| Dividi e conquista | ||
| Merge |
Merge Sort |
|
| Esempio |
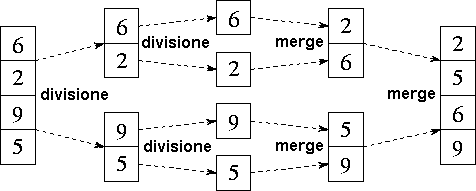
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
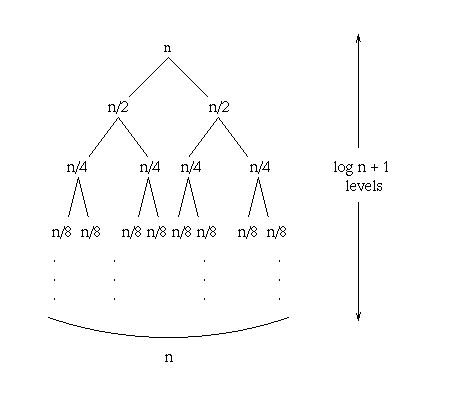
1 + 2 + 4 + ... + 2k = 2k+1 - 1 = 2^(log2n+1) - 1 = 2 x 2^(log2n) - 1 = 2n - 1 = O(n)
time(n) = 2*n*k = O(n*log2n)
Morale:
Costomerge = n + O(n*log2n) = O(n*log2n)In teoria è il "migliore" algoritmo di ordinamento (abbiamo assunto però nullo il costo di attivazione di una procedura).
Il problema dell'ordinamento di n elementi ha delimitazione inferiore W(n*log2n).
