace di guidare e indirizzare consapevolmente il suo atto di lettura. L'incontro tra ipertesto, multimedialità e interattività rappresenta dunque la nuova frontiera delle tecnologie comunicative. Il problema della comprensione teorica e del pieno sfruttamento delle enormi potenzialità di tali strumenti, specialmente in campo didattico, pedagogico e divulgativo (così come in quello dell'intrattenimento e del gioco), è naturalmente ancora in gran parte aperto: si tratta di un settore nel quale vi sono state negli ultimi anni - ed è legittimo aspettarsi negli anni a venire - innovazioni di notevole portata. L'architettura e i protocolli di World Wide WebIl concetto di ipertesto descrive la natura logica di World Wide Web. Si tratta infatti di un insieme di documenti multimediali interconnessi a rete mediante molteplici collegamenti ipertestuali e memorizzati sui vari host che costituiscono Internet. Ciascun documento considerato dal punto di vista dell'utente viene definito pagina Web, ed è costituito da testo, immagini fisse e in movimento, in definitiva ogni tipo di oggetto digitale. Di norma le pagine Web sono riunite in collezioni riconducibili ad una medesima responsabilità autoriale o editoriale, e talvolta, ma non necessariamente, caratterizzate da coerenza semantica, strutturale o grafica. Tali collezioni sono definiti siti Web. Se consideriamo il Web come un sistema di editoria on-line, i singoli siti possono essere assimilati a singole pubblicazioni. Attivando uno dei collegamenti contenuti nella pagina correntemente visualizzata, essa viene sostituita dalla pagina di destinazione, che può trovarsi su un qualsiasi computer della rete. In questo senso utilizzare uno strumento come Web permette di effettuare una sorta di navigazione in uno spazio informativo astratto, uno degli esempi del cosiddetto ciberspazio. Ma quali tecnologie soggiacciono a tale spazio astratto? In linea generale l'architettura informatica di World Wide Web non differisce in modo sostanziale da quella delle altre applicazioni Internet. Anche in questo caso, infatti, ci troviamo di fronte ad una sistema basato su una interazione client-server, dove le funzioni elaborative sono distribuite in modo da ottimizzare l'efficienza complessiva. Il protocollo di comunicazione tra client e server Web si chiama HyperText Transfer Protocol (HTTP). Si tratta di un protocollo applicativo che a sua volta utilizza gli stack TCP/IP per inviare i dati attraverso la rete. La prima versione di HTTP è stata sviluppata da Tim Berners Lee ed ha continuato a far funzionare il Web per molti anni prima che venisse aggiornata alla versione 1.1, caratterizzata da una serie di migliorie sul piano dell'efficienza (HTTP/1.1 utilizza una sola connessione TCP per trasmettere dati e definisce delle regole per il funzionamento della cache sul lato client) e della sicurezza delle transazioni. A differenza di altre applicazioni Internet, tuttavia, il Web definisce anche dei formati o linguaggi specifici per i tipi di dati che possono essere inviati dal server al client. Tali formati e linguaggi specificano la codifica dei vari oggetti digitali che costituiscono un documento, e il modo di rappresentare i collegamenti ipertestuali che lo legano ad altri documenti. Tra essi ve ne è uno che assume un ruolo prioritario nel definire struttura, contenuto e aspetto di un documento/pagina Web: attualmente si tratta del linguaggio HyperText Markup Language (HTML). Un client Web costituisce lo strumento di interfaccia tra l'utente e il sistema Web; le funzioni principali che esso deve svolgere sono:
I client Web vengono comunemente chiamati browser, dall'inglese to browse, scorrere, sfogliare, poiché essi permettono appunto di scorrere le pagine visualizzate. Poiché tuttavia la fruizione di una pagina Web non è riconducibile formalmente alla sola visualizzazione, nei documenti tecnici si preferisce la formula user agent, che cattura in modo più astratto il ruolo funzionale svolto dal client. Un server Web, o più precisamente server HTTP, per contro, si occupa della gestione, del reperimento e dell'invio dei documenti (ovvero dei vari oggetti digitali che li costituiscono) richiesti dai client. Nel momento in cui l'utente attiva un collegamento - agendo su un link - o specifica esplicitamente l'indirizzo di un documento, il client invia una richiesta HTTP (HTTP request) al server opportuno con l'indicazione del documento che deve ricevere. Questa richiesta viene interpretata dal server, che a sua volta invia gli oggetti che compongono il documento richiesto corredati da una speciale intestazione HTTP che ne specifica il tipo. Tale specificazione si basa sui codici di tipo definiti dalla codifica MIME (o MIME type), nata per la posta elettronica. Se necessario, il server prima di inviare i dati può effettuare delle procedure di autenticazione, in modo da limitare l'accesso a un documento a utenti autorizzati e in possesso di password.
In realtà per svolgere le sue mansioni un server HTTP può agire in due modi, a seconda che il documento richiesto dal client sia statico o dinamico. Un documento Web statico è costituito da una serie di oggetti digitali memorizzati in file, che vengono generati una volta per tutte e messi in linea a disposizione degli utenti, fino a quando il gestore di sistema non decide di modificarli o di rimuoverli. Quando il server riceve una richiesta che si riferisce a un documento statico, non deve far altro che individuare sulle proprie memorie di massa i vari file di cui si compone e inviarne delle copie al client. Un documento Web dinamico, invece, è un documento i cui componenti vengono elaborati e composti solo nel momento in cui arriva una richiesta esplicita. Questo tipo di documenti sono utilizzati nei casi in cui è necessario generare dei contenuti in maniera dinamica, in modo automatico o in risposta ad una operazione interattiva effettuata dall'utente: ad esempio per aggiornare automaticamente i valori contenuti in una tabella numerica o per inviare, inseriti in un opportuno contesto, i risultati di una ricerca su un database. Naturalmente il server Web in quanto tale non è in grado di effettuare queste elaborazioni dinamiche. Per farlo si deve appoggiare a programmi esterni o a librerie di funzioni chiamate in modo dinamico. Molteplici tecnologie sono state sviluppate a tale fine. La più 'rudimentale' si basa sulla cosiddetta Common Gateway Interface (CGI). Si tratta di un insieme di comandi e di variabili di memoria attraverso cui il server Web può comunicare con altre applicazioni e programmi autonomi. Tali programmi ricevono dal server un messaggio in cui viene richiesta una data elaborazione (ad esempio un sistema di gestione di database può ricevere la richiesta di effettuare una ricerca mediante alcune chiavi), la effettuano, e restituiscono l'output (nel nostro caso il risultato della ricerca) ad un altro programma che lo codifica in un formato legale sul Web, il quale viene a sua volta restituito al server HTTP che infine provvede ad inviarlo al client. I server Web più moderni, tuttavia, adottano tecnologie più evolute e soprattutto più efficienti per generare pagine dinamiche. Queste tecnologie si basano sulla integrazione delle funzionalità elaborative direttamente nel server, mediante librerie binarie dinamiche. Poiché tutte le operazioni vengono svolte da un unico software nel medesimo spazio di memoria e l'interazione tra moduli avviene a livello binario, la velocità di esecuzione e l'occupazione di memoria ne risultano notevolmente ottimizzate. Esempi di queste tecnologie sono il sistema Active Server Pages (ASP), implementato nell'Internet Information Server della Microsoft, quello basato su ISAPI e Java dei server Netscape, e quello basato su un interprete Perl (Perl module) del server Apache. Un'altra tipica funzione svolta dal server è la gestione di transazioni economiche, quali la registrazione di un acquisto fatto con carta di credito. Dal punto di vista tecnico questa operazione non differisce molto dalla normale consultazione o aggiornamento di un database. Ma ovviamente i problemi di affidabilità e di sicurezza in questo caso sono molto più rilevanti: per questo sono stati sviluppati dei server HTTP specializzati nella gestione di transazioni economiche sicure attraverso complesse tecnologie di cifratura di dati (ne tratteremo più avanti). I linguaggi del WebCome abbiamo anticipato nel paragrafo precedente, a differenza delle altre applicazioni Internet, World Wide Web, oltre ai protocolli applicativi, definisce anche dei formati specifici per codificare i documenti che vi vengono immessi e distribuiti. I documenti che costituiscono la rete ipertestuale del Web sono principalmente documenti testuali, ai quali possono essere associati oggetti grafici (fissi o animati) e in taluni casi moduli software. In generale, comunque, struttura, contenuti e aspetto di una pagina Web visualizzata da un dato user agent sono definiti interamente nel documento testuale che ne costituisce l'oggetto principale. Tale definizione attualmente si basa su uno speciale linguaggio di rappresentazione dei documenti in formato elettronico, appartenente alla classe dei markup language (linguaggi di marcatura), denominato HyperText Markup Language (HTML). La formalizzazione di HTML, effettuata da uno dei gruppi di lavoro del W3C, è oggi completamente stabilizzata e tutti i browser disponibili sono in grado di interpretarne la sintassi e di rappresentare opportunamente i documenti in base ad essa codificati. Tuttavia, a causa di una serie di limiti che HTML presenta, lo stesso W3C ha recentemente definito un linguaggio più potente e versatile per la creazione di documenti da distribuire su Web, denominato Extensible Markup Language (XML). Accanto a questo nuovo linguaggio sono stati formalizzati o sono in via di formalizzazione una serie di altri linguaggi che complessivamente trasformeranno l'intera architettura del Web, aumentandone capacità e versatilità. Nei prossimi paragrafi cercheremo di fornire ai lettori alcune nozioni di base sui principi e sulla natura di tutti questi linguaggi del Web. La rappresentazione elettronica dei documenti: i linguaggi di markup e SGMLL'informatica mette a disposizioni diverse classi di formalismi per rappresentare dei documenti testuali su supporto elettronico. I più elementari sono i sistemi di codifica dei caratteri. Essi rappresentano il 'grado zero' della rappresentazione di un testo su supporto digitale, e sono alla base di tutti i sistemi più sofisticati: in linea generale ogni documento digitale è costituito da un flusso di caratteri (o stringa). Il carattere è l'unità atomica per la rappresentazione, l'organizzazione e il controllo di dati testuali sull'elaboratore. Come qualsiasi altro tipo di dati, anche i caratteri vengono rappresentati all'interno di un elaboratore mediante una codifica numerica binaria. Per la precisione, prima si stabilisce una associazione biunivoca tra gli elementi di una collezione di simboli (character repertoire) e un insieme di codici numerici (code set). L'insieme risultante viene denominato tecnicamente coded character set. Per ciascun coded character set, poi, si definisce una codifica dei caratteri (character encoding) basata su un algoritmo che mappa una o più sequenze di 8 bit (ottetto) al numero intero che rappresenta un dato carattere in un coded character set. Come alcuni lettori sapranno, esistono diversi coded character set - alcuni dei quali sono stati definiti da enti di standardizzazione nazionali e internazionali (ISO e ANSI in primo luogo) - che si differenziano per il numero di cifre binarie che utilizzano, e dunque per il numero di caratteri che possono codificare. Tra questi il più antico e diffuso è il cosiddetto codice ASCII (American Standard Code for Information Interchange), la cui versione internazionale si chiama ISO 646 IRV. Esso utilizza solo 7 bit e di conseguenza contiene 128 caratteri, tra cui i simboli alfabetici dall'alfabeto anglosassone e alcuni simboli di punteggiatura. La diffusione dei computer ha naturalmente determinato l'esigenza di rappresentare i caratteri di altri alfabeti. Sono stati così sviluppati molteplici code set che utilizzano un intero ottetto (e dunque sono dotati di 256 posizioni) e che hanno di volta in volta accolto i simboli dei vari alfabeti latini. Tra di essi ricordiamo la famiglia ISO 8859, nel cui ambito particolarmente diffuso è il code set ISO 8859-1, meglio conosciuto come ISO Latin 1. Esso contiene i caratteri principali delle lingue occidentali con alfabeti latini, ed è usato da molte applicazioni su Internet (ad esempio World Wide Web), e da molti sistemi operativi. Il più completo ed evoluto standard per la codifica di caratteri attualmente disponibile è l'ISO 10646-1, rilasciato nel 1993. Esso definisce lo Universal Character Set, un coded character set basato su una codifica a 31 bit (oltre due miliardi di possibili caratteri, da cui il nome). In realtà il numero di caratteri attualmente codificati ammonta a 38.887. Esso coincide praticamente con l'omologo set a 16 bit (65536 combinazioni) Unicode, sviluppato autonomamente da una organizzazione privata, lo Unicode Consortium, per poi convergere con lo standard ISO a partire dalla versione 2. La codifica dei caratteri, naturalmente, non esaurisce i problemi della rappresentazione elettronica di un documento. Se prendiamo un qualsiasi testo a stampa, già una semplice analisi ci permette di evidenziare una serie di fenomeni: la segmentazione del testo in macrounità, la presenza di titoli e sottotitoli, le enfasi, etc. Per rappresentare su supporto informatico tutte le caratteristiche grafiche e strutturali di un documento, pertanto, vanno adottati formalismi più complessi. Tra questi vi sono i cosiddetti markup language, linguaggi di marcatura. L'espressione markup deriva dalla analogia tra questi linguaggi e le annotazioni inserite da autori, curatori editoriali e correttori nei manoscritti e nella bozze di stampa di un testo al fine di indicare correzioni e trattamenti editoriali, chiamate in inglese mark up. In modo simile, i linguaggi di marcatura sono costituiti da un insieme di istruzioni, dette tag (marcatori), che servono a descrivere la struttura, la composizione e l'impaginazione del documento. I marcatori sono sequenze di normali caratteri ASCII, e vengono introdotti, secondo una determinata sintassi, all'interno del documento, accanto alla porzione di testo cui si riferiscono. In modo simile ai linguaggi di programmazione, anche i linguaggi di markup sono divisi in due tipologie:
Il primo tipo (i cui testimoni più illustri sono lo Script, il TROFF, il TEX) sono costituiti da istruzioni operative che indicano la struttura tipografica della pagina (il lay-out), le spaziature, l'interlineatura, i caratteri usati. Questo tipo di linguaggi sono detti procedurali in quanto istruiscono un programma di elaborazione circa le procedure di trattamento cui deve sottoporre la sequenza di caratteri al momento della stampa. Nei linguaggi dichiarativi, invece, i marcatori sono utilizzati per assegnare ogni porzione di testo ad una certa classe di caratteristiche testuali; essi permettono di descrivere la struttura astratta di un testo. Il testimone più illustre di questa seconda classe di linguaggi di markup è lo Standard Generalized Markup Language (SGML). Ideato da Charles Goldfarb, SGML è divenuto lo standard ufficiale adottato dalla International Standardization Organization (ISO) per la creazione e l'interscambio di documenti elettronici. La pubblicazione dello standard risale al 1986, ma solo da pochi anni SGML ha cominciato a guadagnare consensi, e ad essere utilizzato in un vasto spettro di applicazioni concrete [85]. Per la precisione, più che un linguaggio, lo SGML è un metalinguaggio. Esso prescrive precise regole sintattiche per definire un insieme di marcatori e di relazioni tra marcatori, ma non dice nulla per quanto riguarda la loro tipologia, quantità e nomenclatura. Questa astrazione costituisce il nucleo e la potenza dello SGML: in sostanza, SGML serve non già a marcare direttamente documenti, ma a costruire, rispettando standard comuni e rigorosi, specifici linguaggi di marcatura adatti per le varie esigenze particolari. Un linguaggio di marcatura che rispetti le specifiche SGML viene definito 'applicazione SGML' (SGML application). Una applicazione SGML, a sua volta, descrive la struttura logica di una classe di documenti, e non la loro forma fisica. Tale struttura astratta viene specificata dichiarando gli elementi che la costituiscono (ad esempio: capitolo, titolo, paragrafo, nota, citazione, ecc.) e le relazioni che tra questi intercorrono, relazioni che possono essere gerarchiche o ordinali. Infatti in SGML un documento viene visto come una struttura ad albero. Le dichiarazioni sono contenute in una tabella, denominata Document Type Definition (DTD), che costituisce una sorta di grammatica dei documenti che ad essa si riferiscono e rispetto alla quale debbono essere convalidati. Una volta definito un determinato linguaggio, esso può essere utilizzato per rappresentare infiniti documenti in base ad una sintassi rigorosa. A ciascun elemento corrisponde una coppia di marcatori. La sintassi standard prevede che i marcatori siano racchiusi tra i simboli di maggiore e minore. Ogni elemento viene identificato da un marcatore iniziale e uno finale (costruito premettendo una barra al nome del marcatore iniziale), a meno che non sia un elemento vuoto (nel qual caso è identificato solo dal marcatore iniziale). Un testo codificato dunque ha il seguente aspetto [86]: <text> <front><titlepage> <docauthor>Corrado Alvaro</docauthor> <doctitle><titlepart type="main">L'uomo nel labirinto</titlepart> <titlepart>in Il mare</titlepart></doctitle> <docimprint> <pubplace>Milano</pubplace><publisher>A. Mondadori</publisher><docdate>1932</docdate> </docimprint> </titlepage> </front> <PB n=145> <body><div0><head><REF TARGET="ALPES10" ID="MARE10">I</REF></head> <P>La primavera arrivò improvvisamente<REF TARGET="ALPES20" ID="MARE20">; era l'anno dopo la guerra, e pareva che non dovesse piú tornare.</REF>[...]</P> La codifica SGML, oltre alla sua potenza espressiva, offre una serie di vantaggi dal punto di vista del trattamento informatico dei documenti. In primo luogo, poiché un documento SGML è composto esclusivamente da una sequenza di caratteri in un dato code set (al limite si possono utilizzare i soli caratteri ASCII), esso è facilmente portabile su ogni tipo di computer e di sistema operativo. Inoltre un testo codificato in formato SGML può essere utilizzato per scopi differenti (stampa su carta, presentazione multimediale, analisi tramite software specifici, elaborazione con database, creazione di corpus linguistici automatici), anche in tempi diversi, senza dovere pagare i costi di dolorose conversioni tra formati spesso incompatibili. Ed ancora, la natura altamente strutturata di un documento SGML si presta allo sviluppo di applicazioni complesse. Possiamo citare ad esempio l'aggiornamento di database; la creazione di strumenti di information retrieval contestuali; la produzione e la manutenzione di pubblicazioni articolate come documentazione tecnica, manualistica, corsi interattivi per l'insegnamento a distanza. Per queste sue caratteristiche SGML ha trovato impiego soprattutto in contesti industriali e militari, dove la gestione efficiente e sicura dei documenti tecnici ha una funzione critica. Ma non mancano applicazioni SGML in ambito scientifico, anche nel dominio umanistico, dove una applicazione SGML denominata Text Encoding Iniziative è divenuta lo standard per la codifica e l'archiviazione dei testi su supporto digitale e per la creazione di biblioteche digitali [87]. Ma senza dubbio l'applicazione SGML che gode della diffusione maggiore, sebbene in gran parte inconsapevole, è lo HyperText Markup Language. Il presente: HyperText Markup Language (HTML)HyperText Markup Language (HTML) è il linguaggio utilizzato per dare forma ai milioni di documenti che popolano World Wide Web. Si tratta di un linguaggio orientato alla descrizione di documenti testuali con alcune estensioni per il trattamento di dati multimediali e soprattutto di collegamenti ipertestuali. A differenza di altre applicazioni SGML, lo sviluppo di HTML è stato assai proteico e, soprattutto in una certa fase, piuttosto disordinato. Nella sua prima versione ufficiale, il linguaggio era estremamente semplice, e non prevedeva la possibilità di rappresentare fenomeni testuali ed editoriali complessi. Di conseguenza le sue specifiche hanno subito diverse revisioni ed estensioni, che hanno dato origine a diverse versioni ufficiali, nonché ad una serie di estensioni introdotte dai vari produttori di browser Web. Questi raffinamenti successivi, accogliendo le sollecitazioni provenienti da una comunità di utenti sempre più vasta e variegata, hanno progressivamente allargato la capacità rappresentazionale del linguaggio, introducendo elementi dedicati al controllo strutturale e formale dei documenti. Le revisioni ufficiali vengono gestite da un gruppo di lavoro del World Wide Web Consortium. Nel dicembre del 1997 è stata rilasciata ufficialmente l'ultima versione del linguaggio, denominata HTML 4 (le specifiche in inglese sono disponibili all'indirizzo http://www.w3.org/MarkUp/, in italiano all'indirizzo: http://www.liberliber.it/progetti/html40/). HTML 4.0 aggiorna notevolmente la precedente versione 3.2, e accoglie molte novità che erano precedentemente parte dei vari dialetti proprietari (ad esempio la tecnologia dei frame, che permette di suddividere la finestra del browser in sottofinestre contenenti file diversi, e le tabelle). Ma le caratteristiche più rilevanti di questa versione sono senza dubbio l'attenzione dedicata alla internazionalizzazione e l'integrazione del linguaggio HTML con un sistema di fogli di stile - tema su cui torneremo a breve - in modo da distinguere la struttura astratta del documento dalla sua presentazione formale. Inoltre HTML 4.0 è formalmente basato su Unicode ed è in grado di rappresentare sistemi di scrittura che hanno direzioni di scrittura diverse da quella occidentale (ad esempio gli arabi scrivono da destra verso sinistra). Dunque, potenzialmente, esso permette la redazione e distribuzione di documenti redatti in ogni lingua e alfabeto e di documenti multilingua [88]. Queste innovazioni si aggiungono agli elementi di base di HTML, che permettono di strutturare un documento e di inserire riferimenti ipertestuali e oggetti multimediali in una pagina Web. Ad esempio è possibile indicare i diversi livelli dei titoli di un documento, lo stile dei caratteri (corsivo, grassetto...), i capoversi, la presenza di liste (numerate o no). Volendo realizzare un documento ipermediale, avremo a disposizione anche marcatori specifici per la definizione dei link ipertestuali e per l'inserimento di immagini. Naturalmente le immagini non sono parte integrante del file HTML, che in quanto tale è un semplice file di testo. I file grafici vengono inviati come oggetti autonomi dal server, e inseriti in una pagina Web solo durante l'operazione di visualizzazione effettuata dal browser. I formati di immagini digitali standard su Web sono il GIF e il JPEG. Si tratta di sistemi di codifica grafica in grado di comprimere notevolmente la dimensione del file, e pertanto particolarmente adatti ad un uso su rete. Attraverso i comandi HTML è possibile anche specificare alcune strutture interattive come moduli di immissione attraverso cui l'utente può inviare comandi e informazioni al server e attivare speciali procedure (ricerche su database, invio di posta elettronica e anche pagamenti attraverso carta di credito!); oppure disegnare tabelle. Un utente di Internet che desiderasse solo consultare e non produrre informazione in rete potrebbe fare a meno di approfondire sintassi e funzionamento di HTML. Attenzione, però: una delle caratteristiche fondamentali di Internet è proprio l'estrema facilità con la quale è possibile diventare protagonisti attivi dello scambio informativo. Se si vuole compiere questo salto decisivo, una conoscenza minima di HTML è necessaria. Non occorre avere timori reverenziali: HTML non è un linguaggio di programmazione, e imparare ad usare le sue istruzioni di base non è affatto difficile, non più di quanto lo sia imparare a usare e a interpretare le principali sigle e abbreviazioni usate dai correttori di bozze. Per questi motivi nell'appendice 'Mettere informazione in rete' torneremo su questo linguaggio, approfondendo alcuni elementi della sua sintassi. Il futuro: Extensible Markup Language (XML)L'evoluzione di Internet procede incessantemente. La crescente richiesta di nuove potenzialità e applicazioni trasforma la rete in un continuo work in progress, un laboratorio dove si sperimentano tecnologie e soluzioni innovative. Se da una parte questo processo produce sviluppi disordinati, spesso determinati da singole aziende che cercano di trarre il massimo profitto dal fenomeno Internet, dall'altra le organizzazioni indipendenti che gestiscono l'evoluzione della rete svolgono una continua attività di ricerca e di definizione di nuovi standard. Tra questi il più importante è senza dubbio lo Extensible Markup Language (XML), il nuovo linguaggio di markup definito recentemente dal W3 Consortium, che promette di cambiare sostanzialmente l'architettura del Web, e non solo. Lo sviluppo di XML rappresenta la risposta a due esigenze: in primo luogo il potenziamento delle funzionalità di gestione editoriale e grafica dei documenti su Web; in secondo luogo la certificazione e il controllo del contenuto dei siti. Sebbene la formalizzazione di HTML 4.0 abbia rappresentato una importante evoluzione, tuttavia essa non rappresenta una soluzione adeguata per ovviare ad alcuni importanti limiti di cui l'attuale architettura del Web soffre. La causa di tali limiti infatti risiede nel linguaggio HTML stesso. Possiamo suddividere i problemi determinati da HTML in due categorie:
La prima categoria è relativa al modo in cui vengono rappresentati i documenti. La rappresentazione e la codifica dei dati sono il fondamento di un sistema di gestione dell'informazione. Da questo punto vista HTML impone notevoli restrizioni: in primo luogo si tratta di un linguaggio di rappresentazione chiuso e non modificabile; l'autore di un documento può soltanto scegliere tra un insieme prefissato di elementi, anche se la struttura del suo documento richiederebbe di esplicitarne altri, o di qualificarli in modo diverso. In secondo luogo si tratta di un linguaggio scarsamente strutturato e con una sintassi poco potente, che non consente di rappresentare esplicitamente informazioni altamente organizzate come ad esempio una descrizione bibliografica, un record di database o un sonetto petrarchesco; conseguentemente non può essere usato come sistema di interscambio per informazioni complesse. A questo si aggiunge la confusione determinata dalla presenza di istruzioni che hanno una funzione stilistica piuttosto che strutturale. Un'ulteriore limitazione riguarda la definizione dei link ipertestuali. Si potrebbe dire che questo linguaggio di codifica usurpa il suo nome. Infatti è dotato di un solo tipo di collegamento ipertestuale, unidirezionale, che richiede che sia l'origine sia la destinazione siano esplicitate nei rispettivi documenti. La ricerca teorica e applicata sui sistemi ipertestuali, invece, ha individuato sin dagli anni settanta una complessa casistica di collegamenti ipertestuali, che corrispondono a diverse relazioni semantiche. Dai limiti rappresentazionali discendono quelli operativi, che riguardano il modo in cui autori e lettori interagiscono con il sistema. In primo luogo il controllo sull'aspetto di un documento, come abbiamo visto, è assai limitato e rigido. Una pagina Web deve essere progettata per uno schermo dotato di determinate caratteristiche, con il rischio di avere risultati impredicibili su altri dispositivi di visualizzazione o nella stampa su carta. Inoltre HTML non consente di generare dinamicamente 'viste' differenziate di un medesimo documento in base alle esigenze del lettore. Questo permetterebbe, ad esempio, di ottenere diverse versioni linguistiche a partire da un unico documento multilingua; oppure, in un'applicazione di insegnamento a distanza, di mostrare o nascondere porzioni di un documento a seconda del livello di apprendimento dell'utente. E ancora, la scarsa consistenza strutturale impedisce la generazione automatica e dinamica di indici e sommari. E per lo stesso motivo si riduce notevolmente l'efficienza della ricerca di informazioni su Web. I motori di ricerca, infatti, sono sostanzialmente sistemi di ricerca full-text, che non tengono conto della struttura del documento e restituiscono riferimenti solo a documenti interi. Per superare questi limiti è stato proposto un vero e proprio salto di paradigma: la generalizzazione del supporto su Web allo Standard Generalized Markup Language (SGML). L'idea di base è molto semplice: HTML è una particolare applicazione SGML, che risponde ad alcune esigenze; perché non modificare l'architettura del Web per consentire di usare anche altre applicazioni SGML? La possibilità di distribuire documenti elettronici in formato SGML garantirebbe ai fornitori di contenuti un notevole potere di controllo sulla qualità e sulla struttura delle informazioni pubblicate. Ogni editore elettronico potrebbe utilizzare il linguaggio di codifica che maggiormente risponde alle sue esigenze, a cui associare poi uno o più fogli di stile al fine di controllare la presentazione dei documenti pubblicati. L'attuazione di questa rivoluzione, tuttavia, non è indolore:
Per superare questi ostacoli il W3C ha deciso di sviluppare un sottoinsieme semplificato di SGML, pensato appositamente per la creazione di documenti su Web: Extensible Markup Language (XML). Il progetto XML ha avuto inizio alla fine del 1996, nell'ambito della SGML Activity del W3C, ma l'interesse che ha attirato sin dall'inizio (testimoniato da centinaia di articoli sulle maggiori riviste del settore) ha portato il W3C a creare un apposito gruppo di lavoro (XML Working Group), composto da oltre ottanta esperti mondiali delle tecnologie SGML, e una commissione (XML Editorial Review Board) deputata alla redazione delle specifiche. Dopo oltre un anno di lavoro, nel febbraio del 1998 le specifiche sono divenute una raccomandazione ufficiale, con il titolo Extensible Markup Language (XML) 1.0. Come di consueto tutti i materiali relativi al progetto, documenti ufficiali, informazioni e aggiornamenti, sono pubblicati sul sito del consorzio all'indirizzo http://www.w3.org/XML. XML, come detto, è un sottoinsieme di SGML semplificato e ottimizzato specificamente per applicazioni in ambiente World Wide Web. Come SGML, dunque, è un metalinguaggio, che permette di specificare, mediante la stesura di Document Type Definition, molteplici linguaggi di marcatura. Tuttavia rispetto al suo complesso progenitore è dotato di alcune particolarità tecniche che ne facilitano notevolmente l'implementazione, pur mantenendone gran parte dei vantaggi. Per conseguire questo risultato alcune delle caratteristiche più esoteriche di SGML, che ne accrescono la complessità computazionale, sono state eliminate, e sono state introdotte delle novità nella sintassi. La principale innovazione è l'introduzione del concetto formale di documento 'ben formato'. Un documento XML, di norma deve essere associato ad una DTD che ne specifichi la grammatica: se ne rispetta i vincoli esso è un documento 'valido'. Tuttavia, a differenza di SGML, XML ammette la distribuzione anche di documenti privi di DTD. Questi documenti, che sono appunto definiti 'ben formati', debbono sottostare ad alcuni vincoli ulteriori rispetto a quelli imposti alla sintassi di un documento SGML o XML valido (e dunque anche di un documento HTML): ad esempio è sempre obbligatorio inserire i marcatori di chiusura negli elementi non vuoti, gli elementi vuoti hanno una sintassi leggermente modificata, e sono vietati alcuni costrutti. Ciò riduce notevolmente la complessità di implementazione di un browser XML, e facilita l'apprendimento del linguaggio (le specifiche constano di venticinque pagine contro le cinquecento di SGML nello standard ISO). La semplificazione tuttavia non comporta incompatibilità: un documento XML valido è sempre un documento SGML valido (naturalmente non vale l'inverso). La trasformazione di un'applicazione o di un documento SGML in uno XML è (nella maggior parte dei casi) una procedura automatica. L'interesse che la comunità degli sviluppatori di applicazioni e servizi Web ha dimostrato verso XML è stato decisamente superiore alle stesse aspettative del W3C, che si attendeva un periodo di transizione assai lungo verso la nuova architettura. In breve tempo le applicazioni XML si sono diffuse in ogni settore: dalla ricerca umanistica (la TEI sta approntando una versione XML compatibile della sua DTD), a quella chimica (con il Chemical Markup Language, un linguaggio orientato alla descrizione di strutture molecolari); dal commercio elettronico, alla realizzazione di applicazioni distribuite su Internet; dall'editoria on-line alle transazioni finanziarie. Ma soprattutto sin dall'inizio è stata resa disponibile una grande quantità di software (in gran parte gratuito) in grado di elaborare documenti XML: analizzatori sintattici (parser), editor, browser, motori di ricerca. Gran parte dell'interesse è dovuto al fatto che XML, oltre che come formato di rappresentazione dei dati da presentare agli utenti, può essere utilizzato come formato di scambio dati tra programmi in applicazioni middleware, trovando applicazione nell'area del commercio elettronico e del lavoro collaborativo. Si colloca in questo settore una applicazione sviluppata dalla Microsoft, insieme a Marimba, e sottoposta al W3C, Open Software Description (OSD), che permette di descrivere oggetti software scambiati in rete. OSD potrebbe aprire la strada alla manutenzione software distribuita. Tra le tante applicazioni XML, una menzione particolare merita XHTML 1 (http://www.w3.org/TR/xhtml1). Come alcuni lettori avranno immaginato, si tratta della ridefinizione in XML di HTML 4.0 realizzata dal W3C. Rispetto alla versione standard, essa si distingue per l'aderenza ai vincoli di well-formedness di XML, ma al contempo può essere estesa senza problemi. Lo scopo di questa versione infatti è proprio quello di facilitare la transizione degli sviluppatori di risorse Web da HTML a XML con un passaggio intermedio rappresentato da XHTML. Un contributo non indifferente al successo di XML è dovuto all'interesse che questa tecnologia ha suscitato nelle maggiori protagoniste dell'arena Internet, Microsoft e Netscape. La Microsoft ha mostrato una notevole attenzione sin dall'inizio, partecipando con un suo esponente, Jean Pauli, alla definizione del nuovo linguaggio (si veda http://www.microsoft.com/XML), e basando su di esso il suo Channel Definition Format (CDF), il linguaggio utilizzato nel sistema push integrato in Explorer sin dalla versione 4. Tale versione di Explorer (rilasciata a fine 1998) è stata la prima ad integrare un supporto generico a XML, ed è in grado di interpretare e visualizzare (mediante fogli di stile) documenti XML.
Anche Netscape, che inizialmente non aveva dimostrato molto interesse verso XML, sembra essere ritornata sui suoi passi. La versione 5 del suo browser, attualmente in fase di beta nell'ambito del progetto Mozilla (http://www.mozilla.org), supporta in maniera piena e molto efficiente il nuovo standard, grazie a un ottimo parser scritto da James Clark (uno dei guru della comunità SGML). Gli standard correlati a XMLLa pubblicazione delle specifiche del linguaggio XML non ha esaurito l'attività di innovazione dell'architettura Web. Infatti, intorno al progetto XML sono stati sviluppati o sono in via di sviluppo una serie di standard ulteriori che coprono altri aspetti, non meno importanti, del suo funzionamento. In particolare, ci riferiamo al linguaggio per la specificazione di link ipertestuali in un documento XML, battezzato Extensible Linking Language; al sistema di specificazione dei metadati per le risorse Web Resource Description Format (basato su XML); al linguaggio per la creazione di fogli di stile Extensible Stylesheet Language. Nei prossimi paragrafi ci occuperemo dei primi due di questi standard, mentre per XSL rimandiamo al paragrafo dedicato ai fogli di stile. Extensible Linking LanguageCome XML estende la capacità di rappresentare documenti sul Web, Extensible Linking Language è stato progettato per incrementare la capacità di creare collegamenti ipertestuali. In un primo momento lo sviluppo di questo linguaggio è stato portato avanti in seno allo stesso gruppo di lavoro del W3C responsabile di XML; ma ben presto si è resa necessaria la formazione di un gruppo apposito, denominato 'XML Linking'. I lavori relativi alla definizione di XLL, nel momento in cui stiamo scrivendo, sono ancora allo stato di bozza di lavoro (working draft), ma le linee fondamentali sono state determinate, e introducono anche in questo settore importanti innovazioni. XLL si divide in due parti: Xlink, che si occupa della costruzione dei link, e Xpointer che si occupa della individuazione delle loro destinazioni. Per capire la distinzione funzionale tra i due prendiamo ad esempio un attuale link espresso nella notazione HTML: <a href=http://crilet.let.uniroma1.it>Vai alla Home page del CRILet<a> L'intero elemento A, inclusi attributi e contenuto, esprime formalmente un link; il tipo di elemento A preso indipendentemente dalla sua attualizzazione in un documento HTML è un elemento astratto di collegamento ipertestuale; il valore dell'attributo href (nella fattispecie una URL) è un puntatore che esprime la destinazione del link. Xlink (http://www.w3.org/TR/xlink) si occupa di definire gli elementi astratti di collegamento che possono essere utilizzati in un documento XML, le loro caratteristiche e la sintassi in base alla quale vanno esplicitati. Rispetto al semplice costrutto ipertestuale di HTML, Xlink costituisce un vero e proprio salto evolutivo. Esso prevede le seguenti tipologie di collegamenti ipertestuali:
Inoltre sono indicati dei sistemi per associare metadati ai link, in modo da qualificarli in base a tipologie (le quali permettono all'autore di predisporre diversi percorsi di esplorazione della rete ipertestuale, o al lettore di scegliere diversi percorsi di lettura) e a specificare il comportamento del browser all'atto dell'attraversamento del link. Xpointer (http://www.w3.org/TR/WD-xptr) invece specifica un vero e proprio linguaggio atto a individuare le destinazioni a cui un link può puntare. Anche in questo caso la capacità espressiva eccede di gran lunga l'elementare meccanismo di puntamento attualmente adottato sul Web. Infatti, basandosi sulla struttura ad albero di un documento XML, Xpointer permette di individuare specifiche porzioni al suo interno senza costringere ad inserire delle ancore esplicite. Non possiamo in questa sede soffermarci sui dettagli della sua sintassi, ma le possibilità aperte da questi meccanismi sono veramente notevoli. In primo luogo, sarà possibile specificare dei link che abbiano come destinazione punti o porzioni di un documento anche se non si ha il diretto controllo di quest'ultimo (e dunque la possibilità di inserirvi delle ancore). Ma, cosa ancora più notevole, grazie al costrutto dei link esterni di Xlink e ai puntatori di Xpointer sarà possibile specificare in un file separato (magari manipolabile da parte di più utenti) intere reti di collegamenti tra documenti. Insomma, grazie a questi nuovi linguaggi il Web assomiglierà molto di più all'utopico Xanadu concepito trent'anni fa da Ted Nelson. RDF e i metadati per le risorse on-lineSu Internet esistono moltissimi tipi di risorse informative, che possono essere considerate sotto molteplici punti di vista: paternità intellettuale, affidabilità, qualità, origine, tipologia dei contenuti. Con il termine metadati (dati sui dati) si indica appunto l'insieme di dati che descrivono una o più risorse informative sotto un certo rispetto in un modo tale che i computer possano utilizzare tali informazioni in modo automatico. I metadati hanno una funzione molto importante nell'individuazione, nel reperimento e nel trattamento delle informazioni. Un classico esempio è costituito dai riferimenti bibliografici di una pubblicazione (titolo, autore, editore, ecc.). Essi in primo luogo identificano una pubblicazione, ed infatti sono collocati sulla copertina e sul frontespizio di un libro; poi costituiscono il contenuto delle schede nei cataloghi bibliotecari, e dunque sono necessari al reperimento del libro nel 'sistema informativo' biblioteca. Questo esempio ci permette di valutare l'importanza di individuare un sistema semplice ed efficiente per associare metadati alle risorse informative on-line. Attualmente su Internet sono in uso diverse tecnologie che possono rientrare nella categoria dei metadati. Il W3C, ad esempio, nell'ambito dei sistemi di controllo parentale dell'accesso al Web ha sviluppato la già citata tecnologia Platform for Internet Contents (PICS), che permette di associare etichette descrittive ad un sito o a una singola pagina Web, al fine di assegnare valutazioni al loro contenuto ed eventualmente filtrarne l'accesso. Un altro tipo di metadati per i documenti elettronici riguarda la certificazione di autenticità e di aderenza all'originale di un documento distribuito sulla rete. A questo fine è stato sviluppato un sistema di identificazione delle risorse on-line basato su certificati digitali simili alle etichette PICS. Tali certificati permettono di individuare dei siti, dei documenti o dei software e di avere la garanzia che non abbiano subito manipolazioni e modifiche non autorizzate dall'autore. Anche le intestazioni HTTP e i mime type sono metadati associati a pagine web. Ci sono poi i vari formati di record catalografici come Unimarc. Ognuno di questi sistemi svolge un importante ruolo per il corretto ed efficiente funzionamento dello scambio di informazioni e risorse sulla rete. Per mettere ordine in questo ambito, il W3C ha istituito un intero settore dedicato a questo tema, con l'obiettivo di definire un sistema per la specificazione dei metadati su Internet che unifichi tutte le tecnologie adottate finora. Il risultato di questa attività è stato il Resource Description Framework (RDF). Si tratta di un metalinguaggio dichiarativo basato sulla sintassi XML che permette di rappresentare formalmente i metadati associati a una risorsa Web (dal singolo oggetto costituente una pagina a interi siti) sotto forma di proprietà e relazioni. L'architettura prevista da RDF si divide in due parti: la prima, denominata Resource Description Framework (RDF) Model and Syntax - le cui specifiche sono state rilasciate come raccomandazioni definitive nel febbraio 1999 e sono disponibili su http://www.w3.org/TR/REC-rdf-syntax - definisce la sintassi per descrivere i metadati associati ad una risorsa in una RDF Description. Quest'ultima è un documento XML, costituito da una serie di dichiarazioni che associano dei valori alle proprietà che vogliamo attribuire alla risorsa (ad esempio, la proprietà 'titolo', la proprietà 'autore' etc.). Tuttavia RDF non fa alcuna assunzione circa il vocabolario specifico delle proprietà che si possono attribuire. Anzi, essa è progettata esplicitamente affinché siano gli stessi utilizzatori a definire formalmente tale vocabolario, in modo tale da non imporre alcuna limitazione a priori al tipo di metadati esprimibili. A tale fine occorre definire un RDF Schema, la seconda parte dell'architettura RDF, in base alla sintassi formale definita nel documento Resource Description Framework (RDF) Schema Specification, allo stato di 'proposta di raccomandazione' dal marzo del 1999, http://www.w3.org/TR/PR-rdf-schema. Una volta che uno schema è stato definito formalmente e pubblicato, chiunque può adottarlo e utilizzarlo per costruire descrizioni RDF dei propri documenti. L'estrema flessibilità di questo meccanismo, e la sua adozione della sintassi XML, ne fanno un importante passo in avanti nell'area dei metadati per le risorse su Internet, e una possibile risposta a problemi come il controllo dell'accesso, la ricerca delle informazioni, la certificazione dei documenti e il controllo del copyright. Lo stesso W3C ha deciso che la prossima versione delle etichette PICS, la numero 2, si baserà sulla sintassi e sulla semantica di RDF. SGML su InternetSebbene XML rappresenti un enorme passo in avanti nella capacità di distribuire e gestire documenti strutturati su Web, in alcuni casi l'uso di SGML può ancora essere necessario o desiderabile. Alcune caratteristiche sintattiche eliminate in XML, infatti, rendono assai difficile la traduzione di applicazioni SGML molto complesse nel nuovo linguaggio, o impongono delle restrizioni non tollerabili. Soprattutto, esistono molte grandi banche dati documentali in SGML la cui conversione potrebbe richiedere costi alti e rischi di errore. In questi casi le soluzioni a disposizione degli sviluppatori sono due. La prima consiste nell'adozione di software SGML sul server in grado di generare automaticamente documenti HTML o XML da 'matrici' SGML, e di interoperare con un server HTTP. Si tratta di una soluzione molto efficiente ma anche costosa, praticabile solo per la pubblicazione on-line di grandi quantità di documenti. Tra i software di questo tipo ricordiamo Open Text, realizzato dalla omonima compagnia (http://www.opentext.com) e soprattutto Dyantext/Dynaweb, prodotto dalla Inso (http://www.inso.com). La seconda soluzione consiste nell'utilizzazione di appositi browser SGML, che possono eventualmente interagire con i tradizionali programmi di navigazione. Esistono due prodotti di questo tipo attualmente sul mercato: Panorama, distribuito dalla Interleaf [89] (http://www.interleaf.com), e Multidoc PRO, realizzato dalla finlandese Citec (http://www.citec.fi). Un terzo, in fase di sviluppo mentre scriviamo presso la stessa Citec, si chiama DocZilla, e si basa sul codice di Mozilla/Netscape 5, unito a un motore SGML/XML molto efficiente. Panorama è disponibile in due versioni, una commerciale e l'altra gratuita. La versione commerciale, a sua volta, consiste di due moduli: Panorama Publisher, un browser stand-alone dotato di strumenti per la creazione di fogli di stile e reti ipertestuali tra più documenti, e Panorama Viewer, un plug-in per Netscape ed Explorer che può solo visualizzare i documenti (di quest'ultimo viene distribuita una versione di prova, con alcune limitazioni funzionali, sul sito dell'Oxford Text Archive, all'indirizzo http://ota.ahds.ac.uk). La versione gratuita è invece basata sulla release 1 del browser ed è reperibile anch'essa dal sito Web dell'Oxforf Text Archive. Multidoc Pro, invece, è disponibile solo in versione commerciale, ma chi è interessato può scaricarne una versione funzionante per tre settimane presso il sito della Citec. I due programmi sono assai simili dal punto di vista tecnico e funzionale (si basano infatti sullo stesso motore SGML sottostante). Abbiamo scelto di soffermarci su Panorama, dunque, vista la disponibilità di una versione gratuita, sebbene un po' datata. Cominciamo con l'installazione. Per quanto riguarda il modulo Viewer il processo è molto semplice: basta attivare il programma di autoinstallazione, e seguire le poche istruzioni da esso indicate. La versione stand-alone (sia quella commerciale sia quella gratuita) richiede invece qualche cura. Il programma infatti può interagire come applicazione di supporto esterna con Netscape: in questo modo il documento SGML può contenere al suo interno dei link ad altri documenti remoti, esattamente come un normale file HTML. Tuttavia, per fare in modo che il browser Web avvii Panorama quando riceve un file SGML (e viceversa), occorre configurarlo appositamente. Con Netscape questo va fatto inserendo nella finestra di configurazione delle applicazioni un nuovo tipo di file con le seguenti specifiche:
Una volta completata l'installazione è possibile usare Panorama collegandosi a uno dei siti che distribuiscono documenti in formato SGML. L'interfaccia utente di Panorama si differenzia da quella di un consueto browser Web. La finestra principale è divisa in due aree: la parte sinistra può contenere uno o più indici dei contenuti, o una rappresentazione ad albero della struttura del documento (per passare da una visualizzazione all'altra si usano i comandi 'Contents' e 'SGML Tree' nel menu 'Navigator'); la parte destra mostra il documento stesso. L'indice, detto navigatore, viene generato automaticamente dal programma usando i marcatori che identificano i titoli di vario livello presenti nel documento. Le voci dell'indice sono attive e permettono di saltare direttamente al capitolo o paragrafo selezionato. L'albero invece mostra i rapporti tra i vari elementi che costituiscono il documento. Anche in questo caso se si seleziona con il mouse un certo elemento, viene evidenziato il contenuto corrispondente nella finestra del testo.
Il testo, a sua volta, può essere visualizzato in due modalità:
Per passare da una modalità all'altra occorre selezionare o deselezionare il comando 'Show Tags' del menu 'Options'. La figura 127 mostra l'aspetto di un file SGML con i marcatori visibili. È così possibile vedere che tipo di codifica è stata assegnata ad ogni segmento del testo, e usufruire delle informazioni strutturali veicolate dalla codifica. Le parti di testo sottolineate (e colorate in blu, sullo schermo) sono dei link attivi. La figura 128 invece mostra un documento formattato (per la precisione si tratta di una versione dei Canti Orfici di Dino Campana [90]) e il relativo sommario. In questo caso abbiamo usato Panorama Viewer come plug-in di Netscape. La finestra di Panorama, con la relativa barra dei pulsanti, è inserita in quella del browser; il menu dei comandi, di tipo pop-up, viene invece visualizzato mediante il tasto destro del mouse.
L'impaginazione e la formattazione del testo avvengono attraverso l'associazione di un foglio di stile al file del documento. I fogli di stile di Panorama usano una sintassi in formato proprietario (ma la traduzione 'in' e 'da' DSSSL o XSL non è difficile). Ogni tipo di documento (DTD in terminologia SGML) può avere più fogli di stile associati. Se Panorama riceve un file per il quale ha uno o più fogli di stile, allora lo applica, altrimenti ne richiede uno al server remoto. Grazie alla codifica SGML, Panorama è dotato di strumenti di ricerca interna al file notevolmente più avanzati rispetto ai normali browser HTML. È possibile cercare le occorrenze di un dato elemento, oppure le occorrenze di una certa stringa di testo contenute solo all'interno di determinati elementi. La sintassi per effettuare le ricerche prevede l'uso di operatori logici (AND, OR) e di operatori di relazione (IN, CONT). Ad esempio, se vogliamo cercare tutte le occorrenze di 'casa' solo nei paragrafi del corpo del testo, occorre prima attivare la finestra di dialogo con il comando 'Search' nel menu 'Edit', e poi digitare 'casa in <P>'. Chiudiamo questo paragarafo con alcuni cenni sul nuovo browser in fase di sviluppo presso la Citec. DocZilla, a differenza dei due prodotti visti sopra, è assai più orientato alla utilizzazione su Web, e inoltre ha anche il supporto per i file XML e per i fogli di stile CSS. Come detto esso si basa sul codice di Mozilla, il nomignolo scelto per indicare la prossima release di Netscape, di cui utilizza il motore di visualizzazione e l'interfaccia utente, come si può vedere dalla figura. A tali moduli associa un motore in grado di interpretare documenti in formato SGML e XML, nonché alcuni standard correlati a questi linguaggi come HyTime [91], RDF, TEI Extended Pointer [92], e il formato di grafica vettoriale CGM.
Dal suo predecessore MultiDoc eredita la possibilità di generare automaticamente molteplici sommari del documento visualizzato (come mostra la figura), e una serie di strumenti per gestire, visualizzare ed effettuare ricerche contestuali sui documenti. Insomma DocZilla sarà una sorta di 'superbrowser', in grado di sostituire in tutto e per tutto i normali browser per quanto riguarda l'accesso a documenti Web, ma con il valore aggiunto di poter accedere a documenti SGML dotati di complessi costrutti ipertestuali. Nel momento in cui scriviamo, questo software è ancora in versione 'alpha', e non è ancora stata fissata una data per il rilascio definitivo, né si conoscono i termini della sua distribuzione (la Citec ha affermato che forse una versione limitata del prodotto, funzionante come plug-in per Netscape 5, potrebbe essere distribuita gratuitamente, mentre l'intero programma sarà certamente a pagamento). La versione preliminare, comunque, può essere scaricata presso il sito http://www.doczilla.com, sul quale sono anche disponibili dettagliate informazioni sul prodotto. Questioni di stileSe XML e gli standard correlati costituiscono una soluzione ai problemi di rappresentazione strutturale dei dati e dei documenti, i fogli di stile offrono una risposta alla esigenza di un maggiore e più raffinato controllo sulla presentazione degli stessi. Per lungo tempo, nell'architettura di World Wide Web, le regole di formattazione e la resa grafica di un documento sono state codificate nei browser. In questo modo, il controllo sull'aspetto della pagina da parte dell'autore è molto limitato, e si basa su un insieme di marcatori HTML che possono determinare inconsistenze strutturali nel documento. L'introduzione dei fogli di stile risolve entrambi i problemi poiché:
Il concetto di foglio di stile nasce nell'ambito delle tecnologie di word processing e desktop publishing. L'idea è quella di separare il contenuto testuale di un documento elettronico dalle istruzioni che ne governano l'impaginazione, le caratteristiche grafiche e la formattazione. Per fare questo è necessario suddividere il testo in blocchi etichettati e associare poi a ogni blocco uno specifico stile, che determina il modo in cui quella particolare porzione del testo viene impaginata sul video o stampata su carta. Ad esempio, ad un titolo di capitolo può essere associato uno stile diverso da quello assegnato a un titolo di paragrafo o al corpo del testo (lo stile 'titolo di capitolo' potrebbe prevedere, poniamo, un carattere di maggiori dimensioni e in grassetto, la centratura, un salto di tre righe prima dell'inizio del blocco di testo successivo; a un blocco di testo citato potrebbe invece essere assegnato uno stile che prevede un corpo lievemente minore rispetto al testo normale, e dei margini maggiori a sinistra e a destra per poterlo 'centrare' nella pagina). Per chi usa un moderno programma di scrittura come Microsoft Word o Wordperfect questo meccanismo, almeno ad un livello superficiale, dovrebbe risultare familiare. I fogli di stile facilitano la formattazione dei documenti, permettono di uniformare lo stile di diversi testi dello stesso tipo, e semplificano la manutenzione degli archivi testuali. Infatti la modifica delle caratteristiche formali di uno o più documenti non richiede di effettuare un gran numero di modifiche locali. Se, ad esempio, una casa editrice decide di cambiare il corpo tipografico dei titoli di capitolo nelle sue pubblicazioni, sarà sufficiente modificare il foglio di stile per quella porzione di testo, e automaticamente tutti i testi erediteranno la nuova impostazione grafica. Il meccanismo dei fogli di stile si presta facilmente ad essere applicato ai documenti codificati mediante linguaggi di markup derivati da SGML e XML. Questo tipo di linguaggi, infatti, si basa proprio sulla esplicitazione degli elementi strutturali di un testo attraverso i marcatori. È sufficiente dunque definire una notazione che permetta di associare ad ogni marcatore uno stile. Naturalmente è poi necessario che il browser sia in grado di interpretare questa notazione, e di applicare le relative istruzioni di formattazione. Una notazione di questo tipo è un linguaggio per fogli di stile. Anche in questo settore il ruolo del W3C è stato determinante. Il Consortium, infatti, nell'ambito dei suoi gruppi di lavoro, ha elaborato entrambi i linguaggi attualmente utilizzati per definire fogli di stile sul Web. Il primo, sviluppato inizialmente per essere utilizzato con documenti HTML 4.0 e successivamente esteso a XML, si chiama Cascading Style Sheet. Ideato originariamente da Håkon Lie alla fine del 1994, ha avuto una prima formalizzazione nel dicembre 1996. Nel maggio del 1998 è stata rilasciata come raccomandazione la seconda versione, che estende notevolmente la prima versione in molte aree. In particolare ricordiamo: il trasferimento dinamico dei tipi di carattere sulla rete, in modo tale da garantire che l'aspetto di una pagina sia esattamente quello progettato anche se l'utente non ha i font richiesti sul suo sistema locale; la specificazione di appositi stili orientati ai software di conversione vocale e ai display per disabili; l'estensione delle capacità di controllo sul layout e sulla numerazione automatica di liste, titoli ecc., e la capacità di gestire diversi supporti di impaginazione per un medesimo documento (ad esempio la visualizzazione su schermo e la stampa su carta). Il testo definitivo delle specifiche, con il titolo Cascading Style Sheets, level 2 (CSS2), è disponibile sul sito Web del W3C, all'indirizzo http://www.w3.org/TR/REC-CSS2. Attualmente è in corso il lavoro per la definizione di una terza versione. La caratteristica fondamentale del CSS, dalla quale deriva il nome, è la possibilità di sovrapporre stili in 'cascata'; in questo modo l'autore può definire una parte degli stili in un foglio globale che si applica a tutte le pagine di un sito, e un'altra parte in modo locale per ogni pagina, o persino per singoli elementi HTML all'interno della pagina. Le regole per risolvere definizioni conflittuali, esplicitate nelle specifiche, fanno sì che lo stile definito per ultimo prenda il sopravvento su tutte le definizioni precedenti. In teoria, se il browser lo consente, anche il lettore può definire i suoi stili. La sintassi CSS è molto semplice, almeno al livello base. Essa si basa sui selettori, che identificano gli elementi a cui attribuire un dato stile, e sulle proprietà, che contengono gli attributi di stile veri e propri. I selettori possono essere i nomi degli elementi, o una serie di valori di attributi, e sono seguiti dalle proprietà, racchiuse tra parentesi graffe e separate da punto e virgola. Ad esempio, per indicare che i titoli di primo livello in un documento HTML 4.0 debbono usare un font 'Times' con dimensione di 15 punti tipografici in stile grassetto occorre scrivere quanto segue: H1{font-type: "Times"; font-size: 15pt; font-weight: bold} Per collegare un foglio di stile a un documento HTML 4.0 sono previsti tre metodi: si può definire il foglio di stile in un file esterno, e collegarlo al file che contiene il documento HTML (mediante l'elemento <LINK>); si possono inserire le direttive CSS direttamente all'interno del file HTML, usando l'istruzione speciale <STYLE>; e infine si possono associare stili ad ogni elemento usando l'attributo 'style'. Un meccanismo concettualmente simile, anche se basato su una sintassi diversa (per la precisione si utilizza una processing instruction) va utilizzato per associare un foglio di stile CSS a un documento XML [93]. Allo stato attuale il supporto ai fogli di stile CSS versione 1 è completo in tutti i browser di ultima generazione. Ancora incompleto, anche se in gran parte coperto, quello alla versione 2. La seconda tecnologia di fogli stile proposta dal W3C, è stata sviluppata nell'ambito delle attività correlate allo definizione di XML. Si tratta del linguaggio Extensible Stylesheet Language (XSL), le cui specifiche sono ancora allo stato di bozza. A differenza di CSS, XSL è un linguaggio piuttosto complesso, che eredita la semantica e il modello computazionale da un predecessore tanto illustre quanto complicato, il Document Style Semantics and Specification Language (DSSSL), [94] ma ne semplifica notevolmente la sintassi. Infatti gli stili vengono specificati direttamente in notazione XML piuttosto che in quella Scheme adottata da DSSSL [95]. XSL si divide in due sottoinsiemi: XSL Transformations (XSLT, http://www.w3.org/TR/WD-xslt) è costituito da un insieme di istruzioni che permettono di applicare processi di trasformazione ai documenti XML (ad esempio dato un elenco bibliografico strutturato, una procedura XSLT può generare diversi ordinamenti; o ancora, dato un gruppo di elementi strutturali, può generare un indice dei contenuti dinamico) e di traduzione da una codifica XML ad un'altra o da una codifica XML a una HTML. Extensible Stylesheet Language (http://www.w3.org/TR/WD-xsl) definisce un insieme di istruzioni di formattazione, che possono essere utilizzate per la formattazione vera e propria dei documenti e dei loro componenti. XSL permette di specificare procedure di formattazione condizionate dal contesto (ad esempio: il primo paragrafo dopo un titolo non ha rientro della prima linea di testo), ed ha una flessibilità elevatissima. In ogni caso, per le operazioni di elaborazione più complesse, XSL prevede esplicitamente il ricorso a script espressi in linguaggio JavaScript, o meglio nella sua versione standard ECMAScript (definita dalla European Computer Manufacturers Association). Poiché il lavoro di definizione di XSL in seno al W3C è ancora in corso (sebbene le specifiche siano molto avanzate) non esistono ancora implementazioni stabili. Microsoft Explorer 5 ha un motore XSL che per il momento implementa, in modo un po' personalizzato, solo parte del sottoinsieme di trasformazione (XSLT). In alternativa esistono alcuni programmi in grado di gestire fogli di stile XSL, ma si tratta di strumenti la cui utilizzazione è alla portata solo di sviluppatori dotati di una certa esperienza. Ulteriori informazioni su questo linguaggio sono disponibili alle pagine dedicate ad XSL del sito W3C, all'indirizzo http://www.w3.org/Style/XSL/. SMIL e le presentazione multimediali sincronizzateCome sappiamo il Web permette la distribuzione di informazioni multimediali tanto in modalità asincrona (come avviene con le pagine Web, i cui costituenti vengono prima inviati dal server al client e poi interpretati e visualizzati) quanto in modalità sincrona (come avviene con i protocolli di streaming). In alcuni casi, tuttavia, sarebbe desiderabile poter correlare lo svolgimento nel tempo di un flusso di informazioni con la presentazione di dati inviati in modalità asincrona o, in generale, sincronizzare sull'asse temporale la distribuzione di dati on-line. Un linguaggio recentemente sviluppato nell'ambito del W3C permette di realizzare proprio questa sincronizzazione: si tratta del Synchronized Multimedia Integration Language (SMIL). La prima versione di SMIL è stata rilasciata in forma definitiva nel giugno del 1998, e le specifiche sono disponibili sul sito del W3C all'indirizzo http://www.w3.org/TR/REC-smil. SMIL è una applicazione XML che consente di integrare una serie di oggetti multimediali in una presentazione sincronizzata. Le informazioni necessarie sono espresse formalmente in un documento XML che consente di descrivere i seguenti aspetti della presentazione:
A tale fine sono provvisti un insieme di elementi XML e di relativi attributi. Usando questa tecnologia è possibile realizzare una applicazione in cui durante la fruizione di un video streaming compaiano immagini e testi in precisi momenti: ad esempio, le immagini di una lezione diffusa mediante un sistema di streaming possono essere affiancate da pagine Web che illustrino i concetti spiegati, esattamente come in aula un docente può fare uso di una lavagna o di una presentazione video. Non a caso il campo di applicazione per eccellenza di questa tecnologia è quello della formazione a distanza, sia in ambito scolastico e universitario sia in ambito professionale. Ma ovviamente le applicazioni possono essere moltissime, dalla promozione di prodotti alle conferenze on-line, dal lavoro collaborativo all'entertainment. Esisitono diversi client che hanno implementato SMIL (alcuni dei quali scritti in Java), ma senza dubbio il più importante è Real Player G2, il più diffuso software per la riproduzione di streaming video e audio su Internet.
Come è avvenuto spesso, la Microsoft ha sviluppato una tecnologia che ha funzionalità simili, ma che si basa sulla sua tecnologia proprietaria ActiveX e sul suo sistema di streaming. Un piccolo vantaggio della architettura proprietaria Microsoft è dato dal fatto che è possibile realizzare una presentazione multimediale sincronizzata a partire da una presentazione Power Point, usando alcune semplici funzionalità inserite nell'ultima versione del programma. Note [81] Con portabilità intendiamo la possibilità di leggere i documenti Web con qualsiasi browser e su qualsiasi piattaforma. [82] L'espressione è stata usata da David Siegel, in un articolo pubblicato su Web, nella sua home page personale all'indirizzo http://www.dsiegel.com/balkanization/intro.html. [83] In realtà il concetto di multimedialità soffre di una grave indeterminazione che deriva dalla mancanza di una definizione rigorosa e concordemente accettata del concetto originale di 'medium'. Se infatti si intende per 'medium' di un determinato messaggio semplicemente il suo supporto fisico, molti strumenti normalmente considerati multimediali, come un CD-ROM, sono in realtà monomediali. La caratteristica essenziale della multimedialità, nell'uso più frequente del termine, sembra essere piuttosto l'integrazione fra tipi di linguaggi diversi per genesi, struttura, e (talvolta) per supporti tradizionalmente usati. Si tratta di una tematica complessa, che necessiterebbe di un approfondimento non possibile in questa sede. Per una discussione al riguardo, rimandiamo a F. Ciotti e G. Roncaglia, Rivoluzione digitale. Manuale di introduzione ai nuovi media, in corso di pubblicazione per i tipi Laterza. [84] Xanadu è il nome del misterioso palazzo della memoria letteraria immaginato dal poeta romantico inglese S.T. Coleridge nel suo bellissimo poema Kubla Kahn. Nelson fu molto impressionato da questa opera e decise di usare quel nome per battezzare il suo sistema, da lui stesso definito un 'posto magico di memoria letteraria'. [85] Il testo ufficiale dello standard ISO, commentato dallo stesso inventore del linguaggio, è nel fondamentale C.F. Goldfarb, The SGML Handbook, Oxford University Press, Oxford 1990. Manuali introduttivi di buon livello sono: E. van Herwijnen, Practical SGML, Kluwer Academic Publishers, Boston-Dordrecht-London 1994, II ed.; M. Bryan, SGML: An Author's Guide to the Standard Generalized Markup Language, Addison-Wesley, Wokingham-Reading-New York 1988. Moltissime informazioni, materiali e saggi su SGML sono naturalmente reperibili su Internet. Non è possibile qui dare un elenco dei siti dedicati a SGML, ma sicuramente il più completo è la SGML/XML Web Page di Robin Cover disponibile su WWW all'indirizzo http://www.oasis-open.org/cover/: una vera miniera che elenca praticamente tutto quello che c'è da sapere e che c'è da trovare in rete su SGML. [86] L'esempio è tratto da L'uomo nel labirinto di Corrado Alvaro (Mondadori, 1932). La codifica è basata sul DTD della TEI, ed è stata curata dal CRILet (http://crilet.let.uniroma1.it). [87] Ne abbiamo ampiamente parlato nel capitolo 'Biblioteche in rete'. Per quanto riguarda la TEI, oltre alla sezione 'Academic Applications' della già menzionata SGML/XML Web Page (http://www.oasis-open.org/cover), rimandiamo al sito del recentemente formato TEI Consortium (http://www.tei.org). [88] Naturalmente questa definizione formale non basta a garantire l'effettiva visibilità dei documenti. È necessario che il sistema operativo su cui opera il browser e il browser stesso siano in grado di gestire Unicode e che siano disponibili sulla macchina i caratteri grafici corrispondenti. [89] Questo prodotto è stato sviluppato originariamente dalla Softquad, una delle aziende leader nel settore SGML, che nel 1998 lo ha ceduto alla Interleaf. [90] Il testo è stato gentilmente concesso dal Centro Ricerche Informatica e Letteratura (CRILet) dell'Università "La Sapienza" di Roma, che sul suo sito Web (http://crilet.let.uniroma1.it) distribuisce alcune opere delle letteratura italiana codificate in formato SGML/TEI. [91] HyTime è uno standard ISO, espresso in notazione SGML, che permette di specificare costrutti ipertestuali e multimediali in modo dichiarativo e non procedurale, come avviene nelle applicazioni commerciali. Esso permette inoltre di sincronizzare la presentazione di diversi media su supporto digitale. [92] Si tratta di un complesso linguaggio, sviluppato dalla Text Encoding Initiative, per determinare la destinazione di un link ipertestuale che sfrutta la struttura gerarchica di un documento SGML. Il linguaggio XLL si basa essenzialmente su di esso. [93] Per chi fosse interessato, rimandiamo al documento Associating Style Sheets with XML documents Version 1.0 (http://www.w3.org/TR/xml-stylesheet/). [94] Document Style Semantics and Specification Language (DSSSL) è uno standard ISO ufficialmente rilasciato nel 1996 con la sigla ISO/IEC 10179:1996 (il testo completo dello standard è disponibile in vari formati sul sito ftp://ftp.ornl.gov/pub/sgml/WG8/DSSSL). Si tratta di un linguaggio molto potente, sviluppato esplicitamente per operare, in modo indipendente dalla piattaforma, su documenti strutturati, e in particolare su documenti in formato SGML. Dal punto di vista informatico si basa sulla sintassi del linguaggio di programmazione Scheme. Tanta potenza, naturalmente, si paga con altrettanta complessità. La implementazione completa di un'applicazione DSSSL comporta notevoli problemi computazionali. Per facilitare la sua applicazione in ambienti di rete, un gruppo di specialisti, tra cui Jon Bosak e lo scomparso Yuri Rubinsky, ne ha ricavato un sottoinsieme che è destinato in modo specifico alla impaginazione di documenti elettronici. Le specifiche di questo sottoinsieme, denominato DSSSL Online (DSSSL-o), sono state pubblicate da Bosak nell'agosto del 1996. Attualmente non esiste nessuna implementazione di questo linguaggio in applicazioni o in browser per World Wide Web, né sono stati annunciati sviluppi a breve termine in questa direzione. DSSSL ha trovato invece un buona accoglienza nel mondo SGML, dove i maggiori produttori di sistemi hanno deciso di implementare questa tecnologia per la formattazione di documenti su carta e su supporto digitale. Chi è interessato, e ha una buona dose di pazienza, può tuttavia gustare le potenzialità di questo linguaggio usando il motore DSSSL di James Clark, battezzato Jade (http://www.jclark.com/jade/), e uno dei fogli di stile pubblici, sui quali rimandiamo alla sezione dedicata a DSSSL della SGML/XML Web Page (http://www.oasis-open.org/cover/dsssl.html). [95] Scheme è un linguaggio di programmazione funzionale che deriva dal Lisp. Pur semplificando notevolmente la sintassi del Lisp, Scheme richiede delle abilità da programmatore. |
![]()