7. GESTIONE DELLE INFORMAZIONI
Il trattamento delle informazioni si è evoluto nel tempo seguendo lo sviluppo tecnologico, che ha messo a disposizione capacità di memorizzazione e potenza di calcolo sempre crescenti. La tabella seguente è una sintesi di quest’evoluzione.
|
ORGANIZZAZIONE |
FUNZIONALITA' |
PRODOTTI [1] |
SUPPORTI FISICI |
|
Files |
|
|
Schede perforate, Nastri magnetici |
|
Files
ad Indici |
Indici |
ISAM, VSAM |
Dischi |
|
Data
Base |
Indici, Descrizione dei dati, programmabilità |
DBASE, CLIPPER, FOXPRO |
Dischi |
|
Data
Base |
Contenitore con Dati, Indici, Descrizione dei dati,
programmabilità |
ACCESS |
Dischi |
|
Data Base
Server (DBMS: Data Base Management System) |
Contenitore con Dati, Indici, Descrizione dei dati,
programmabilità, esecuzione dei programmi da parte del Data Base |
ORACLE, DB2, SQL SERVER, INGRES, ... |
Dati distribuiti su Dischi in LAN e WAN |
Figura 7‑1
Contemporaneamente agli sviluppi tecnologici, si sono poste le basi teoriche del trattamento delle informazioni, culminate con il modello relazionale dei dati.
I dati, nella loro forma elementare, sono una coppia nome-attributo[2] ad esempio:
città, "TORINO",
bitmap, "il condor del logo"
NomeMonte, "MONTE BIANCO",Altezza,4808. [3]
In genere i dati sono aggregati insieme nel formare unità logiche, ad esempio l'insieme dei dati anagrafici, dei dati di una immagine, o le caratteristiche di un monte. Più informazioni elementari aggregate sono dette genericamente entità, talvolta record, schede o con terminologia relazionale righe (Row). Le entità a loro volta sono aggregate in insiemi detti files o archivi o Tabelle (Tables). I Data Base (DB), infine, sono l’insieme di più tabelle ed altre informazioni correlate. Un dato generico della riga è detto anche campo (field).
Il calcolatore permette di trattare le informazioni in modo molto più flessibile e veloce di quanto non lo si possa fare manualmente; l’insieme di Tabelle, informazioni correlate e strumenti informatici di gestione quali il mantenimento automatico degli indici, la sicurezza, lo svincolo dal problema degli spazi, la possibilità di programmazione, ecc. e’ detto DBMS (Data Base Management System).
Gli aggregati di informazioni possono avere anche strutture complesse, ad esempio la scheda di un impiegato può contenere delle sottoschede relative agli aumenti che ha avuto; se si prova a schematizzare queste strutture otteniamo dei grafi ad albero:
Matricola Cognome Nome ... Aumenti
───────────────────────────┬───────────────── │ importo / data ├─────────────────
│ importo / data
├─────────────────
:
│ importo /
data
├─────────────────
I Data Base che gestiscono strutture complesse sono detti gerarchici o reticolari. Poiché l’utilizzo dei DB gerarchici è complesso, sono stati soppiantati dai Data Base Relazionali che contengono una o più Tabelle in cui le colonne sono i campi, e le righe sono i record. La semplicità della struttura relazionale, d’altra parte, richiede una certa ridondanza rappresentata da un campo in comune fra le tabelle. La rappresentazione relazionale dei dati dell’esempio della Figura 7‑2 origina le tabelle anagrafica e la tabella aumenti; la colonna comune è la matricola.
|
Cognome |
Nome |
Matricola |
..... |
|
ROSSI |
CARMELA |
805567 |
..... |
|
BIANCHI |
BARTOLOMEO |
231784 |
..... |
|
VERDI |
PAOLA |
901526 |
..... |
Figura 7‑3
Tabella Anagrafica
|
Matricola |
Importo |
Data |
..... |
|
805567 |
30 |
31/08/1998 |
..... |
|
231784 |
20 |
30/04/1996 |
..... |
|
901526 |
40 |
30/04/1999 |
..... |
|
231784 |
30 |
30/04/2000 |
..... |
Figura 7‑4Tabella
Aumenti
La semplicità concettuale dei DB Relazionali, e nel seguito ci si riferirà solo ad essi, e’ evidente nelle operazioni che si possono effettuare su di essi con un linguaggio detto Structured Query Lanquage (SQL).
Prima di creare un programma o una applicazione[4], si deve fare una attività molto importante, cioè pensare a ciò che si vuole ottenere e quali informazioni servono. Questa attività è detta analisi; in particolare occorre determinare quali dati occorrono e di che tipo (alfanumerici, numeri, date, etc.), la loro dimensione e i valori accettabili (dominio).
|
Nome
dell'attributo |
Tipo |
Dimensione |
Dominio |
|
NOME |
Caratteri |
30 |
|
|
DATA DI NASCITA |
Data |
|
|
|
LUOGO DI NASCITA |
Caratteri |
25 |
|
|
SALARIO |
Numero |
|
> 20000 et < 100000 |
|
….. |
|
|
|
|
SESSO |
Caratteri |
1 |
M o F |
7.1. Le tabelle relazionali
7.1.1. Definizioni
Il modello dei database relazionali è stato introdotto da E.F.Codd, ricercatore presso la IBM[5], che ne ha descritto il modello matematico e specificato un linguaggio di interrogazione. Dal suo lavoro è stato implementato il DB2, il primo database relazionale. Qui di seguito alcune definizioni.
· Le entità, nel significato visto nel paragrafo precedente, sono individuate da un insieme finito di valori, detti attributi.
· L'insieme degli attributi è detto schema.
· L'entità è formato da un insieme finito di coppie <attributo, valore> detta tupla[6].
· L'insieme dei possibili valori degli attributi sono detti domini
· Relazione è l'insieme delle tuple che hanno lo stesso schema, normalmente si usa il sinonimo tabella (relazionale).
· Stato della relazione è l'insieme dei valori della Relazione.
Con riferimento alla figura Figura 7‑5, in cui la colonna nome è lo schema della Relazione Impiegati, una possibile entità potrebbe essere:
NOME JEAN VALJEAN
DATA DI NASCITA 31/10/1960
LUOGO DI NASCITA JEUVILLE
SALARIO 5000
...
SESSO M
Lo schema è: {NOME, DATA DI NASCITA, LUOGO DI NASCITA, SALARIO, ….., SESSO}, il dominio dell'attributo SESSO è {M, F}.
Si dice chiave primaria (primary key) un insieme minimo di attributi, se esiste, che hanno valori univoci, nell'esempio la chiave primaria potrebbe essere {NOME, DATA DI NASCITA}, in quanto nella Relazione ci possono essere due "ROUGE PIERRE" , con DATA DI NASCITA diverse.
Altre eventuali chiavi sono dette chiavi secondarie.
7.1.2. Operazioni
Fra Relazioni aventi lo stesso schema sono possibili le operazioni insiemistiche di Unione, Intersezione, e Differenza (v. par. 1-1).
Con Proiezione di una relazione R si intende la relazione R' ottenuta da un sottoinsieme S degli attributi di R.
L'operazione di Selezione; essa permette di "estrarre" delle entità da una Relazione tramite un predicato sugli attributi della relazione, ad esempio la Selezione "SALARIO > 5000" sulla Relazione Impiegati, produce una nuova relazione che contiene solamente entità in cui l'attributo SALARIO è maggiore di 5000.
Il Prodotto di due relazioni R1 e R2 (detto anche Prodotto Cartesiano) è una relazione il cui schema è l'unione degli schemi di R1 e R2 e che contiene l'unione di ogni tupla di R1 con ogni tupla di R2.
Una Selezione sul Prodotto di due relazioni R1 e R2, ottenuta tramite un predicato di uguaglianza fra gli attributi A1 di R1 e A2 di R2, (attributi aventi lo stesso dominio), è detta equi-congiunzione o equi-join, ed il risultato è una relazione contenente le tuple di R1 unite con le tuple di R2 per cui vale A1 = A2.
7.1.3. Il "linguaggio SQL"
SQL è diventato lo standard per accedere ai dati contenuti nei Data Base relazionali. Dal punto di vista tecnico SQL non è un vero e proprio linguaggio di programmazione, mancano infatti istruzioni che condizionano l'esecuzione. E' bensì uno strumento per interagire con un DB relazionale a livello logico, con alta astrazione dall'implementazione dei dati. Fra le capacità di SQL:
§ interrogazione di dati, il risultato è sempre una relazione,
§ inserzione, modifica e cancellazione di righe (tuple),
§ creazione, modifica e cancellazione di oggetti
La figura seguente mostra la struttura del comando SQL che opera su una o più relazioni:
|
SELECT |
Schema |
proiezione |
|
FROM |
Relazione(i) |
Introduce
la(le) relazione(i) |
|
GROUP BY |
Attributo(i) |
Riepilogo di
attributi |
|
WHERE |
condizioni |
Selezione o
join |
|
ORDER BY |
Attributo(i) |
|
Figura 7‑6
Solo le clausole SELECT e FROM sono necessarie; qui di seguito alcuni esempi.
SELECT * FROM anag |
* indica
tutto lo schema della relazione anag |
|
SELECT Cognome,
Indirizzo, Importo * 1.20, Prefisso + '/' + telefono FROM anag |
|
|
SELECT cognome, citta,
prefisso, telefono FROM anag WHERE provincia in ('TO','CN') |
|
|
SELECT cognome,
anag.provincia, Capoluogo FROM anag, tab_pro WHERE anag.provincia =
Tab_pro.provincia ORDER BY cognome |
Esempio di
join |
SELECT ufficio, MIN(salario), MAX(salario) FROM emp GROUP BY ufficio |
Figura 7‑7
7.2. Struttura dei DBMS
7.2.1. Struttura fisica
Un DBMS è formato da tre tipi di file:
· uno o più files di dati (Data Files): contengono i dati e tutte
le informazioni realtive alla loro elaborazione
· uno o più files di log (Redo Logfiles): contengono la storia
delle modifiche avvenute sul Data Base; sono necessari per eventuali
ricostruzioni del Data Base in caso di errori o perdite di dati.
· uno o più files di controllo
(Control Files): contengono
informazioni generali sul Data Base: nome, locazione dei files, ecc..
7.2.2. Struttura logica
In un DBMS in genere ci sono
uno o più Data Base (nella terminologia Oracle TableSpace), ed in essi
degli oggetti, in primo luogo Tabelle,
ma anche Viste, Indici, Programmi, contatori,
…
Le viste o Views sono tabelle “virtuali”, nel senso
che nel DBMS è memorizzato come ottenere i dati di una o più tabelle e o viste.
Come le tabelle, le viste possono essere interrogate ed i dati modificati e o
cancellati.
Le Viste sono usate per:
§
Aggiungere
un ulteriore livello di sicurezza, limitando l’accesso a predeterminati insiemi
di righe e colonne di una o più tabelle.
§
Nascondere
la complessità del reperimento dei dati sparsi fra più tabelle.
§
Presentare
le informazioni in una differente prospettiva rispetto a quella della tabella
reale.
Gli Indici sono la componente del DataBase
che permette l’accesso veloce alle informazioni.
I Programmi sono la
componente "personalizzata" del DBMS, sono funzioni, procedure o
elaborazioni che il DBMS effettua al verificarsi di eventi particolari (trigger).
Inoltre praticamente tutte le informazioni che servono al DBMS per la
sua gestione sono mantenute in forma tabellare, in un Data Base di sistema.
7.2.3. Processi
I DBMS non sono dei semplici
contenitori di informazioni, ma sono dei gestore di informazioni: in un
ambiente multiutente permette l'accesso contemporaneo ai dati garantendo alte
prestazioni, integrità dei dati e soluzioni efficaci per il recupero degli
errori dovuti a guasti fisici. Inoltre i DBMS eseguono compiti predeterminati
ed automatici, quali la traccia delle attività, la gestione degli indici e
degli spazi, l’esecuzione di istruzioni legate a certi eventi (trigger), ecc..
7.3. Utilizzo dei Data Base
7.3.1. Portabilità
I maggiori DBMS supportano
il linguaggio SQL, i tipi di dati sono per lo più compatibili, tuttavia la
portabilità di una applicazione, dati e programmi, non è indolore nè immediata.
La dichiarazione di conformità agli standard, se non è una conformità stretta,
è pura propaganda, in quanto la realizzazione è una conformità per eccesso. Qui
di seguito si accenna a cosa occorre tenere presente quando si sviluppa una
applicazione sotto l'aspetto della portabilità[7]:
§
Portabilità dei
dati: in genere la corrispondenza fra i tipi di dato di DBMS diversi è buona (a
parte la nomenclatura adottata).
§
Portabilità
dei comandi SQL: solo se aderenti allo standard SQL Entry level definto nel
documento ANSI X3.135-1992, "Database Language SQL." Eventuali
funzioni od operatori sui campi possono avere nomi o funzionamenti diversi (le
sole funzioni standard SQL sono: AVG, COUNT, MAX, MIN, e SUM utilizzate nella clausolla GROUP
BY). Altre
difformità si possono avere nel numero di campi trattati e nelle clausole
aggiunte ai comandi (ad esempio in ORACLE c'è la possibilità di estrarre dati gerachizzati, come una lista
di impiegati con i relativi responsabili).
§
Portabilità delle
strutture: con strutture si intendono viste, contatori, indici
§
Portabilità dei
programmi: è il punto meno "portabile", i linguaggi adottati dai DBMS
sono in genere proprietari.
La tabella sottostante esemplifica alcune
differenze fra i DBMS ORACLE è SQL Server
|
ORACLE |
SQL Server |
Note |
|
Funzioni |
Funzioni |
|
|
SYSDATE |
CURRENT_TIMESTAMP |
Data
del giorno |
|
SUBSTR |
SUBSTRING |
|
|
LPAD |
SPACE |
LPAD
genera stringhe di qualsiasi carattere |
|
CONCAT |
Operatore
+ |
|
|
USER |
CURRENT_USER |
|
|
Operatore
|| |
Operatore + |
|
|
Tipi di Dato |
Tipi di Dato |
|
|
VARCHAR |
CHAR, CHARACTER |
|
|
VARCHAR2 |
VARCHAR |
|
Tabella 7‑1
7.3.2. ODBC
ODBC è uno standard di accesso ai Data base. Fisicamente ODBC è una libreria di funzioni richiamabili da programma. Le funzioni ricevono in input dei comandi, sostanzialmente comandi SQL, ed in output forniscono il risultato dei comandi o la risposta sull'esito dell'operazione. Esistono ODBC per tutti i DBMS, per i Data Base tradizionali (Fox Pro, Dbase, ecc..) ed anche per tabelle EXCEL e files di testo.
7.3.3. Strumenti di analisi dei dati: OLAP
OLAP (Online Analytical
Processing), una categoria di strumenti software per analizzare i
dati contenuti nei database. La
caratteristica principale degli OLAP è di trattare non dati analitici ma dati
sintetici "multidimensionali" ad esempio il totale delle vendite
(dimensione 1), per anno (dimensione 2), per area geografica (dimensione 3), in
genere in forma sintetica, cioè sommarizzata. Si tratta quindi di strumenti che
combinano serie storiche di tabelle con funzioni statistiche, ad uso
principalmente manageriale o per il marketing.
7.4.
Dati multimediali
7.4.1. Tipi
7.4.1.1. Immagini
Le immagini si possono
rappresentare come griglie di punti o come descrizione di oggetti grafici.
La rappresentaziona di una immagini mediante la suddivisione in punti di essa, si ottiene assegnando ad ogni punto 1 o più bit, in funzione della risoluzione cromatica che si vuole ottenere. Con un solo bit le immagini sono bicromatiche. Normalmente si adotta una risoluzione cromatica a 24 bit, in cui 8 bit sono assegnati rispettivamente al rosso, verde e blu.
Con risoluzione (resolution),
si intende la precisione dell'immagine, questa si esprime in punti per pollice
o dpi (dots per inch); per i video si indica semplicemente qunte
righe e colonne di punti sono visibili, ad esempio 640x480.
Immagini di questo tipo sono
dette Bit-mapped graphics o raster graphics, per distinguerle da
altri metodi di rappresentare immagini, detti vector graphics o object-oriented
graphics. Le immagini vector graphics, sono rappresentate come
oggetti, le cui proprietà definiscono le caratteristiche dell'immagine. Il loro
campo di applicazione è tecnologico (disegno meccanico, architettonico, schemi elettrici, ecc…), ma anche artistico (animazione, paesaggi
virtuali, ecc…).
I grafici in forma vector
graphics sono indipendenti dal mezzo con cui sono riprodotti.
7.4.1.2. Suoni
Il suono è la decodifica che
il nostro cervello effettua dagli stimoli prodotti dalla compressione e
rarefazione dell'aria, generata da movimenti nello spazio (corde vocali,
oggetti che cadono, corde tese in movimento, ecc..). Il numero di volte in cui
compressione e rarefazione si alternano in un secondo è detta frequenza e
l'unità di misura è l'Hertz (Hz).
L'orecchio dell'uomo può
sentire suoni con frequenze da 20 Hertz a 20.000 Hertz[8].
Per riprodurre il suono occorre rilevarne l'intensità un certo numero di volte
nell'unità di tempo, che, per una buona qualità del suono significa una
frequenza di campionamento di 44100 Hz,
una intensità misurata con 2 byte (65536 levelli di segnale) e due
canali di ricezione. Tutto ciò comporta che per un secondo di suono sono
necessari 2·2·44100 = 176.000 bytes.
Tuttavia per la qualità
telefonica sono sufficenti 8 bit per l'intensità ed un campionamento a 6000 Hz,
per un totale di 6.000 bytes al secondo. Data la dimensione dei formati che
trattano i suoni, questi devono essere compressi, alcune compressioni sono con
perdita di informazione, non riscontrabile dall'ascoltatore.
I principali formati audio sono:
·
AU
formato audio di Sun Microsystems
·
SND formato audio utilizzato da Amiga, Macintosh
a NeXT
·
VOC
formato audio di Creative Labs (Sound Blaster card).
·
WAV
fomato audio Microsoft in ambiente Windows. Può memorizzare file fino a 4 Gb.
·
AIFF
formato audio utilizzato da Macintosh e sulle workstation Silicon Graphics.
·
MIDI
(Musical Instrument Digital Interface), è un protocollo di comunicazione
fra dispositivi musicali[9].
E' diventato uno standard adottato dalla industria elettronica della musica per
controllare apparati quali sintetizzatori e schede per il suono. Sono
disponibili molti programmi per comporre musica conformi allo standard MIDI;
fra le funzioni di cui dispongono c'è quella di generare lo spartito musicale
automaticamente.
7.4.1.3. Video
Le immagini video
necessitano di grandi quantità di spazio di memorizzazione, è pertanto cruciale
utilizzare tecniche di compressione e dispositivi dedicati alla loro
elaborazione. Ciò ha originato degli standard quali MPEG (Moving Picture Experts Group pronunciato m-peg).
MPEG è un'insieme di standard ISO relativi alla compressione digitale e ai
formati di file relativi. MPEG, in genere, produce immagini video di qualità
migliore dei formati quali Video for Windows[10]
Indeo[11]
e QuickTime[12].
MPEG effettua una
compressione elevata in quanto memorizza solamente i cambiamenti avvenuti fra
un'immagine e la successiva, inoltre la compressione è di tipo con perdita (lossy
compression), perdita generalmente non percettibile dall'occhio.
I principali standard MPEG
sono: MPEG-1, MPEG-2 e MPEG-4. In MPEG-1 la risoluzione del video è di 352x240
a 30 frames per secondo (fps); una qualità leggermente inferiore a quella dei
televisori. MPEG-2 offre risoluzioni di 720x480 e 1280x720 a 60 fps, con piena
qualità audio CD. MPEG-2 può comprimere 2 ore video in pochi gigabytes. MPEG-4
è uno standard basato su MPEG-1, MPEG-2 e la tecnologia QuickTime.
7.4.2. Le strutture per banche dati multimediali
7.4.2.1. Strutture fisiche
Il principale dispositivo di
memorizzazione dei dati multimediali è il disco magnetico, ma per opere
editoriali quali enciclopedie, giochi interattivi e didattica i dispositivi
sono DVD (Digital Versatile Disc or Digital Video Disc) ed i CD
ROM. I CD ROM possono contenere 70 minuti di musica o dati per 670MB; i DVD
contengono un minimo di 4.7GB, sufficenti per un filmato.
Sebbene sia possibile
gestire qualsiasi tipo di dato, e quindi anche quelli multimediali, con
strutture di memorizzazione elementari, cioè strutture accessibili da programma
tramite le istruzioni di base di lettura e scrittura, tuttavia è opportuno
servirsi di programmi per la gestione dei Data Base quali ORACLE, DB2, SQL
Server, ACCESS, ecc..., in quanto veri e propri sistemi di gestione integrale
dei dati.
7.4.2.2. Strutture logiche
La struttura di dati è
ovviamente l'informazione digitale multimediale, ma perchè essa sia funzionale
come minimo dovrebbero essere presenti:
·
Identificatore
univoco
·
Descrizione
·
Tipo
di informazione multimediale
·
Data
di catalogazione
L'informazione multimediale può essere memorizzata all'interno del DBMS come tipo di dati BLOB (Binary Large Object), o come puntamento al file multimediale. Il primo caso è consigliabile per file multimediali limitati. La tendenza è verso una estensione dei DBMS tale da inglobare ogni tipo di dato, anzi il DBMS stesso si propone come file system[13].
Tuttavia, ai fini della ricerca, può essere opportuno inserire altre informazioni, ad esempio per una fotografia: la data dello scatto, l'autore, ecc., le informazioni che non sono descrittive sono dette informazioni strutturate.
Le parole presenti nella descrizione, ed eventualmente le altre informazioni devono diventare indici di ricerca.
7.4.3. Classificazione
La classificazione è
l'operazione che immette nel Data Base le informazioni che renderanno possibile
le successive ricerche. Una classificazione corretta permette sia una rapida
convergenza verso le informazioni ricercate che la precisione dei risultati. A
tale scopo occorre stabilire un glossario delle parole da utilizzare
nelle descrizioni, il cui scopo é di evitare sia i sinonimi che l'utilizzo di
parole con significati diversi, tuttavia mentre i sinonimi sono trattabili
facilmente con apposite liste di sinonimi, il caso dei significati diversi
richiede una analisi del contesto.
7.4.4. Ricerca delle informazioni
La ricerca avviene mediante
il contenuto della descrizione e delle eventuali informazioni strutturate usate
per la catalogazione: parole e relazioni possono essere connesse da operatori
logici (and, or, not) o metalogici (near, adj).
Nell'imagine è simbolizzato l'effetto
dei sinonimi e del rumore in una ricerca con due raffinamenti: i circoli
racchiudono i documenti trovati.
![]()

![]()
![]()
![]() Documenti pertinenti
Documenti pertinenti

![]()
![]()
![]() Documenti non pertinenti
Documenti non pertinenti
![]()
Il cerchio rosa interno ai
circoli è un esempio di "rumore", i cerchi verdi rappresentano uno
scorretto utilizzo di sinonimi.
7.4.4.1. Operatori logici
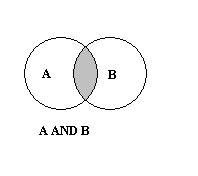
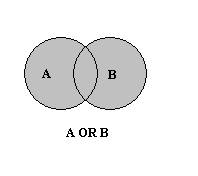
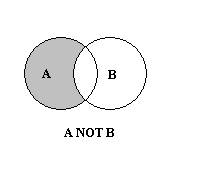
Si noti che in questo contesto l'operatore Not è un operatore binario, più precisamente è l'abbreviazione dell'espressione logica: A e non B.
7.4.4.2. Operatori metalogici
Near e Adj sono restrizioni dell'operatore And.
A Near B accetta il documento se la parola "A" è prossima alla parola "B", tipicamente nella stessa frase o paragrafo.
A Adj B accetta il documento se la parola "A" è la parola "B" sono adiacenti.
7.4.4.3. Operatori relazionali
La ricerca si avvale di relazioni sui campi strutturati; oltre alle relazioni di eguaglianza e di ordine (=, >, <,...), si possono avere relazioni di inclusione (IN), di range (FROM … TO), di somiglianza o pattern matching (LIKE).
Esempi:
LOCALITA = 'TORINO' PROVINCIA IN ('TO','CN') IMPORTO FROM 10000 TO 30000 COGNOME LIKE 'ROSS%'7.5.
Bibliografia
Graphics
contiene
le specifiche di vari formati di file grafici
http://www.dcs.ed.ac.uk/home/mxr/gfx/index-hi.html
SQL
Standards
ANSI
X3.135-1992,
"Database
Language SQL"
ISO/IEC
9075:1992,
"Database
Language SQL"
SQL-92
defines three levels of compliance, Entry, Intermediate, and Full