![]() UNIVERSITA' DEGLI STUDI DI UDINE
UNIVERSITA' DEGLI STUDI DI UDINE
FACOLTA' DI
INGEGNERIA
Corso di
Laurea in Ingegneria delle Tecnologie Industriali ad
Indirizzo
Economico Organizzativo
Dipartimento:
Ingegneria Civile
Tesi di Laurea
Bench-marking
di algoritmi
della ricerca operativa in
Java, Delphi,
VisualBasic
|
Relatore: Prof. Livio Clemente Piccinini |
Laureando: Ciocia Gianluca |
![]()
ANNO ACCADEMICO 1999 - 2000
Indice
analitico
Prefazione......................................................................................... pag. 1
1.
Introduzione.................................................................................. pag. 2
2.Tipi di
dati...................................................................................... pag. 4
2.1 il concetto di tipo di dato................................................................................... pag. 5
2.2 Tipi di dati in Visual Basic................................................................. pag. 6
2.2.1 Matrici .......................................................................................................................................... pag. 8
2.2.2 Matrici dinamiche....................................................................................................................... pag. 10
2.2.3 Tipo Single, Double, Currency................................................................................................. pag. 11
2.2.4 Il tipo di dati Byte ....................................................................................................................... pag. 11
2.2.5 Il tipo di dati
String ................................................................................................................... pag. 12
2.2.6 Il tipo di dati
Boolean................................................................................................................ pag. 12
2.2.7 Il tipo di dati
Date....................................................................................................................... pag. 13
2.2.8 Il tipo di dati
Object.................................................................................................................... pag. 13
2.3 Tipi di dati Java................................................................................................. pag. 15
2.3.1 Tipo di dati
interi........................................................................................................................ pag. 15
2.3.2 Tipi di dati in
virgola mobile.................................................................................................... pag. 15
2.3.3 Tipo char....................................................................................................................................... Pag. 15
2.3.4 tipo Boolean................................................................................................................................. pag. 16
2.4 Tipi di dati Delphi.............................................................................................. pag. 17
2.5 Dichiarazione di variabili con tipi di dati.............................................................. Pag. 17
2.6 Conversione dei tipi di dati............................................................................... Pag. 18
3.Strutture
dati fondamentali............................................................... pag. 19
3.1 Puntatori........................................................................................................... pag. 21
3.2 Liste................................................................................................................. pag. 21
3.3 Pile e code........................................................................................................ pag. 22
3.4 Alberi............................................................................................................... pag. 22
3.5 Alberi Binari...................................................................................................... pag. 23
3.6 Insiemi.............................................................................................................. pag. 23
3.7 Dizionari........................................................................................................... pag. 23
3.8 Code con priorità.............................................................................................. pag. 23
3.9 Alberi Bilanciati di ricerca.................................................................................. pag. 24
3.10 Grafi............................................................................................................... pag. 24
4. La
Programmazione ad oggetti........................................................ pag. 25
4.1 Object-Oriented............................................................................................... pag. 26
4.2 Dichiarazioni..................................................................................................... pag. 30
4.3 Costruttori........................................................................................................ pag. 34
4.4 Identità, Uguaglianza, Equivalenza...................................................................... pag. 34
4.5 Composizione ed ereditarietà............................................................................. pag. 35
4.5.1 Composizione............................................................................................................................... pag. 35
4.5.2 Ereditarietà ................................................................................................................................. pag. 35
4.6 Gerarchia delle classi............................................................................... ....... pag. 36
5 Il
Software...................................................................................... pag. 37
6 Teoria
della compilazione................................................................ pag. 39
6.1 Premessa.......................................................................................................... pag. 39
6.2 Metologia Di Analisi.......................................................................................... pag. 40
6.3 Assegnazione di variabili.................................................................................... pag. 40
6.4 Organizzazione della memoria............................................................................ pag. 41
6.5 Processo di rilocazione...................................................................................... pag. 44
6.6 Calcolo aritmetico............................................................................................. pag. 44
6.7 If… then…....................................................................................................... pag. 45
6.8
if… then…else.................................................................................................. pag. 46
6.9
if… then … else annidati .................................................................................. pag. 46
6.10 Valutazione boleana minima e completa........................................................... pag. 47
6.11 istruzione while................................................................................................ pag. 47
6.12 La semantica del for........................................................................................ pag. 48
6.13 Arrays............................................................................................................ pag. 48
6.14 Procedure....................................................................................................... pag. 50
6.15 Functions........................................................................................................ pag. 50
6.16 Puntatori......................................................................................................... pag. 52
7 Ricerca
degli ordini di grandezza..................................................... pag. 53
7.1 Metodologia..................................................................................................... pag. 54
7.2 Assegnazione di variabili e loro incremento......................................................... pag. 54
7.3 Calcolo matematico........................................................................................... pag. 55
7.4 if…then…......................................................................................................... pag. 56
7.5 if..then..annidati................................................................................................. pag. 57
7.6 if..then..else ...................................................................................................... pag. 57
7.7 Ciclo For…next................................................................................................ pag. 58
7.8 Tabella riassuntiva ............................................................................................ pag. 58
8 Algoritmi........................................................................................ pag. 59
8.1 Ordinamenti ..................................................................................................... pag. 61
8.2 Quicksort.......................................................................................................... pag. 63
8.2.1 Analisi Quicksort ........................................................................................................................ pag. 65
8.2.2 Stime di
complessità ordinamenti ........................................................................................... pag. 66
8.3 Zaino................................................................................................................ pag. 67
8.4 Moltiplicazione tra matrici.................................................................................. pag. 68
8.5 Metodo di triangolarizzazione di una matrice quadrata....................................... pag. 69
8.6 Calcolo del determinante................................................................................... pag. 71
8.7 Numeri Casuali................................................................................................. pag. 72
9
Conclusioni e Risultati .................................................................... pag. 73
9.1 Aspetto economico .......................................................................................... pag. 73
9.2 Definizione dell’analisi.............................................................................. pag. 78
9.2.2 Approccio ..................................................................................................................................... pag. 78
9.2.3 Ipotesi iniziali ............................................................................................................................. pag. 78.
9.2.4 Tipologia dei
dati utilizzati ...................................................................................................... pag. 79
9.2.5 Tabella
riassuntiva degli algoritmi analizzati ..................................................................... pag. 79
9.2.6 Interfaccia
grafica minima ........................................................................................................ pag. 80
9.2.7 Piattaforma
Hardware ............................................................................................................... pag. 80
9.3 Metodologia di analisi e relativi problemi ........................................................... pag. 80
9.4 Risultati Pratici delle prove ....................................................... pag. 85
9.4.1 Bench-Mark
Quicksort su tipo di dato Intero .......................................................... ............ pag. 85
9.4.2 Bench-Mark
Quicksort su tipo di dato String ...................................................................... pag. 88
9.4.3 Bench-Mark
Quicksort su tipo di dato Double .................................................................... pag. 89
9.4.4 Bench-Mark di prodotto di matrici quadrate su tipi di
dato Double ............................. pag. 93
9.4.5 Bench-Mark della triangolare superiore su tipo di dato
Double .................................... pag. 94
9.4.6 Bench-Mark del
algoritmo Zaino su tipi di dati Double .................................................... pag. 96
9.5 Considerazioni
generali ............................................................................................................... pag. 98
9.6 VisualBasic Delphi e Java ................................................................................. pag. 98
10 I
Listati................................................................................. pag. 103
10.1 Visual Basic 6................................................................................................. pag. 104
10.2 Delphi 3.......................................................................................................... pag. 119
10.3 Java 1.2.......................................................................................................... pag. 140
11
Bibliografia............................................................................ pag.148
12
Ringraziamenti....................................................................... pag.149
PREFAZIONE
La programmazione degli elaboratori è divenuta una disciplina la cui conoscenza e fondamentale per il buon esito di molti progetti dell’ingegneria e la cui trattazione ben si presta all’approccio scientifico. Essa si è evoluta da mestiere a disciplina accademica. I primi rilevanti contributi a tale sviluppo sono da attribuire a E.W.Dijkstra e da C.A.R. Hoare. Il primo introdusse un nuovo modo di vedere la programmazione in qualità di scienza e di sfida intellettuale, il secondo dimostrò che i programmi si prestano ad una analisi esatta fondata su argomentazioni matematiche.
Entrambe le teorie annunciarono una grande rivoluzione in termini di calcolo automatico.
Gli approcci sistematico e scientifico alla programmazione sono particolarmente efficaci per programmi complessi e che coinvolgono numerosi e complicati insiemi di dati, da cui deriva che una metodologia di programmazione deve trattare tutti gli aspetti di strutturazione dei dati.
Un ulteriore contributo significativo di Hoare fu quello di dare origine ad una disorientante varietà di terminologie e concetti legata alle strutture dei dati. Egli chiarificò che non si possono prendere decisioni sulla struttura dei dati senza la conoscenza degli algoritmi che verranno applicati.
In altre parole strutture dati programmi e quindi linguaggi di programmazione sono entità inseparabilmente intrecciate.
La necessità del software venne concepita nella seconda metà degli anni ’60 .Una famosa conferenza NATO organizzata a Garmisch (Germania) nell’ottobre del ’68, coniò il termine “Ingegneria del Software” proprio a testimoniare l’esigenza che il software diventasse sempre più una disciplina ingegnieristica, cioè basata su solide basi teoriche e metodologie che permettano la progettazione, produzione e manutenzione delle applicazioni .
1
INTRODUZIONE
Per risolvere un problema, spesso sono disponibili molti algoritmi diversi e molti linguaggi di programmazione. Come scegliere il migliore algoritmo e quale piattaforma utilizzare per ottimizzare un problema, di difficile risposta sono le domande che ricorrono più spesso in fase di progettazione. Un criterio, generalmente adottato per quanto riguarda la bontà di un algoritmo, è la quantità di risorsa utilizzata per il calcolo, strettamente legata alla natura del compilatore, mentre attualmente la scelta del compilatore e quindi dei suoi costrutti è abbastanza soggettiva.
La risorsa di interesse dominante è il tempo anche se non meno importante è lo spazio necessario per immagazzinare e manipolare i dati.
In pratica non è possibile misurare il tempo di calcolo di un algoritmo col numero di secondi richiesto per eseguire su un elaboratore una procedura che lo descriva.
Infatti tale tempo dipende da:
- Linguaggio in cui la procedura è descritta;
- Qualità con cui viene automaticamente tradotta in sequenza di bit;
- Modo di trattare i primitivi dei dati;
- Velocità della machina elaboratrice.
Scopo di questa tesi è valutare in maniera quantitativa il contributo di velocità introdotta dalla tipologia della piattaforma utilizzata per lo sviluppo di una determinata procedura.
In sostanza un analisi pratica dei costrutti del linguaggio.
Questa indagine si orienta verso un analisi dettagliata della gestione dei tipi di dati dei tre linguaggi in esame Delphi, Visual Basic, Java.
La scelta di questi linguaggi è stata fatta in virtù di alcuni parametri che caratterizzano i tre linguaggi.
Le caratteristiche che io ritengo principali di Delphi sono: utilizzo dei costrutti tipici del pascal (Object-Pascal), la natura object-oriented, struttura dei form, dotazione di un compilatore estremamente veloce, ottimo supporto ai data-base, stretta integrazione con il supporto Windows e la sua tecnologia basata sui componenti VCL.
Le caratteristiche principali del Visual Basic sono: sviluppo semplice e veloce di applicativi Windows sia nel caso di professionisti che in quello di utenti meno esperti, tecnologia GUI spiccata ( Graphics Unit Interface), vasta reperibilità di oggetti già sviluppati, utilizzo di costrutti del Basic con un approccio più vicino al metodo di pensiero umano che della macchina, prerogativa di una grande diffusione.
Le caratteristiche di Java sono: grande similitudine con il C, struttura estremamente solida, natura fortemente tipizzata, programmazione object-oriented, ereditarietà e annidamento delle classi, gestione delle eccezioni, funzioni incorporate di sicurezza e protezione, supporto incorporato che facilita le operazioni di programmazione avanzata: web, data-base e multithreading; robusto modello orientato agli eventi, un efficace swing.
Alla luce di queste caratteristiche i metodi di trattazione dei dati e compilazione sono diversi, e in qualche modo intervengono sulla velocità di esecuzione di algoritmi matematici.
La gestione delle procedure e dei dati di alcuni algoritmi tipici di programmazione è diversa da compilatore a compilatore.
In seguito verranno esaminati alcuni punti che ritengo essenziali per il tipo di analisi.
Più precisamente sarà toccato il problema della compilazione sviluppato in Pascal per la sua natura fortemente didattica con lo scopo di descrivere in forma generale il processo di compilazione, una generalizzazione sulle strutture fondamentali dei dati, una trattazione matematica degli algoritmi di analisi necessaria a comprendere quali siano effettivamente le caratteristiche matematiche di ogni singolo algoritmo che possano mettere in crisi un compilatore, un breve riassunto dei tipi di dato dei rispettivi compilatori, la prova pratica di benchmarking e infine le conclusioni alla luce dei risultati ottenuti.
2
TIPI DI DATI
INTRODUZIONE
Quando si
risolve un problema è necessario scegliere un’astrazione della realtà, cioè
definire un insieme di dati per rappresentare la situazione reale. La
scelta deve essere guidata dal problema che si vuole risolvere.
Successivamente occorre scegliere una
rappresentazione dell’informazione. La scelta in questo caso deve essere
guidata dallo strumento dell’informazione.
In molti casi queste due scelte non sono indipendenti tra loro.
La scelta della rappresentazione dei dati è
spesso abbastanza difficile e non è univocamente determinata dagli strumenti a
disposizione. Essa deve essere coerente alle operazioni che dovranno essere
eseguite sui dati .
Facciamo l’ipotesi di voler determinare
la posizione di un oggetto nello spazio
R2 attraverso un elaboratore.
Una prima decisione porta alla scelta di una
coppia di numeri reali in coordinate cartesiane o polari.
La seconda decisione è quella di indicare i
numeri reali con una rappresentazione in virgola mobile, nella quale ogni
numero reale è composto da due interi la mantissa e l’esponente di una certa
base.
La terza decisione, fondata sulla conoscenza
di rappresentazione binaria, porta ad una rappresentazione binaria posizionale
degli interi.
Come ultima decisione si tratterebbe di
trovare una rappresentazione binaria degli interi in termini di flusso magnetico per la
scrittura dei dati in unità di memoria sequenziali.
La prima decisione è l’unica a prendere in considerazione il problema reale
mentre le successive dipendono, in forma progressivamente crescente, dagli
strumenti e dalle tecniche.
Quindi la prima decisione è definita ad alto livello ed è di competenza del
programmatore mentre le decisioni successive, a basso livello, sono di competenza dei progettisti di elaboratori.
Un linguaggio di programmazione ad alto livello rappresenta un elaboratore astratto in grado di comprendere i termini del linguaggio che contengono un certo livello di astrazione degli oggetti utilizzati dalla macchina reale.
Usare un linguaggio di programmazione che
offra la scelta conveniente di astrazioni, comuni alla maggior parte dei
problemi di elaborazione dati , è importante principalmente in termini di
affidabilità dei programmi che ne risultano e in ultima analisi di velocità.
Inoltre è
più facile progettare un programma ragionando in termini di numeri, sequenze
ripetizioni piuttosto che su Bit parole di Byte e salti.
Più le
astrazioni sono vicine ad un dato elaboratore, più facile è per l’ingegnere o
l’implementatore del linguaggio, prendere una decisione sulla rappresentazione.
Questo
fatto pone limiti ben definiti al livello di astrazioni di un PC reale.
Per esempio non sarebbe intelligente
includere oggetti geometrici tra i dati fondamentali, perché la loro
rappresentazione, a causa della loro complessità, dipenderebbe fortemente dalle
operazioni da eseguire su tali oggetti.
Il
desiderio è di poter usare la notazione matematica di numeri, insiemi e
sequenze piuttosto che stringhe di bit.
2.1 IL CONCETTO
DI TIPO DI DATO
I termini
“dato” e “tipo di dato” benché apparentemente possano sembrare simili in realtà
hanno un significato diverso:
1. In un
linguaggio di programmazione, il dato è un valore che una variabile può
assumere;
2. Un tipo
di dato è un modello matematico consistente in una collezione di valori sui
quali sono ammesse solo certe operazioni.
Per esempio
il numero 6 è un dato, che può essere assegnato ad una variabile di tipo
integer. La collezione dei numeri interi, con le usuali operazioni aritmetiche
definite, è un tipo di dato.
I linguaggi di programmazione Delphi, VisualBasic, Java forniscono alcuni tipi di dati primitivi a solo quelli comuni verranno fatte le prove di Bench-mark..
2.2 TIPI DI DATI IN VISUALBASIC
Al contrario di Java i linguaggi VisualBasic e
Delphi possiedono, tra i tipi di dati primitivi, il tipo Variant in cui è
possibile memorizzare tutti i tipi di dati definiti dal sistema. Quando si
assegnano questi tipi di dati ad una variabile Variant, non è pertanto
necessario convertirli in quanto la conversione viene eseguita automaticamente.
Nelle operazioni con variabili Variant il tipo di dati ad esse associato non è un fattore importante. È necessario tuttavia tenere presenti alcuni possibili problemi da evitare.
Quando si eseguono operazioni o funzioni aritmetiche con variabili Variant, è necessario che la variabile includa un valore numerico. Le variabili Variant possono includere i tre valori speciali Empty, Null ed Error.
Le
variabili Variant includono sempre una rappresentazione interna dei valori in
esse memorizzati. Tale rappresentazione determina la modalità di gestione dei
valori nei in confronti e in altre operazioni, rendendo spesso il processo di
gestione meno performante. Quando si assegna un valore a una variabile Variant,
viene utilizzata la rappresentazione più compatta possibile per la corretta
registrazione del valore. Le variabili Variant non devono essere considerate
variabili senza tipo di dati, ma variabili il cui tipo può variare. Una
variabile di tipo Variant occupa sempre 16 byte, indipendentemente dagli
elementi in essa memorizzati. Gli oggetti, le stringhe e le matrici non vengono
fisicamente memorizzati in una variabile di questo tipo. In questi casi,
vengono utilizzati 4 byte della variabile Variant per memorizzare un
riferimento a un oggetto oppure un puntatore alla stringa o matrice. I dati
effettivi vengono memorizzati altrove.
Nella
maggior parte dei casi non è necessario conoscere la rappresentazione interna
di una determinata variabile, in quanto le operazioni di conversione vengono
gestite in modo automatico. Se tuttavia si conosce il valore specifico, è
possibile utilizzare la funzione VarType.
La
rappresentazione interna di variabili Variant in cui sono memorizzati, ad
esempio, valori decimali è sempre di tipo Double. Se l'applicazione non
richiede il livello di precisione fornito dai valori di tipo Double, a cui è
associata una minor velocità, è possibile rendere più veloce l'esecuzione di
calcoli convertendo i valori nel tipo Single o Currency.
Il codice
con cui vengono prese decisioni in base al valore restituito dalla funzione
VarType dovrebbe consentire di gestire in modo efficiente i valori restituiti
che attualmente non sono definiti.
Quando si memorizzano valori numerici interi
in variabili Variant, viene utilizzata la rappresentazione più compatta
possibile. Se, ad esempio, si assegna un numero basso non decimale, per la
rappresentazione del valore di Variant viene utilizzato il tipo Integer. Se
invece si assegna un numero alto, viene utilizzato un valore Long oppure, nel
caso di numeri molto alti con un
componente frazionario, o un valore Double.
In alcuni casi può
risultare necessario utilizzare una rappresentazione specifica di un numero, ad
esempio, un valore numerico di tipo Currency per una variabile Variant in modo
da evitare errori di arrotondamento in calcoli successivi.
Se si esegue un'operazione o una funzione
matematica in una variabile Variant che non include alcun valore numerico o un
valore che possa essere interpretato come numero, viene generato un errore. Non
è possibile, ad esempio, eseguire operazioni aritmetiche sul valore U2 anche se
include un numero, in quanto l'intero valore non è un numero valido. Di
conseguenza, è spesso necessario stabilire se una variabile Variant include un
valore utilizzabile come numero.
Nella
conversione di una rappresentazione non numerica, quale una stringa contenente
un numero, in un valore numerico, il separatore delle migliaia, il separatore
decimale e il simbolo di valuta vengono determinati in base alle impostazioni
internazionali del Pannello di controllo di Windows.
Se si assegna un variabile Variant contenente
un valore numerico a una variabile stringa o ad una proprietà, la
rappresentazione del numero viene convertita automaticamente in stringa. Se si
desidera convertire in modo esplicito un valore numerico in una stringa, è necessario
utilizzare l’apposita funzione. È
inoltre possibile utilizzare la funzione Format per convertire un valore
numerico in una stringa che include elementi di formattazione quali il simbolo
di valuta, il separatore delle migliaia e il separatore decimale. La funzione
Format utilizza automaticamente i simboli adeguati in base alle impostazioni
internazionali del Pannello di controllo di Windows.
2.2.1 Matrici
Il concetto
di matrice è comune a diversi linguaggi di programmazione. Le matrici consentono
di fare riferimento a una serie di variabili in base a uno stesso nome e di
utilizzare un numero, ovvero un indice, per contraddistinguerle. In molti casi,
ciò consente di scrivere un codice più semplice e più compatto, in quanto è
possibile impostare cicli per la gestione efficiente di qualsiasi numero di
casi utilizzando il numero di indice. Alle matrici è associato un limite
superiore e un limite inferiore entro i quali sono inclusi i vari elementi in
modo contiguo. In Visual Basic viene assegnato spazio a ciascun numero di
indice, è consigliabile evitare dichiarazioni di matrici con dimensioni
maggiori di quanto non sia strettamente necessario.
A tutti gli
elementi di una matrice è assegnato lo stesso tipo di dati. Nel caso del tipo
Variant, i singoli elementi possono includere dati di tipo diverso, quali
oggetti, stringhe, numeri e così via.
Nella dichiarazione di matrici è possibile
specificare uno dei tipi di dati principali, compresi i dati definiti
dall'utente.
In Visual
Basic sono disponibili due tipi di matrice, ovvero le matrici a dimensione fissa le cui dimensioni rimangono sempre
invariate, e le matrici dinamiche le
cui dimensioni possono variare in fase di esecuzione.
Nella
dichiarazione di una matrice, il nome della matrice deve essere seguito dal
limite superiore racchiuso tra parentesi. Tale limite non deve essere maggiore
dell'intervallo valido per il tipo di dati Long (da -2.147.483.648 a
2.147.483.647). Le seguenti dichiarazioni di matrice, ad esempio, possono
essere incluse nella sezione Dichiarazioni di un modulo:
Dim
Counters(14) as Integer
VisualBasic ' 15 elementi.
Var
: a=Array
[0…14] of Integer Delphi ' 15 elementi.
La prima
dichiarazione consente di creare una matrice contenente 15 elementi, con numeri
di indice compresi tra 0 e 14. La seconda dichiarazione consente invece di
creare una matrice contenente 14 elementi in Delphi. Il limite inferiore
predefinito è 0.
Il limite
inferiore deve essere impostato in modo esplicito con tipo di dati Long
specificando la parola chiave To; in Delphi da due punti orizzontali come da
esempio:
Dim
Counters(1 To 15) As Integer
Visual basic
Array [1..15] of integer; Delphi
Nelle
dichiarazioni precedenti, i numeri di indice della proprietà Counters
sono compresi tra 1 e 15.
In VisualBasic è possibile creare una matrice Variant e
popolarla con matrici a cui sono assegnati altri tipi di dati
Può essere necessario tenere traccia delle informazioni incluse in una matrice. Per tenere traccia di ciascun pixel dello schermo del computer, ad esempio, è necessario fare riferimento alle relative coordinate X e Y. A tale scopo è possibile utilizzare una matrice a più dimensioni.
In Visual
Basic e Delphi è possibile dichiarare matrici a più dimensioni. La seguente
istruzione, ad esempio, dichiara una matrice bidimensionale (10 x 10) in una
routine:
Static
MatrixA(9, 9) As Double; VisualBasic
Var Matrix=array
[0..9,0..9] of Double ; Delphi
È possibile
dichiarare una delle due dimensioni o entrambe con limiti inferiori espliciti:
Static
MatrixA(1 To 10, 1 To 10) As Double
Var MatrixA=array
[0..9,0..9] of Double ; Delphi
È quindi
possibile estendere la matrice a più di due dimensioni:
Dim MatrixA (3, 1 To 10, 1 To 15)
Questa
dichiarazione crea una matrice a tre dimensioni: 4 per 10 per 15. Il numero
totale di elementi corrisponde al prodotto delle dimensioni, in questo caso
600.
Quando si aggiungono dimensioni a una
matrice, lo spazio di memorizzazione totale necessario aumenta in modo
considerevole. È pertanto consigliabile utilizzare le matrici a più dimensioni
con cautela, soprattutto nel caso di matrici Variant, che hanno dimensioni
maggiori rispetto agli altri tipi di dati.
Per
un'elaborazione efficiente di matrici a più dimensioni è possibile utilizzare
cicli For nidificati. Le seguenti istruzioni, ad esempio, inizializzano tutti
gli elementi di MatrixA su un
valore basato sulla posizione di ciascun elemento nella matrice:
VISUALBASIC
Dim I As
Integer, J As Integer
Static
MatrixA(1 To 10, 1 To 10) As Double
For I = 1 To 10
For
J = 1 To 10
MatrixA(I, J) = I * 10 + J
Next
J
Next I
DELPHI
MatrixA=
array [1..10,1..10] of double;
Var
I,J :integer
Begin
For
i=0 to 10 do
For j=1 to 10 do
MatrixA[I, J]) = I * 10 + J
2.2.2 Matrici dinamiche
Le matrici
dinamiche possono essere ridimensionate in qualsiasi momento. Questo tipo di
matrice, che rappresenta una delle funzioni più flessibili per Visual Basic,
consente di gestire la memoria in modo efficiente. È possibile, ad esempio,
utilizzare una matrice di grandi dimensioni per un periodo di tempo limitato e
quindi rendere disponibile la memoria quando non è più necessario utilizzare la
matrice.
In alternativa è possibile dichiarare la matrice specificando le dimensioni massime e ignorare quindi gli elementi non necessari. Se tuttavia si applica questo metodo in modo eccessivo, la memoria del sistema operativo potrebbe esaurirsi.
Per creare
una matrice dinamica :
1.
dichiarare la matrice con un'istruzione Public se si
desidera creare una matrice pubblica, con l'istruzione Dim a livello di modulo
se si desidera creare una matrice a livello di modulo oppure con l'istruzione
Static o Dim in una routine se si desidera creare una matrice locale. Per
dichiarare la matrice come dinamica, è necessario assegnarle un elenco di
dimensioni vuoto.
2.
Assegnare il numero di elementi desiderato con
un'istruzione ReDim.
È inoltre
possibile assegnare stringhe di lunghezza variabile a una matrice di byte. Si
noti che il numero di byte di cui è composta una stringa varia in base alla
piattaforma. Nelle piattaforme Unicode viene utilizzato un numero di byte
doppio rispetto a quello delle piattaforme
standard Ansi per rappresentare le stringhe.
In
Visual Basic sono disponibili vari tipi di dati numerici, ovvero Integer, Long
(intero lungo), Single (virgola mobile a precisione semplice), Double (virgola
mobile a precisione doppia) e Currency. Questi tipi di dati occupano in genere
meno spazio di memoria rispetto al tipo di dati Variant.
Quando si è certi che in una variabile
verranno sempre memorizzati numeri interi, quale il numero 12, anziché numeri
frazionari, quale 3,57, è consigliabile dichiararla con il tipo di dati Integer
o Long. Le operazioni con valori interi vengono infatti eseguite più
rapidamente. Questi tipi di dati utilizzano inoltre una minor quantità di
memoria sono più veloci rispetto ad
altri tipi e risultano particolarmente utili come variabili contatore in cicli
for next.
2.2.3 Tipo
Di Dati Single, Double e Currency.
Le
variabili che includono valori decimali devono essere dichiarate con tipo
Single, Double o Currency. Il tipo di dati Currency supporta fino a 19 cifre
significative a destra del separatore decimale e fino a quindici cifre a
sinistra. Si tratta di un tipo di dati a virgola fissa adatto a calcoli di
valuta. Con numeri in virgola mobile (tipi di dati Single e Double) sono
disponibili intervalli di valori più ampi rispetto al tipo Currency. Tali
valori sono tuttavia soggetti a piccoli errori di arrotondamento.
È
possibile esprimere i valori in virgola mobile come mmmEeee o mmmDeee,
dove mmm è la mantissa ed eee è l'esponente, ovvero una potenza di
dieci. Il valore positivo maggiore con tipo di dati Single è 3,402823E+38. Il
valore positivo più alto con tipo di dati Double è 1,79769313486232D+308,
ovvero circa 1,8 per 10 elevato alla 308. Inserendo il separatore D tra la mantissa e l'esponente in una
stringa numerica, il valore viene gestito come tipo di dati Double, mentre
inserendo il separatore E il valore
viene gestito come tipo di dati Single.
2.2.4 Il tipo di
dati Byte
Le
variabili che includono dati binari devono essere dichiarate come matrice con
tipo di dati Byte. L'utilizzo di variabili Byte per la memorizzazione di dati
binari consente di conservare i dati durante la conversione del formato. Nella
conversione di variabili String tra il formato ANSI e il formato Unicode, i
dati binari vengono danneggiati. Questo tipo di conversione viene eseguita
automaticamente durante le seguenti operazioni:
·
Lettura da file
·
Scrittura su file
·
Chiamata a DLL
·
Chiamata di metodi e proprietà per gli
oggetti
Con
il tipo di dati Byte sono validi tutti gli operatori utilizzati con valori
interi, a eccezione del meno uno. Il tipo Byte, essendo senza segno e
rappresentando valori compresi tra 0 e 255, non può rappresentare valori
negativi. Nel caso del meno -1, ai valori Byte viene prima assegnato il tipo
Integer con segno.
A
tutte le variabili numeriche è possibile assegnare un'altra variabile numerica
o una variabile di tipo Variant. Prima dell'assegnazione di un valore in
virgola mobile a un intero, la parte frazionaria viene arrotondata anziché
troncata,contrariamente a quanto succede
in Delphi e Java.
2.2.5 Il tipo di
dati String
Le
variabili in cui vengono sempre memorizzate stringhe e mai valori numerici
possono essere dichiarate come tipo String:
Per
impostazione predefinita, una variabile o argomento di tipo String è una stringa di lunghezza variabile, ovvero
le dimensioni aumentano o diminuiscono in base ai dati assegnati.
In
Visual Basic alle variabili viene automaticamente assegnato il tipo di dati
appropriato. Gli scambi tra stringhe e valori numerici devono essere eseguiti
con cautela.
2.2.6 Il tipo di dati Boolean
Le variabili che includono informazioni di tipo
vero/falso, sì/no e on/off possono essere dichiarate come tipo Boolean. Il
valore predefinito di Boolean è False.
2.2.7 Il tipo di
dati Date
I
valori di data e ora possono essere memorizzati in variabili sia con tipo di
dati specifico Date che di tipo Variant. Entrambi i tipi di dati presentano le
stesse caratteristiche generali.
Nella
conversione di tipi di dati numerici nel tipo Date, i valori a sinistra della
parte decimale rappresentano la data, mentre i valori a destra rappresentano
l'ora. mezzanotte corrisponde a 0, mezzogiorno a 0,5.
2.2.8 Il tipo di
dati Object
Le variabili oggetto sono memorizzate come
indirizzi a 32 bit (4 byte) che fanno riferimento agli oggetti
dell'applicazione o di un'applicazione diversa.
Nella
dichiarazione di variabili oggetto, è consigliabile utilizzare classi
specifiche anziché il tipo generico Object. In Visual Basic i riferimenti a
proprietà e metodi di oggetti con tipi specifici possono essere risolti prima
dell'esecuzione dell'applicazione. In tal modo l'esecuzione dell'applicazione
risulta più veloce. Le varie classi sono elencate nel Visualizzatore oggetti.
Quando
si lavora con oggetti di applicazioni, anziché utilizzare il tipo Variant o il
generico Object, è consigliabile dichiarare gli oggetti così come sono definiti
nell'elenco Classi del Visualizzatore oggetti. In tal modo il tipo di oggetto
specifico a cui si fa riferimento verrà sempre riconosciuto, consentendo quindi
la risoluzione del riferimento in fase di esecuzione.
|
Tipo di dati |
Numero di byte |
Intervallo numerico |
|
Byte |
1 byte |
Da 0 a 255 |
|
Boolean |
2 byte |
True o False |
|
Integer |
2 byte |
Da -32.768 a 32.767. |
|
Long (intero lungo) |
4 byte |
Da-2.147.483.648 a 2.147.483.647 |
|
Single |
4 byte |
Da -3,402823E38 a -1,401298E-45 per valori negativi; da 1,401298E-45 a
3,402823E38 per valori positivi. |
|
Double |
8 byte |
Da -1,79769313486232E308 a -4,94065645841247E-324 per valori negativi;
da 4,94065645841247E-324 a 1,79769313486232E308 per valori positivi. |
|
Currency (intero ridimensionato) |
8 byte |
Da -922.337,203.685.477,5808 a
922.337.203.685.477,5807. |
|
Date |
8 byte |
Dall'1 gennaio 100 a 31 dicembre 9999 |
|
String |
10 byte + lunghezza stringa |
Da 0 a circa 2 miliardi |
|
Variant (con numeri) |
16 byte |
Qualsiasi valore numerico fino all'intervallo
di un Double |
|
Variant (con caratteri) |
22 byte + lunghezza stringa |
Stesso intervallo di String a lunghezza
variabile. |
|
Object |
4 byte |
Qualsiasi riferimento Object. |
2.3 TIPI DI DATI
DI JAVA
Java e un
linguaggio fortemente tipizzato questo significa che ogni variabile deve essere
dichiarata.
Esistono
otto primitivi quattro interi e due in virgola mobile uno per i tipi di
caratteri e uno di tipo booleano.
2.3.1 Tipi interi
Nella
maggior parte dei casi, il tipo int è il più pratico. Per rappresentare cifre
molto alte, occorre usare un numero long. I tipi dati byte e short sono
destinati ad applicazioni specialistiche, quali gestione dei file a basso
livello, oppure array voluminosi quando lo spazio a disposizione è scarso.
2.3.2 Tipi in
virgola mobile
I tipi di dati in virgola mobile denotano numeri con parti frazionarieFra i due due tipi:
Double ha
precisione doppia rispetto al Float.
Il tipo da scegliere nella maggior parte delle applicazioni è il double; la precisione limitata del Float nella maggior parte dei casi non è sufficiente.
2.3.3 Tipo char
Il tipo char denota i caratteri dello schema di codifica Unicode. Unicode è impostato per gestire essenzialmente tutti i caratteri di tutti gli alfabeti del mondo è un codice a 2 byte con la possibilità di scrivere 65.536 caratteri. Attualmente si usano 35.000 il codice quindi risulta più ricco dello standard ANSI. Lo standard ANSI impiegato nella programmazione windows è un sottoinsieme dello schema Unicode più precisamente l’ANSI sono solo i primi 255 caratteri dell’unicode.
2.3.4 Tipo boolean
Ha due soli valori il false e il true.
Mentre in VisualBasic qualsiasi valore diverso da zero è considerato true vero e il valore zero è considerato falso in Java questo non accade. In quest’ultimo un numero non può essere utilizzato dove occorre un valore booleano, ne può essere convertito in un valore booleano come nel caso di VisualBasic che si utilizza l’istruzione CBOOL.
|
tipo di dati |
Numero di bytes |
Intervallo numerico |
|
Int |
4 |
-2.147.483.648 a 2.147.483.647 |
|
Short |
2 |
-32.768 a 32.767 |
|
Long |
8 |
-9.223.372.036.854.775.808 a 9.223.372.036.854.775.807 |
|
Byte |
1 |
Da -128 a 127 |
|
Float |
4 |
±3,40282347E+38 6-7 cifre significative decimali |
|
Double |
8 |
±1,79769313486231570E+308 15 cifre
decimali significative |
|
Bool |
|
False o true
|
|
Char |
2 |
65536
caratteri |
In
generale i tipi di dati
fondamentali dei tre tipi di
linguaggio sono abbastanza simili, fra loro.
In
VisualBasic le matrici di qualsiasi tipo di dati richiedono 20 byte di memoria
più quattro byte per ogni dimensione della matrice, più il numero di byte
occupati dai dati stessi. La memoria occupata dai dati può essere calcolata
moltiplicando il numero di elementi dei dati per le dimensioni di ciascun
elemento. I dati in una matrice unidimensionale composti da quattro elementi di
dati Integer di due byte ciascuno, ad esempio, occupano otto byte. Gli otto
byte richiesti dai dati più i 24 byte di overhead compongono una memoria
complessiva richiesta per la matrice a 32 byte.
Un
tipo di dati Variant contenente una matrice richiede 12 byte in più rispetto al
numero di byte richiesti dalla matrice da sola.
2.4 TIPI DI DATI DELPHI
La trattazione fatta per i tipi di dati in Visual Basic vale anche per i tipi di dati di Delphi. Per completezza, qui di seguito è riportata la tabella per i tipi primitivi di Delphi.
|
Tipo di dati |
Nimero du byte |
Intervallo |
|
Real |
6 |
2.9 x 10-39 .. 1.7 x 10+38 |
|
Single |
4 |
1.5 x 10-45 .. 3.4 x 10+38 |
|
Double |
8 |
5.0 x 10-324 .. 1.7 x 10308 |
|
Extended |
10 |
3.4 x 10-4932 .. 1.1 x 10+4932 |
|
Comp |
8 |
-263+1 .. 263 -1 |
|
Currency |
8 |
-922337203685477.5808.. 922337203685477.5807 |
2.5 DICHIARAZIONE DI VARIABILI CON TIPI
DI DATI
Per poter utilizzare una variabile non di tipo
Variant, è innanzitutto necessario dichiararla .
Un'istruzione
di dichiarazione può essere una combinazione di più dichiarazioni, come negli
esempi seguenti:
Private I As Integer, j As Double VisualBasic
Var i:integer; j :Double;
Delphi
Private Nome As String, conto As Currency VisualBasic
Var Nome :string; conto as
Currency
Delphi
Se
non si specifica un tipo di dati, alla variabile viene assegnato il tipo
predefinito In Delphi come in Java non è possibile utilizzare una variabile se
prima non è stata dichiarata.
2.6 CONVERSIONE DEI TIPI DI DATI
In Visual Basic, Delphi e
Java sono disponibili varie funzioni di conversione che consentono di
convertire i valori in un tipo di dati specifico. In VisualBasic per convertire
un valore nel tipo Double, ad esempio, è possibile utilizzare la funzione Cdbl:
I
valori passati alle funzioni di conversione devono essere validi per il tipo di
dati di destinazione in tutti e tre i linguaggi. In caso contrario, viene
generato un errore.
3
STRUTTURE DATI
FONDAMENTALI
INTRODUZIONE
Accade
spesso che i dati da elaborare siano riuniti in agglomerati detti strutture
dati. Una struttura di dati è un particolare tipo di dato, caratterizzato più
dall’organizzazione imposta agli elementi che lo compongono che dal tipo degli
elementi stessi. In generale il tipo di elementi di una struttura può essere
assunto addirittura parametrico.
Per esempio un vettore è un insieme di
elementi dello stesso tipo. Sugli elementi si possono effettuare operazioni di
lettura e scrittura. La lettura consiste nel reperire il valore di un elemento,
mentre la scrittura consiste nell’inserimento di un elemento nel vettore. In
entrambe le operazioni si accede direttamente al generico elemento
specificandone la posizione all’interno
della sequenza.
Un altro esempio significativo della
programmazione sono i records; un records è un agglomerato di elementi di tipo
diverso. Ogni elemento è individuato con un nome di riferimento e sono
possibili le operazioni di lettura e scrittura. In entrambe le operazioni si accede
al generico elemento specificandone il campo.
Più
precisamente, una struttura dati consiste in:
a)
Un modo sistematico di organizzare i dati;
b)
Un insieme di operatori che permettono di manipolare
elementi della struttura o di aggregare elementi per costruire altri
agglomerati.
La natura
di questa classificazione è di comodità nel rappresentare i dati in base alle
caratteristiche presentate dal loro numero e dal loro tipo.
Solitamente
si tende a distinguerle in:
1.
“Lineari” gli agglomerati di dati disposti in sequenza
caratterizzati nel avere un ordine, un primo elemento e un ultimo elemento.
2.
“Non lineari” , in cui non è definita una sequenza
d’ordine.
3.
“A dimensione fissa”, la dimensione della struttura
rimane costante nel tempo.
4.
“A dimensione variabile” in cui il numero di elementi
può aumentare o diminuire nel tempo;
5.
“Omogenee” in cui i dati sono tutti dello stesso tipo.
6.
“Non omogenee”
in cui i dati non sono dello stesso tipo.
Un vettore
è una struttura lineare omogenea a
dimensione fissa.
Nel descrivere
strutture dati, è opportuno distinguere, come tra tutti i tipi di dato, la
specifica astratta delle proprietà della struttura e i possibili modi con i
quali si può memorizzare la struttura ed eseguire operazioni.
In
particolare, la specifica è distinta in due aspetti fondamentali:
La notazione con cui sono indicati sia i
tipi di dato che le operazioni (specifica sintattica diversa per ogni
compilatore) e il significato associato ad essi (specifica semantica). La
specifica sintattica fornisce l’elenco dei nomi dei tipi di dato utilizzati per
definire una struttura, delle operazioni specifiche della struttura stessa, e
delle costanti. Inoltre descrive i domini di partenza e di arrivo, cioè i tipi
di operandi e del risultato, per ogni operatore.
La specifica semantica invece definisce un
insieme matematico ad ogni tipo introdotto nella specifica sintattica, un
valore ad ogni costante, e una funzione ad ogni nome di operatore. La funzione
è definita matematicamente esplicitando una coppia di condizioni dette
precondizione e postcondizione sul dominio e codominio. Se la precondizione
manca, l’operatore è sempre applicabile,
mentre se è falsa l’operatore non è applicabile. La precondizione indica come
il risultato sia vincolato agli argomenti dell’operatore.
Gli
operatori che modificano la struttura stessa sono le procedure, gli
operatori che restituiscono un primitivo
sono funzioni.
Nel valutare l’efficienza di procedure che utilizzino tipi di dato primitivi si prescinde solitamente dalle caratteristiche della macchina e si assume una organizzazione abbastanza generica come la seguente:
1.
I dati sono contenuti nella memoria;
2.
La memoria è
divisa in celle o parole ognuna delle quali
è di ugual lunghezza (4Byte=32 bit) e può contenere un dato elementare;
3.
I dati elementari non eccedono nella capacità di una
cella ( in Pascal gli interi non superano maxint);
4.
Si accede ad una cella di memoria specificandone
l’indirizzo;
5.
Gli indirizzi delle celle di memoria sono interi
consecutivi.;
6.
Ogni variabile di una procedura o di una funzione è
contenuto in una cella il cui indirizzo è conosciuto solo dalla macchina.
Per
esempio in a=b[i], a,b e i sono tre variabili che
occupano tre celle di memoria.
3.1 PUNTATORI
L’avere
strutture dati a dimensione variabile e
poter restituire strutture di dati come risultato di funzioni e procedure può
essere ottenuto con l’utilizzo di puntatori. I puntatori permettono un accesso
indiretto a un dato , mediante l’indirizzo della cella di memoria a partire dal
quale il dato stesso è memorizzato. Una variabile di tipo puntatore ad un
intero non ha per valore quello dell’intero ma si riferisce al’indirizzo di
cella della memoria che contiene l’intero.
Type puntaintero=^integer
Var
nome:integer
Secondonome: puntaintero
Se nome è
un intero 6 ed è allocato all’indirizzo 10 , nella cella destinata a
secondonome troveremo il numero 10 non
il 6.
3.2 LISTE
Una lista è una sequenza di elementi in cui è possibile aggiungere o togliere elementi. Occorre però specificare la posizione relativa all’interno della sequenza nella quale il nuovo elemento va aggiunto all’interno dell’insieme oppure tolto.
La differenza sostanziale, tra questo tipo di
struttura e quello di un vettore è che
il vettore è a dimensione fissa e l’accesso avviene attraverso indici in
maniera casuale, mentre la lista è a dimensione variabile e si può accedere
solo a particolari sottoinsiemi (solitamente il primo e l’ultimo elemento) di
essa in maniera diretta.
Per accedere ad un elemento che non sia ne
l’ultimo ne il primo è necessario
scandire tutti gli elementi della lista partendo da uno accessibile il primo o
l’ultimo fino a giungere a quello desiderato.
3.3 PILE E CODE
Un pila è
una sequenza di elementi in cui è possibile aggiungere o togliere elementi soltanto ad un estremo della sequenza (la
testa o il vertice). Può quindi essere vista come un caso speciale di lista in
cui l’ultimo elemento inserito è anche
il primo ad essere rimosso e non è possibile accedere ad alcun elemento della
lista che non sia quello sul vertice
della pila. Tale meccanismo è conosciuto con il nome di LIFO (last-in last-out) ed è anche il
metodo con cui la CPU preleva i dati dallo stack.
In maniera analoga una coda è una sequenza di
elementi in cui è possibile aggiungere elementi
ad un estremo (il fondo) e togliere elementi dall’altro (la cima). Può
essere vista come un ulteriore tipo
di lista in cui il primo elemento
ad essere inserito è anche l’ultimo ad essere rimosso. Questo meccanismo prende
il nome di FIFO (first-in first-out).
Nelle
aziende che producono dei servizi la gestione delle pile e delle code è
fondamentale al fine di produrre efficienza di servizio.
Una importante applicazione delle pile
consiste nella gestione dell’esecuzione di procedure ricorsive. Infatti l’esecuzione
di una procedura ricorsiva prevede il salvataggio dei dati sui quali lavora la
procedura al momento di una nuova chiamata ricorsiva interna.
3.4 ALBERI
In generale
un albero può essere visto come un particolare tipo di lista in cui un elemento
pùò avere ancora un solo predecessore,il padre e molti successori, i figli.
L’albero
ordinato o semplicemente albero è una struttura fondamentale , che si presta a
rappresentare svariate sittuazioni, quali:
1.
Partizioni successive di un insieme in sottoinsiemi disgiunti.
2.
Organizzazioni gerarchiche di dati;
3.
Procedimenti enumerativi o decisionali;
Gli esempi
più comuni sono albero genealogico, indice di testo, classificazioni , alberi
sintatici ecc.
Importante
in questa struttura di dati è la visita di un albero che consiste nel seguire
una rotta di viaggio consentendo di esaminare ogni nodo dell’albero esattamente
una volta. La visita può essere eseguita in vari modi, detti ordini tra cui i
più importanti sono tre: ordine anticipato, differito e simmetrico.
3.5 ALBERI BINARI
Un albero binario è un particolare albero in cui ogni nodo ha al più due figli e viene effettuata una distizione tra figlio destro e figlio sinistro di un nodo. Questa proprietà rende diversi due alberi binari qualora, avendo lo stesso padre gli stessi figli, gli stessi nodi, hanno due figli scambiati destro sinistro sinistro destro.
In questa
struttura rientrano tutti i più importanti alberi decisionali.
3.6 INSIEMI
Un insieme
è una collezione di elementi dello stesso tipo. L’insieme è una struttura
matematica fondamentale e può essere descritto o elencandone tutti gli elementi
o stabilendo una proprietà che li caratterizzi. A differenza delle liste, gli
elementi non sono caratterizzati da una posizione, né sono ammesse più coppie
dello stesso elemento nel medesimo insieme.
3.7 DIZIONARI
La struttura a dizionario è un caso particolare di insieme, in cui è possibile verificare l’appartenenza di un elemento, cancellare un elemento e inserirlo . Gli elementi dei questa struttura sono denominati chiavi.
3.8 CODE CON
PRIORITÀ
Una coda con priorità è un particolare insieme con priorità sugli elementi del quale è definita una relazione di precedenza di ordinamento totale, in cui è possibile inserire un elemento o estrarre l’elemento minimo.
3.9 ALBERI BILANCIATI DI RICERCA
Le varie strutture dati di tipo insieme, viste in precedenza, privilegiano l’efficienza di certi operatori rispetto ad altri. Alcuni privilegiano le operazioni di coda altri si prestano ad eseguire efficientemente le operazioni dei dizionari, inoltre esistono alcune strutture di dati che ammettono operazioni sia su code con priorità che dizionari. La realizzazione di tale tipo di struttura si basano sull’impiego di Alberi Binari di ricerca.
Un albero binario di ricerca gode delle seguenti proprietà:
1. Per ogni nodo u tutti gli elementi contenuti nel sottoalbero radicato nel figlio sinistro di u sono minori dell’elemento contenuto in u.
2. Per ogni nodo u , tutti gli elementi contenuti nel sottoalbero radicato nel figlio destro di
u sono maggiori dell’elemento contenuto in u.
3.10 GRAFI
Un grafo G è una coppia (V,E)
in cui V è un insieme di vertici ed E un insieme di lati (o archi A)
Si possono dividere in grafi orientati e non orientati.
Grafi non orientati:
G = (V,E) (definizione del grafo)
|V| = n (n è il numero di
vertici)
|E| = m (m è il numero di
lati)
Vertici V = { v[1], v[2],..., v[n] }
Lati = coppie di vertici E = { e[1],
e[2],..., e[m] }
e[i] = ( v[i], v[j] ) = (v[j] ,v[i] )
Grafi orientati:
G = (V,A) (definizione del grafo)
|V| = n (n è il numero di
vertici)
|A| = m (m è il numero di
archi)
Vertici V = { v[1], v[2],..., v[n] }
Archi = coppie ordinate di vertici A
= { a[1], a[2],..., a[m] }
a[i] = ( v[i], v[j] ) diverso da ( v[j], v[i] )
4
LA PROGRAMMAZIONE
AD OGGETTI
INTRODUZIONE
I programmi
sono progettati decidendo quali oggetti verranno utilizzati e quali azioni
svolgeranno.
Per esempio un oggetto può essere una gomma di automobile ad essa sono associate
proprietà per la descrizione di attributi visibili, come il diametro, la
larghezza tipo mescola, e per la descrizione dello stato, ovvero la “gomma è
gonfia” o la “gomma è sgonfia di natura visibile e l’età di attributi di natura
invisibile.
In generale per tutte le gomme sono
disponibili le stesse proprietà, le cui impostazioni possono essere tuttavia
diverse.
Ad una gomma d’auto possono essere associati
dei metodi specifici, ovvero azioni, quali ad esempio il metodo per gonfiare la
gomma (Gonfiare), il metodo per sgonfiarla(Sgonfiare) etc.
Per l’oggetto “gomma” inoltre sono previste
determinate risposte a eventi esterni specifici, ad esempio lo sgonfiarsi della
gomma quando viene forata con un oggetto appuntito, il rotolare se viene spinta
etc.
Se fosse possibile programmare una gomma per
esempio in VisualBasic, il codice sarebbe simile a:
Gomma.Mescola=Morbida
Gomma.Diametro=50
Gomma.larghezza=25
E’
possibile modificare una delle proprietà ripetendo nuove istruzioni e
impostando valori diversi.
In maniera
uguale vengono richiamati i metodi della gomma:
Gomma.Gonfiare()
Gomma.Sgonfiare()
Ad alcuni metodi sono associati uno o più
argomenti che consentono di descrivere in modo più dettagliato, l’azione
eseguita per esempio un suono durante lo sgonfiamento.
La risposta
della gomma ad un evento può essere simile alla seguente:
Sub
Gomma_Foratura ()
Gomma.Sgonfiare
(“Pssssssss”)
Gomma.Gonfia=False
Gomma.Diametro=1
Gomma.Larghezza=
40
End
In questo esempio, il codice descrive il
funzionamento della gomma quando si verifica l’evento foratura: e viene
richiamato il metodo di sgonfiatura con la caratteristica “suono”; dato che la
gomma non è più gonfia la proprietà gonfia viene impostata, “False” inoltre le
due proprietà del diametro e della larghezza si modificano.
4.1 OBJECT ORIENTED
Per programmazione orientata agli oggetti s’intende scrivere programmi che definiscono classi i cui metodi eseguono le istruzioni del programma.
I programmi orientati agli oggetti sono progettati decidendo prima quali classi saranno necessarie e poi definendo i metodi che risolvono il problema.
Al fine di una migliore comprensione del
vasto argomento dell’object-oriented, è necessario rivolgere l’attenzione ai
linguaggi di programmazione che si prestano a questo particolare tipo di
trattazione che sono il C++ o Java. Visto che Java è molto simile per gli
aspetti che prenderò in considerazione al C++ il quale tra l’altro esula
dall’argomento di questa tesi, l’analisi sarà fatta sul linguaggio Java.
Supponiamo di dover scrivere un programma di
geometria piana. In questo caso, gli oggetti sono: punti, linee, triangoli,
cerchi etc. Possiamo astrarre questi elementi geometrici definendo classi
composte da oggetti che rappresentino proprio punti, linee e triangoli.
Sappiamo inoltre che i punti sono usati per definire linee, così
usiamo una classe PUNTO per definire la nostra classe LINEA.
Questo riutilizzo del software è uno degli
aspetti fondamentali nella programmazione orientata agli oggetti.
Questa
classe usa il suo metodo main() come test
public class punto
{
// oggetti che rappresentano i punti sul piano cartesiano
private punto(double a, double b) {
x = a;
y = b;
}
public double x() {
return x;
}
public double y() {
return
y;
}
public boolean equals(punto p) {
return ((x == p.x) && (y == p.y));
}
public String toString() {
return new String(“(“ + x
+ “,”+ y + ”)”);
}
public static
void main(String[] args) {
punto p = new Point(2,3);
System.out.println(“p.x()=” + p.x() + ”,p.y()=“ + p.y());
System.out.println(“p = “+ p);
punto q = new punto(7,4);
System.out.println(“q= “ + q);
if (q.equals(p)) System.out.println(“q
è uguale a p”);
else System.out.println(“q non
è uguale a p”);
punto q = new punto(2,3);
System.out.println(“q= “ + q);
if (q.equals(p))
System.out.println(“q è uguale a p”);
else
System.out.println(“q non è uguale a p”);
}
} //Fine classe punto
il
risultato è il seguente:
p.x()=2.0, p.y()=3.0
p=(2.0,3.0)
q non è uguale a p
q=(2.0,3.0)
q è uguale a p
La classe
ha due campi, x e y, i cui valori sono le coordinate del “punto” che l’oggetto
rappresenta.
La prima
riga del metodo main() è:
punto p=
new punto (2,3);
Questa
istruzione congiunge tre cose.
Dichiara p
come riferimento a oggetti “punto”.
Applica
l’operatore new per creare un nuovo oggetto con i valori 2 e 3
Inizializza
il riferimento p con questo nuovo oggetto.
L’istruzione
può essere esemplificata nel seguente modo.

Il valore della variabile è una qualsiasi
informazione necessaria al Sistema Operativo per accedere all’oggetto.
L’aspetto importante di questo è che gli oggetti non hanno nomi, ma
soltanto riferimenti. È possibile fare riferimento all’oggetto come
fosse il suo nome.
La seconda riga in main() richiama i due
metodi x() e y() per ottenere i valori dei campi di p in modo che il metodo
println() possa stampare la prima riga di output, confermando proprio che i
valori dei campi di p sono 2 e 3.
Questa
istruzione richiama tre metodi, x() e y() della classe “punto” e println della
classe System.
La terza
riga richiama il metodo toString.
L’istruzione
punto p=new punto (2,3) è identica alla
prima e il risultato di tale operazione è il seguente
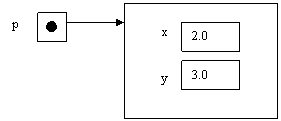
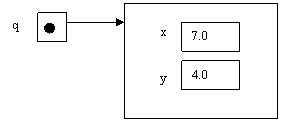
L’istruzione
if richiama il metodo equals() per verificare se i due oggetti sono uguali.
Essi non
sono uguali, solo con l’istruzione q=new Point (2,3) li si rende uguali e il
risultato è il seguente:
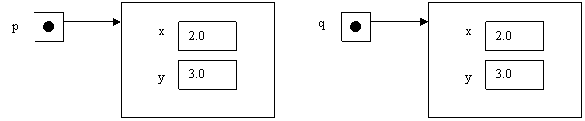
Questa operazione non un semplice assegnamento
ma è successo qualcosa di particolare. L’operatore new ha richiamato il
costruttore dell’oggetto “punto”. Viene creato un nuovo oggetto q di tipo
“punto” ed il vecchio viene automaticamente distrutto, di conseguenza la
memoria viene correttamente deallocata dalla Java Virtual Machine (JVM). Quindi
i bytes che esso occupava in memoria possono essere restituiti alla RAM ed
essere utilizzati per altri scopi.
L’ultima
istruzione if invece richiama il metodo equals() e conferma l’uguaglianza tra i
punti.
Aspetto
importante dell’istruzione if è che l’uguaglianza non implica identità e questo
significa che i due oggetti “punto” sono uguali nelle proprietà ma distinti
come oggetti.
Per Java, a
differenza di Delphi, un oggetto in memoria esiste finché ha un
riferimento; Delphi, invece, nel momento
in cui un puntatore non punta più a un oggetto, è un radicale libero nella
memoria ovvero esiste ma non è più utilizzabile.
Questa è una prerogativa di Java rispetto ad
altri linguaggi. Java demanda al sistema operativo ospite il compito di
rimuovere correttamente un oggetto liberando la memoria occupata, operazione
che viene gestita dalla JVM. In altri linguaggi questo compito spetta al
programmatore. Questo aspetto, se da un lato presenta meno preoccupazioni,
dall’altra provoca lo svantaggio di rendere Java più lento di altri linguaggi.
4. 2 DICHIARAZIONI.
Tutte le
classi, i campi, le variabili locali, i costruttori e i metodi devono essere
dichiarati. Un Campo deve essere dichiarato come proprietà di una classe, una
variabile locale come un membro di un costruttore o di un metodo.
Con riferimento all’esempio precedente la
parte iniziale del codice è la seguente:
Public class punto
{// oggetti che
rappresentano i punti sul piano
cartesiano
private punto(double a, double b)
{ x = a;
y= b;
}
Public double x()
{return x;
}
Public double y()
{return y;
}
public boolean equals(punto p)
{ return (x = = p.x & & y = = p.y);
public String toString()
{ return new String(“(+ x +”,” + y+ ”)”);
Questa è la
dichiarazione della classe “punto” cioè:
Due
dichiarazioni di variabili x e y, la dichiarazione di un costruttore punto() e
cinque dichiarazioni di metodo equals(), toString, main(), x(), e y()
E’ stata
costruita la classe “punto”, ora
costruiamo la classe “linea”
public class linea
{ private punto p0 // un punto della
linea
Private
double m // la pendenza della linea
Public linea(punto, double
s)
{p0=p;
m=s;
}
public
pendenza()
{return m;
}
public double yintercetta()
{return
(p0.y()-m*p0.x());
}
public boolean
equals (Linea linea)
{return
(pendenza() == linea.pendenza()
&& yintercetta()
==linea.yintercetta());
}
public String toString()
{return new String(“y=” +(float)m+”x +”
+(float)yintercetta());}
Publica static
void main (String[] args)
{punto
p=new punto(5,-4);
linea
linea1=new linea (p,-2);
System.out.println
(“\nL’ equazione della linea 1 è “+ linea1);
System.out.println(“
La sua pendenza è “ + linea1.slope() +” e la sua intercetta y è “ +
linea2.yintercetta());
If (linea2.equals(linea1)
System.out.println(“Esse sono uguali.”);
else System.out.println(“esse
non sono uguali.”);
point q=new point (2,2);
linea2= new linea(q,2);
System.out.println(“\nL’equazione
della linea2 è “ +linea2);
System.out.println(“la sua pendenza è “ +linea2.pendenza() + “ e la sua intercetta è” +yintercetta());
if (linea2.equals(linea1))
System.out.println(“esse sono uguali”);
else System.out.println(esse
non sono uguali”)
il
risultato è il seguente
L’equazione
della linea1 è y=-2.0x+6.0
La sua
pendenza è –2.0 e la sua intercetta y è 6.0
L’equazione
della linea2 è y=-1.0x+1.0
La sua
pendenza è -1.0 e la sua intercetta y è 1.0
Esse
non sono uguali
L’equazione
della linea2 è y=-2.0x+6.0
La sua
pendenza è –2.0 e la sua intercetta y è 6.0
esse sono uguali
Questo programma inizia creando due oggetti uno di tipo “punto” e uno di tipo “linea”: “punto” p e “linea” linea1. L’oggetto punto ha due campi: x e y entrambi con due valori assegnati. Anche l’oggetto “linea” ha due campi p0 che si riferiscono all’oggetto punto p ed m di tipo double con valore –2
Essi
rappresentano un punto sulla retta e la pendenza della stessa. Successivamente
alla creazione degli oggetti il programma testa i metodi toString, yintercetta,
pendenza.
Ricordando
la formula dell’intercetta b=y0-m·x0 dove (x0,y0) è un punto sulla retta ed m
la sua pendenza, il programma crea un altro oggetto “linea”, linea2 che si
riferisce allo stesso oggetto “punto” ma il suo valore di pendenza è –1.
Quanto è
stato detto è rappresentabile attraverso la figura di pagina seguente.
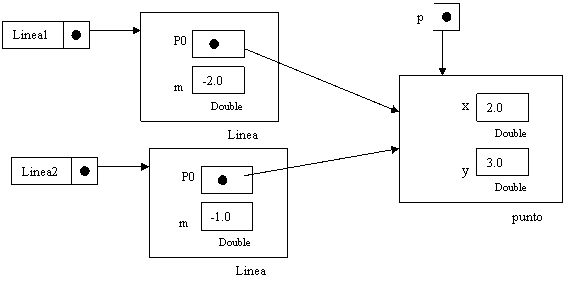
Viene
richiamato il metodo toString() e il metodo equals() per vedere se le due rette
sono uguali.
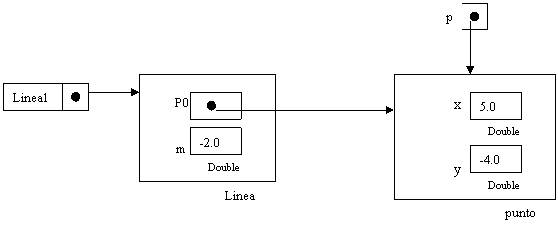 L’ultima
parte del programma crea un secondo oggetto “punto” e un terzo oggetto “linea”
e le successive istruzioni portano a questa esemplificazione.
L’ultima
parte del programma crea un secondo oggetto “punto” e un terzo oggetto “linea”
e le successive istruzioni portano a questa esemplificazione.
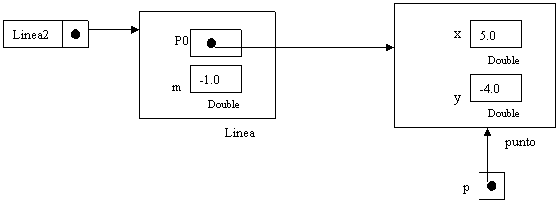
I metodi x() y() e pendenza() sono chiamati “metodi di accesso” perché
forniscono semplicemente l’accesso pubblico ai campi privati degli oggetti.
4.3
COSTRUTTORI
Uno degli aspetti fondamentali della programmazione ad oggetti sono i costruttori.
Un costruttore è una particolare tipo di
funzione il cui unico scopo è di creare gli oggetti di una classe, come abbiamo
visto negli esempi:
I
costruttori di classe godono delle seguenti caratteristiche:
1.
Hanno lo stesso nome della classe stessa
2.
Non hanno tipo di ritorno
3.
Vengono richiamati da un operatore.
Ogni classe
ha almeno un costruttore. Se non si dichiara alcun costruttore della classe, il
compilatore ne dichiarerà uno automaticamente senza argomenti. Questo è
chiamato costruttore di default.
4.4 IDENTITÀ UGUAGLIANZA
EQUIVALENZA
Un altro
aspetto molto importante della programmazione ad oggetti è quello della
distinzione tra il nome del oggetto, l’oggetto stesso, e quello che
rappresenta.
Nell’esempio l’oggetto “linea” poteva avere
riferimenti diversi e che due oggetti distinti potevano rappresentare la stessa
linea.
La distinzione tra identità ed equivalenza la possiamo chiarire dicendo che in algebra il caso x2-1=(x-1)·(x+1) è sempre vera e l’equazione y=x2-1 è vera in alcuni casi.
Identicamente uguali significa differenti solo nel nome. Il presidente Scalfaro e Oscar Luigi Scalfaro sono identicamente uguali perché sono solo nomi differenti per la stessa persona.
In un linguaggio ad oggetti il concetto di identicamente uguali si può esemplificare:
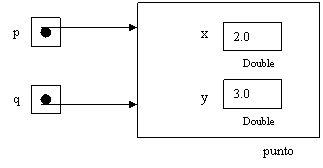
q è uguale a p si può invece esemplificare come
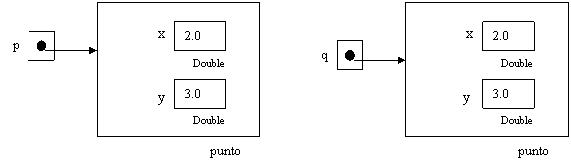
Questo modo di rappresentare l’uguaglianza e l’identità è utile per dimostrare che l’operatore di uguaglianza nel Object-Oriented non è molto utile per confrontare gli oggetti. Esso determina solo se i loro riferimenti sono differenti . Così, per verificare l’uguglianza tra due oggetti di tipo “punto”, è stato necessario creare un metodo equals().
4.5
COMPOSIZIONE ED EREDITARIETÀ
Il perché della potenza della programmazione ad oggetti è da ricercare in questo aspetto nella ereditarietà e composizione delle classi.
In altre parole la facilità di riutilizzare le implementazioni per altri scopi.
4.5.1 Composizione
Per composizione si intende la creazione di una classe usando un’altra per i suoi dati componenti.
Nel esempio è stata definita la classe “linea” a partire dalla classe “punto”.
4.5.2 Ereditarietà
Ereditarietà è la creazione di una classe estendendone un’altra in modo che le istanze della nuova ereditino automaticamente i campi e i metodi della sua classe genitore.
Eredità significa, in questo caso, specializzazione. Una sottoclasse si specializza ereditando tutti i campi e i metodi della sua superclasse e aggiungendone altri. L’insieme di tutti gli oggetti di una sottoclasse è un sottoinsieme dell’insieme di tutti gli oggetti della superclasse. L’insieme di tutti gli studenti è un sottoinsieme dell’ insieme di tutte le persone.
Se eredità è sinonimo di specializzazione, composizione è sinonimo di aggregazione. La classe di tutti gli studenti è una specializzazione dell’insieme delle persone, mentre è un’aggregata della classe nome di tipo String. Questo significa, in linguaggio parlato, che uno studente è una persona che ha un nome. Nella lettura di programmazione si usano spesso le frasi “è una” e “ha una” per distinguere ereditarietà e composizione. E’ in sostanza la chiara distinzione tra l’essere e l’avere.
4.6 GERARCHIA DELLE CLASSI
Una classe può avere più sottoclassi. Nell’insieme delle persone non esiste solo il sottoinsieme degli studenti ma anche quelle degli operai, dei Professori etc. Inoltre una sottoclasse può avere ulteriori sottoclassi infatti esiste la sottoclasse degli studenti universitari, la sottoclasse degli studenti delle scuole medie-superiori etc.
Queste relazioni definiscono una struttura gerarchica delle classi.
Quanto è stato detto può essere rappresentato nella seguente figura.
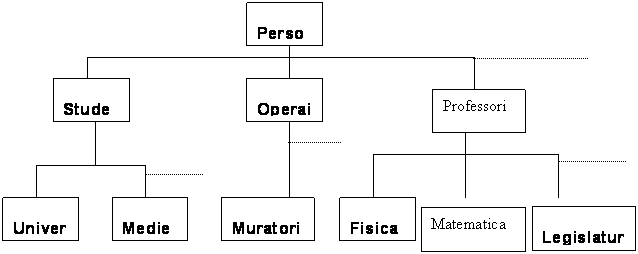
Come in Delphi esiste il Tobject, anche in Java esite la classe Object che definisce l’antenato di ogni altra classe.
6
TEORIA DELLA
COMPILAZIONE
6.1 PREMESSA
L'obiettivo
di questa analisi è capire come avviene la traduzione da un linguaggio di alto
livello a linguaggio macchina (compilazione) cioè di basso livello.
Il
linguaggio utilizzato è il Pascal ma è
estendibile a tutti i compilatori;
Le
motivazioni della scelta sono:
-
Scopo didattico
-
Object oriented
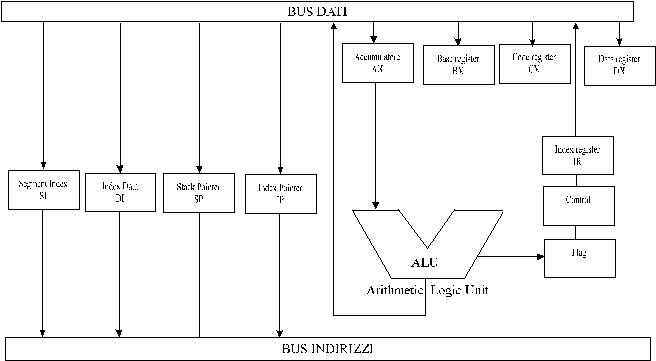
Ai fini di una maggiore comprensione del capitolo riporto uno dei tanti schemi a blocchi
della cpu presenti in letteratura.
6.2 METODOLOGIA DI ANALISI
In una
directory vuota sono stati copiati i file TPC.EXE e TURBO.TPL,
Per
semplificare i comandi ho creato questi tre file batch:
- E.BAT
-
C.BAT
-
D.BAT
Nella
directory “lavoro1” esistono i seguenti
files con relativa estensione:
TPC .
EXE (compilatore pascal)
TURBO.
TPL (librerie per TpC)
E .BAT (edit)
C.BAT (compila)
D.BAT (debug)
6.3 ASSEGNAZIONE DI VARIABILI
Uno dei
compiti principali per il programmatore indipendentemente dal linguaggio
utilizzato, è l’assegnazione di variabili.
Ho prodotto
il file prog1.pas questo è un file
contenente una dichiarazione di variabile con due assegnazioni caratteristiche
del Pascal.
C:\Lavoro1\prog1.pas
|
Integer.PAS Var i,j :Integer; Begin i:=5; j:=i+3; End. |
Caratteristiche di compilazione
5
lines, 0.1 seconds, 1376 bytes code, 672 bytes data.
.
6.4 ORGANIZZAZIONE DELLA MEMORIA
|
file integer.MAP Start Stop
Length Name Class 00000H 0001BH 0001CH PROGRAM CODE 00020H 00556H 00537H System CODE 00560H 007FFH 002A0H DATA DATA 00800H 047FFH 04000H STACK STACK 04800H 04800H 00000H HEAP HEAP Address Publics by Value 0000:0000 @ ………………………….. 0056:0034 ErrorAddr 0056:0038 PrefixSeg 0056:003A StackLimit 0056:003C InOutRes 0056:003E RandSeed 0056:0042 SelectorInc 0056:0044 Seg0040 0056:0046 SegA000 0056:0048 SegB000 0056:004A SegB800 0056:004C Test8086 0056:004D Test8087 0056:004E FileMode 0056:0050 i 0056:0052 j 0056:0054 Input 0056:0154 Output 0056:0254 SaveInt00 0056:0258 SaveInt02 ……………………….. 0056:0294 SaveInt3E 0056:0298
SaveInt3F 0056:029C SaveInt75 Program entry point at
0000:0000 |
I segmenti
del programma sono cinque nell'ordine in cui sono memorizzati in memoria,
- PROGRAM
- SYSTEM
- DATA
- STACK
- HEAP
Il segmento
PROGRAM contiene il codice del
programma, cioè tutto il linguaggio scritto tra begin e end è lungo 1Fh=31
bytes; infatti se contiamo le istruzioni macchina seguenti, noteremo che sono
31.
Il segmento
di codice usato dal Turbo Pascal per contenere funzioni di libreria e/o altro è
SYSTEM che occupa 537h=1335 bytes e i segmenti data e stack che realizzano la
suddivisione della memoria, atta a
contenere le variabili da noi definite
DATA, e di una porzione per le operazioni STACK .
La prima
istruzione di Integer.PAS, cioè
Var i,j :
Integer;
istruisce il compilatore ad allocare memoria per due variabili da 2 byte chiamate i e j. Dalla mappa di memoria risulta che i e j iniziano agli offset 50 e 52 (hex) del segmento dati. Il segmento dati è lungo 2A0h=672 bytes e inoltre è stato creato uno stack con capienza di 4000h=16384 bytes=16 Kb.
Nel file con estensione .MAP Sono indicati il punto d'inizio (Start) e di fine (Stop) dei segmenti, gli indirizzi assoluti nell'ipotesi che il programma inizi all'inizio della memoria 0000:0000 (in realtà quando il programma sarà caricato potrà iniziare in un punto qualsiasi della memoria; anzi tecnicamente non è proprio possibile che inizi da 0000:0000 in quanto la parte più bassa della memoria è riservata al sistema. Per calcolare la posizione delle variabili i,j è necessario calcolare i loro indirizzi assoluti. Ad esempio per la variabile “i“ abbiamo:
0056:0050
<=> 00560+00050 = 005B0 è compreso nell’intervallo:
00560H (Start DATA) <= 005B0H <= 007FFH (Stop
DATA)
Effettuando il debug di questo programma attraverso
il file bacth d.bat, otteniamo:
C:\Lavoro1\d prog1
-r
AX=0000
BX=0000 CX=03F0 DX=0000
SP=4000 BP=0000 SI=0000
DI=0000
DS=2095 ES=2095
SS=2125 CS=20A5 IP=0000
NV UP EI PL NZ NA PO NC
20A5:0000 9A0000A720 CALL
20A7:0000
In CX c'é la dimensione del programma .EXE: sono 3F0h=1008 bytes, attraverso il comando dir DIR del DOS, possiamo notare una dimensione di 1520 bytes. Questo perchè 1520-1008=512 bytes mezzo kb è lo spazio occupato dall'EXE File Header che non viene computato in CX. Il DOS ha rilocato il programma: SP si trova a 4000h=16384 (perché lo stack è grande 16kb ) e CS, IP e SS sono stati impostati. Come si può vedere la procedura FAR di chiamata ( si trova a (20A7-20A5=2)*16 = 32 bytes dopo l’inizio del codice compreso tra Begin e End):
-p {comando di debug}
AX=0000
BX=20A7 CX=0405 DX=20A7
SP=4000 BP=0000 SI=0264
DI=0154
DS=20FB
ES=20FB SS=2125 CS=20A5
IP=0005 NV UP EI PL ZR NA PE NC
20A5:0005 55 PUSH BP
E’ la procedura di inizializzazione del compilatore.
-t {comando
di debug}
AX=0000
BX=20A7 CX=0405 DX=20A7
SP=3FFE BP=0000 SI=0264
DI=0154
DS=20FB
ES=20FB SS=2125 CS=20A5
IP=0006 NV UP EI PL ZR NA PE NC
20A5:0006 89E5 MOV BP,SP
PUSH BP salva il registro BP corrente, mentre MOV BP,SP imposta BP come puntatore ai parametri. Il Base pointer (BP) in questo programma non viene utilizzato, tuttavia il compilatore ha eseguito lo stesso le istruzioni che servono a salvarlo, impostarlo e ripristinarlo.
-t {comando di debug}
AX=0000 BX=20A7 CX=0405
DX=20A7 SP=3FFE BP=3FFE
SI=0264 DI=0154
DS=20FB
ES=20FB SS=2125 CS=20A5
IP=0008 NV UP EI PL ZR NA PE NC
20A5:0008
C70650000500 MOV WORD PTR [0050],0005 DS:0050=0000
-t {comando di debug}
AX=0000
BX=20A7 CX=0405 DX=20A7
SP=3FFE BP=3FFE SI=0264
DI=0154
DS=20FB
ES=20FB SS=2125 CS=20A5
IP=000E NV UP EI PL ZR NA PE NC
20A5:000E A15000 MOV
AX,[0050]
DS:0050=0005
-t {comando di debug}
AX=0005
BX=20A7 CX=0405 DX=20A7
SP=3FFE BP=3FFE SI=0264
DI=0154
DS=20FB
ES=20FB SS=2125 CS=20A5
IP=0011 NV UP EI PL ZR NA PE NC
20A5:0011 050300 ADD
AX,0003
Con queste due istruzioni abbiamo calcolato in AX la
quantità i+3.
-t {comando
di debug}
AX=0008
BX=20A7 CX=0405 DX=20A7
SP=3FFE BP=3FFE SI=0264
DI=0154
DS=20FB
ES=20FB SS=2125 CS=20A5
IP=0014 NV UP EI PL NZ NA PO NC
20A5:0014 A35200 MOV
[0052],AX
DS:0052=0000
memorizzazione del
risultato in AX nelle due celle riservate a j, la 52 e la 53.
-t {comando di debug}
AX=0008
BX=20A7 CX=0405 DX=20A7
SP=3FFE BP=3FFE SI=0264
DI=0154
DS=20FB
ES=20FB SS=2125 CS=20A5
IP=0017 NV UP EI PL NZ NA PO NC
20A5:0017 5D POP BP
viene ripristinata
la vecchia versione di BP e termina il programma (con apposita procedura
di terminazione aggiunta dal compilatore).
-t {comando di debug}
AX=0008
BX=20A7 CX=0405 DX=20A7
SP=4000 BP=0000 SI=0264
DI=0154
DS=20FB
ES=20FB SS=2125 CS=20A5
IP=0018 NV UP EI PL NZ NA PO NC
20A5:0018 31C0 XOR AX,AX
-t {comando di debug}
AX=0000
BX=20A7 CX=0405 DX=20A7
SP=4000 BP=0000 SI=0264
DI=0154
DS=20FB
ES=20FB SS=2125 CS=20A5
IP=001A NV UP EI PL ZR NA PE NC
20A5:001A 9A1601A720 CALL
20A7:0116
6.5
PROCESSO DI RILOCAZIONE
Esistono
dei gap di memoria che sono delle aree di memoria inutilizzati, questo perché
ogni segmento può solo iniziare agli offset 0000.
Poiché i
segmenti iniziano ogni 16 byte di memoria, ne segue che i gaps non potranno mai
essere più grandi di 15 bytes.
Il valore
di CS (code segment) è conosciuto solo in fase di caricamento e quindi potrebbe
variare tra un esecuzione e l’altra del programma. Sulla base di questo valore
il caricatore del DOS effettua il calcolo di DS(data segment),ES(extra
segment),SS(stack segment) con le semplici formule: DS=ES=CS+56h; SS=CS+80h. Inoltre imposta IP (index pointer)
ed SP(stack pointer) in tal caso rispettivamente a 0 e 4000h. Le costanti 0, 4000h,
56h, 80h sono tutte prese dalla Relocation Table. In sintesi questo è il
processo di rilocazione.
6. 6 UN CALCOLO
ARITMETICO
|
calc.PAS Var
a,b,c,d,f : Integer; Begin a:=1; b:=2; c:=5; d:=3; f:=3; Inline($90/$90/$90); a:=(a+b)*(c-d)+f; { a sarà 9 }
Inline($90/$90/$90); End. |
Il
programmatore ricorre abbastanza spesso a dei calcoli matematici.
Le istruzioni Inline che racchiudono l’assegnazione con espressione aritmetica contengono tre byte con valore 90h. In linguaggio macchina 90h corrisponde all’istruzione di operazione nulla (NOP, No Operation).Questo artificio è stato utilizzato per poter riconoscere all’interno del codice macchina la parte di programma analizzata, il NOP può essere inserito in qualunque punto di un programma senza danno.
Un
programma presenta difficilmente tre istruzioni NOP in fila.
Per poter
localizzare la parte di codice attraverso l’istruzione search del debug
-s cs:0 ffff 90 90 90
Si otterrà la seguente risposta:
20A5:0026
20A5:0042
Indica che il codice che interessa è localizzato
allo spiazzamento 0026. Per vederlo è necessario utilizzare il comando U 26,42
(Unassemble):
20A5:0026 90 NOP guardando
il MAP file, o come sono
20A5:0027 90 NOP state
tradotte le
inizializzazioni
20A5:0028 90 NOP di
a,b,c,d,f, si rilevano le
20A5:0029 A15400 MOV
AX,[0054] seguenti
corrispondenze:
20A5:002C 2B065600 SUB
AX,[0056]
20A5:0030 8BD0 MOV DX,AX INDIRIZZO VARIABILE
20A5:0032 A15000 MOV
AX,[0050] 0050 A
20A5:0035 03065200 ADD
AX,[0052] 0052 B
20A5:0039 F7E2 MUL DX 0054 C
20A5:003B 03065800
ADD AX,[0058] 0056 D
20A5:003F A35000
MOV [0050],AX 0058 F
20A5:0042 90 NOP
Rendendo più chiaro il codice:
MOV
AX,C Due note riguardo
questa
SUB
AX,D scomposizione:
MOV
DX,AX - notate che DX
funziona come a:=(a+b)*(c-d)+f;
MOV
AX,A una variabile temporanea,
ADD
AX,B per memorizzare un risultato
MUL
DX intermedio
ADD
AX,F - i numeri trattati
sono signed,
MOV A,AX
6. 7 IF ... THEN ...
|
ifthen.PAS -------------------------- Var
a,b,c, max : Integer; Begin ReadLn(a,b,c); max:=a; If
a<b Then max:=b; If
max<c Then max:=c; WriteLn('Max:
', max) End. |
Questo semplice programma legge tre interi e dice qual è il massimo.
Ho
selezionato il codice macchina di interesse, aggiungendo le etichette e
commenti:
;ReadLn(a,b,c)
|
estratto
da MAX.MAP ------------------- ................. ................. DS:0052
a DS:0054
b DS:0056
c DS:0058
max ................. ................. |
MOV
AX,a ;max:=a
MOV max,AX
MOV AX,a ;valutazione di a<b
CMP AX,b
JGE FineIf1 ;condizione falsa
MOV AX,b
;max:=b
MOV max,AX
FineIf1: MOV
AX,max ;max<c ?
CMP AX,c
JGE FineIf2
;no, salta
MOV AX,c
;max:=c
MOV
max,AX
Per tradurre un linguaggio ad alto livello l’istruzione max occorrono due istruzioni mov in quanto il processore non può fare il trasferimento diretto da memoria-memoria: occorre prima copiare il dato dalla memoria in un registro ax e poi dal registro un’altra locazione di memoria. Più in generale in una istruzione si può avere solo accesso alla memoria, come si può notare anche l’istruzione CMP compara a,b.
6. 8 IF ...
THEN ... ELSE
|
Ifthenelse.PAS ----------------------- Var number:Integer; sign:Char; Begin ReadLn(number); Inline($90/$90/$90); If
number < 0 Then sign:='-' Else sign:='+'; WriteLn(sign); End. |
001A NOP
001B NOP
001C NOP
001D CMP
WORD PTR [0052],+00
0022 JGE
002B
0024 MOV
BYTE PTR [0054],2D If Then Else
0029 JMP
0030
002B MOV
BYTE PTR [0054],2B
INFO: WORD
PTR [0052]=number; BYTE PTR [0054]=sign; 2D=‘-’;
2B=‘+’.
6.9 IF ED ELSE “ANNIDATI”
|
Ifelseann.PAS ------------------------------------------- Var
x,y:Word; Begin Write ReadLn(x,y); If
x<y Then WriteLn Else
Begin if
x>y Then WriteLn Else WriteLn; End; End. |
MOV AX,X ;x<y
?
CMP AX,Y
JNB Else1 ;no,altro
confronto
......... ;si, stampa x<y
JMP End
Else1:MOV AX,X ;x>y
?
CMP AX,Y
JBE Else2
......... ;si, stampa x>y
JMP End
Else2:......... ;no,
stampa x=y
End: .........
In questo programma è stato introdotto il tipo di dati Word anziché Integer.
Word ha la stessa capienza di Integer (2 byte), ma mentre Integer è signed, Word è unsigned. Nell’Assembler dei processori della famiglia 8086 ci sono istruzioni di salto condizionato, diverse a seconda che gli interi siano visti come valori col segno o senza.
6.10 VALUTAZIONE
BOOLEANA MINIMA E COMPLETA
|
Boolean.PAS -------------------------- Var b : boolean; c : byte; Begin ReadLn(c); b := (c>=0) And (c<10); WriteLn(b); End. |
La valutazione (a risoluzione) minima (o incompleta) delle espressioni booleane riduce il tempo impiegato per determinare se un’espressione è vera o falsa perché produce un codice più efficiente. I vantaggi sono tanto maggiori quanto più in un programma vengono eseguite valutazioni booleane e quanto più queste siano complesse.
6.11
ISTRUZIONE WHILE
|
While.PAS --------------------------------------------------------------- Const
Segreto:Byte=3; Var
digit:Byte; Begin WriteLn(
digita un numero da 1 a 9'); ReadLn(digit); While
digit<>Segreto Do Begin WriteLn(Non
corretto'); ReadLn(digit); End; WriteLn(‘'); End. |
L’implementazione
del ciclo While in codice assembler è:
While: MOV AL,digit
CMP AL,Segreto
JZ End_of_While
..................;implementazione
WriteLn
..................;
e ReadLn
JMP While
End_of_While:
..................
6.12 LA SEMANTICA
DEL FOR
|
For.PAS ---------------------------- Var
N, i : Byte; Sum : Word; Begin ReadLn(N); Sum := 0; For
i:=1 To N Do Sum := Sum + i; WriteLn(Sum); End. |
MOV AL,N
MOV [BP-01],AL ;
MOV AL,1 ;
CMP AL,[BP-01];Espr.iniz>espr.fin.
JA
End_of_For; Si
MOV i,AL ;.
JMP Statement ;For_Loop:
INC i ;
Statement:
MOV AL,i ;Sum=Sum+i
XOR AH,AH
ADD AX,Sum
Sum,AX
MOV AL,i ;
CMP
AL,[BP-01]
JNZ For_Loop ;
End_of_For:
.WriteLn(Sum):
MOV SP,BP
POP BP
XOR AX,AX
CALL End_Proc
Il ciclo
for è equivalente al seguente codice utilizzando la semantica del while:
If espr.iniz. <= espr.fin. Then Begin
i:=espr.iniz;
Corpo;
While
i<>espr.fin. Do Begin
Inc(i);
Corpo;
End;
{ adesso i=espr.fin. }
End;
6.13 ARRAYS
|
ARRAY.PAS ------------------------------- Var v : Array
[1..5] Of Integer; i : Integer; Begin
i := 3;
v[1] := 123;
v[2] := 456;
v[3] := v[1] + v[2];
v[i+1] := v[i] + 5; End. |
Ogni tipo
di dati, sia standard che definito dall’utente, può costituire un array.
La parola
chiave Array definisce quindi un tipo di dato che ripete la sua struttura un
numero di volte prefissato.
Si può
indirizzare uno qualsiasi degli elementi di un array con un numero d’ordine
(indice) piuttosto che con un nome simbolico come si fa con le altre variabili
(o con l’intero array); Gli array sono indispensabili in un linguaggio ad alto
livello.
In linguaggio macchina invece non ci sono array, come non ci sono nomi per le variabili. In linguaggio macchina si può solo accedere ad ogni byte della memoria con il suo indirizzo numerico e quindi gestire sequenze di dati omogenei in memoria (usando i vari metodi di indirizzamento disponibili).
Questo è
esattamente ciò che fa il compilatore
quando utilizza un’ arrays.
|
estratto da ARRAY.MAP --------------------- .................. DS:0050 v DS:005A i .................. |
Come risulta dal MAP file, v occupa 5*2=10 bytes nel segmento dati
.............................
.............................
MOV WORD PTR [0050],007B ;v[1]:=123
MOV WORD PTR [0052],01C8 ;v[2]:=456
;v[3]:=v[1]+v[2]
MOV AX,[0050] ;
AX=v[1]
ADD AX,[0052] ;
AX=AX+v[2]
MOV [0054],AX ; v[3]=AX
;v[i+1]:=v[i]+5;
MOV DI,[005A] ;
DI=i
SHL DI,1 ;
DI=DI*2
MOV AX,[DI+004E] ; AX=[50+i*2-2]=v[i]
ADD AX,0005 ; AX=AX+5
MOV DX,AX ;
DX=v[i]+5
MOV AX,[005A] ;
AX=i
INC AX ;
AX=AX+1
MOV DI,AX ;
DI=i+1
SHL DI,1 ;
DI=DI*2
MOV [DI+004E],DX ; v[i+1]=[50+(i+1)*2-2]=DX
L’indirizzo di un elemento di un array di indice espr è dato dalla formula:
Address = (OFFSET v - Size_Element) + espr *
Size_Element
└───────────────────────┘ └─────────────────┘
costante DI
Il codice calcola espr, quindi DI=espr *
Size_Element, dove Size_Element è una costante e quindi usa l’indirizzamento
Base Relativo: [DI+costante].
6.14 PROCEDURE
|
Procedure1.PAS ---------------------------------------- Procedure Average (First,Second:Integer; Var Result:Integer); Begin Result := (First+Second) Div 2; End; Var
i,j,k:Integer; Begin
{main} i:=2; j:=4; Average(i,j,k); WriteLn(k); End. |
Analisi di una procedura attaverso la sua traduzione assembler:
|
estratto da Procedure1.MAP -------------------------------- Address
Publics by Value 0000:0000 Average 0000:0019 @ .............................. 008B:0052 i 008B:0054 j 008B:0056 k .............................. Program
entry point at 0000:0019 |
Per dare ad un programma una
struttura gerarchica, dove gli strati
più alti operano secondo informazioni
generali e quelli inferiori si occupano
dei dettagli, si usano le procedure. Una
osservazione importante che è da sottolineare risiede nel fatto che nel
linguaggio macchina non esiste la
distinzione tra variabili normali e puntatori, in quanto non c’è
differenza tra indirizzi e numeri.
6.15 FUNCTIONS
Analisi assembler dell’implementazione di una funzione:
|
Function.PAS -------------------------------------------------- Function
Average (First,Second:Integer) : Integer; Begin Average := (First+Second) Div 2; End; Var
i,j,k:Integer; Begin {main} i:=2; j:=4; k:=Average(i,j); WriteLn(k); End. |
|
Procedure
PROC PUSH
BP MOV
BP,SP SUB
SP,2 MOV
AX,[BP+6] ADD
AX,[BP+4] CWD MOV
CX,2 IDIV
CX MOV
[BP-2],AX MOV
AX,[BP-2] MOV
SP,BP POP
BP RET
4 Procedure
ENDP Begin: CALL
Init_Proc PUSH
BP MOV
BP,SP MOV
i,2 MOV
j,4 PUSH
i PUSH
j CALL
Procedure MOV
k,AX .............;WriteLn(k) POP
BP XOR
AX,AX CALL
End_Proc END Begin |
A lato si può vedere la
traduzione in assembler della codice function.pas. Mentre una procedura
produce un effetto la funzione restituisce un valore e questo vale a dire che una procedura è un tipo
di istruzione e una funzione e
considerata come un particolare tipo
di fattore.
6.16 PUNTATORI
L’utilizzo
dei puntatori è forse l’aspetto più delicato del Pascal e quindi del Delphi
infatti uno schema pratico per la visualizzazione dei puntatori è il seguente:

Var p:
integer
P:=Tcreate.Area (oggetto)
P.oggetto=3
P.oggetto=4
La
situazione in memoria è la seguente:
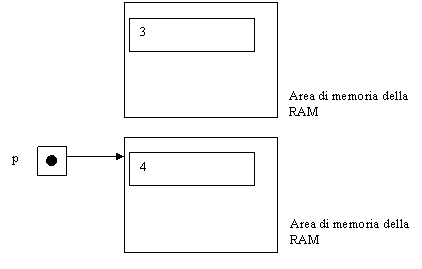
Questo ha
provocato in memoria la creazione di una area che non potrà mai più essere
recuperata dall’esterno attraverso puntatori e nomi di variabili in quanto viene a mancare il riferimento esterno. E’
compito del programmatore evitare questo fenomeno che richiede un metodo di
distruzione delle aree di memoria utilizzate. In Java questo fenomeno non accade.
7
RICERCA DEGLI
ORDINI DI GRANDEZZA
INTRODUZIONE
Questo capitolo di ricerca ha avuto lo scopo di capire quale sia l’ordine
di grandezza in termini di tempo di alcune micro procedure istruzioni. Per fare
questo tipo di analisi ho utilizzato il seguente metodo:
E’
necessario dire come premessa che ogni istruzione assembler è una sequenza di
tre fasi:
-
Fetch (durante la quale l’istruzione è viene prelevata
dalla memoria e trasferita nell’Index register)
-
Decode: decodifica l’istruzione
-
Execute: l’esecuzione
La fase di
fecth corrisponde ad un ciclo macchina; l’esecuzione completa delle tre fasi
richiede da 1 a 5 cicli macchina.
Ogni ciclo
macchina è implementato mediante una
successione di stati interni.
Un
processore 466 Mhz fissa il suo stato interno a 2.14 hs quindi una micro
istruzione come mov si traduce in termini di tempo in 2.14hs×5=10.73hs.
In termini
prestazionali paragonando tale processore, di ultima generazione ad un altro,
appartenente ormai alla storia, 8088 con 2MHz di clock interno avevamo 500hs quindi per eseguire la
stessa istruzione impiegava 500hs×5=2.5mS.
Tutti i
compilatori di linguaggio ad alto
livello producono in maniera più o meno snella una traduzione delle
istruzioni assembler.
In questa
sezione si è tentato di stabilire in maniera quantitativa il tempo di processo
teorico della cpu di quelle che vengono
definite microprocedure.
L’analisi è stata fatta sull’erede del turbo Pascal 7.0, il Delphi.
7.1 METODOLOGIA
Su una form
è stato creato l’oggetto Tbutton e ad
esso è stata associata la microprocedura di
analisi.
Successivamente
il programma è stato compilato; e con un decompilatore assembler sono stati
analizzati i frammenti di codici assembler.
All’interno
delle varie procedure scritte in Pascal sono stati inseriti dei comandi che
permettono di individuare all’interno dell’assembly il codice assembler
analizzato. L’artifizio, basato sull’inserimento dell’istruzione inline($90/$90/$90/) introduce in
assembler la funzione nop (no
operation); essendo poco probabile trovare all’interno di un codice assembler
tre operazioni nulle consecutive. Con un dissassemblatore si è poi proceduto
all’analisi del codice macchina.
7.2 ASSEGNAZIONE DI VARIABILI E LORO
INCREMENTO
CALL FAR PTR Module KEYBOARD Ordinal 9862 SUB SP,
4 NOP NOP MOV WORD PTR [BP-2], 0002H NOP NOP NOP MOV AX, WORD PTR [BP-2] ADD AX, 0003H MOV WORD PTR [BP-4], AX LEAVE RETF 0008H
La procedura fatta da TButton è:
NOP
procedure TForm1.Button1Click(Sender: TObject);
var
i,j:integer;
begin
inline($90/$90/$90);
i:=2;
inline($90/$90/$90);
j:=i+3;
end;
È
possibile, in via approssimata valutare l’ordine di grandezza della velocità di
esecuzione della procedura attraverso i seguenti calcoli
Con
riferimento alla tabella assembler in appendice l’istruzione call richiede 17
stati macchina, prendendo come esempio un processore 466MHz con uno stato che vale 2.14hS abbiamo :
CALL FAR PTR Module KEYBOARD Ordinal
9862
2.14×17=36.48hs
L’istruzione
sub necessita di 7 stati interni
SUB SP, 4
2.14hs×7=15.02hs
Le tre
istruzioni mov che operano lo spostamento da memoria a registro 7 stati:
MOV WORD
PTR [BP-2], 0002H
2.14hs×7=15.02hs
Mentre
sempre le due istruzioni mov che effettuano lo spostamento da registro a registro:
MOV AX,
WORD PTR [BP-2]
MOV WORD PTR [BP-4], AX
2.14hs×5×2=21.46hs
L’istruzione
add che opera la transizione da memoria ram nel accumulatore ax abbisogna di 7
stati
ADD AX, 0003H
2.14hs×7=15.02hs
L’istruzione
ret return che
rilascia lo stack a puntare il
program counter impiega 10 stati
CALL FAR PTR Module KEYBOARD
Ordinal 9862 SUB SP, 12 MOV WORD PTR [BP-2], 0001H MOV WORD PTR [BP-4], 0002H MOV WORD PTR [BP-6], 0005H MOV WORD PTR [BP-8], 0003H MOV WORD PTR [BP-12], 0003H NOP NOP L0178H: NOP MOV AX, WORD PTR [BP-6] ADD AX, WORD PTR [BP-8] MOV DX, AX MOV AX, WORD PTR [BP-2] ADD AX, WORD PTR [BP-4] L0187H: MUL DX ADD AX, WORD PTR [BP-12] MOV WORD PTR [BP-2], AX NOP NOP NOP LEAVE RETF 0008H
RETF 0008H
2.14hs×10=21.46hs
In totale
per la nostra procedura di assegnazione
delle variabili un tempo teorico abbiamo
impiegato
un tempo di 124.5hS per il processo.
7.3 CALCOLO MATEMATICO
procedure TForm1.Button1Click(Sender:
TObject);
var a,b,c,d,e,f: integer;
begin
a:=1;b:=2;c:=5;d:=3;f:=3;
inline($90/$90/$90);
a:=(a+b)*(c+d)+f;
inline($90/$90/$90);
end;
end.
Eseguendo in maniera analoga alla precedente, l’analisi della procedura
possiamo affermare che:
Le cinque istruzioni mov da memoria a registro necessitano di un tempo di
processo di
2.14hs ×7×5=75.11hs
Le quattro istruzioni mov da registro a registro
2.14hs ×5×4=42.92hs
L’istruzioni add
2.14hs ×4×2=17.17hs
l’istruzione mul
2.14hs ×4=8.58hs
l’istruzione ret
2.14hs ×10=21.46h
Se teniamo conto delle sei istruzione nop
2.14hs ×4×6=51.50hs
In totale abbiamo che il processore lavora per un tempo di 216hs.
CALL FAR PTR Module KEYBOARD Ordinal 9862 SUB SP, 6 NOP NOP NOP MOV WORD PTR [BP-2], 0001H MOV WORD PTR [BP-4], 0002H MOV WORD PTR [BP-6], 0003H MOV AX, WORD PTR [BP-2] CMP AX, WORD PTR [BP-6] JGE L017DH MOV AX, WORD PTR [BP-6] MOV WORD PTR [BP-2], AX L017DH: NOP NOP NOP LEAVE RETF 0008H
7.4 IF… THEN…
procedure TForm1.Button1Click(Sender: TObject);
var
a,b,c:integer;
begin
inline($90/$90/$90);
a:=1; b:=2;c:=3;
if a<c then
a:=c;
inline($90/$90/$90);
end;
Il tempo
teorico calcolato è: 79.18hs
7.5 IF… THEN… (ANNIDATI)
procedure
TForm1.Button1Click(Sender: TObject);
CALL FAR PTR Module KEYBOARD Ordinal 9862 SUB SP, 6 NOP NOP NOP MOV WORD PTR [BP-2], 0001H MOV WORD PTR [BP-4], 0002H MOV WORD PTR [BP-6], 0003H MOV AX, WORD PTR [BP-2] CMP AX, WORD PTR [BP-6] JGE L017DH MOV AX, WORD PTR [BP-6] MOV WORD PTR [BP-2], AX L017DH: NOP NOP NOP MOV AX, WORD PTR [BP-2] CMP AX, WORD PTR [BP-4] JGE L018EH MOV AX, WORD PTR [BP-6] MOV WORD PTR [BP-4], AX L018EH: NOP NOP NOP LEAVE RETF 0008H
var
a,b,c:integer;
begin
inline($90/$90/$90);
a:=1; b:=2;c:=3;
if a<c then a:=c;
inline($90/$90/$90);
if a<b then b:=c;
inline($90/$90/$90);
end;
Il tempo teorico totale risultante è:147.7hs
7.6 IF… THEN …ELSE…
procedure TForm1.Button1Click(Sender:
TObject);
CALL FAR PTR Module KEYBOARD Ordinal 9862 SUB SP, 6 NOP NOP NOP MOV WORD PTR [BP-2], 0001H MOV WORD PTR [BP-4], 0002H MOV WORD PTR [BP-6], 0003H MOV AX, WORD PTR [BP-2] CMP AX, WORD PTR [BP-6] JGE L017FH MOV AX, WORD PTR [BP-6] MOV WORD PTR [BP-2], AX JMP SHORT L0185H L017FH: MOV AX, WORD PTR [BP-4] MOV WORD PTR [BP-2], AX L0185H: NOP NOP L0187H: NOP LEAVE RETF 0008H
var
a,b,c:integer;
begin
inline($90/$90/$90) ;
a:=1; b:=2;c:=3;
if a<c then
a:=c
else
a:=b ;
inline($90/$90/$90) ;
end;
Il tempo teorico totale:102.7hs
WORD PTR [BP-4], 0001H MOV WORD PTR [BP-2], 0000H JMP SHORT L0174H L016CH: ADD WORD PTR [BP-4], 1 ADC WORD PTR [BP-2], 0 L0174H: MOV AX, WORD PTR [BP-4] MOV DX, WORD PTR [BP-2] ADD AX, 0003H ADC DX, 0 MOV WORD PTR [BP-8], AX MOV WORD PTR [BP-6], DX CMP WORD PTR [BP-2], 15 L018AH: JNZ L016CH CMP WORD PTR [BP-4], 4240H JNZ L016CH
7.7
CICLO FOR… NEXT
procedure Test;
var
i, j: integer;
begin
j := 0;
for i
:= 1 to 1000000 do
j :=
j + 2;
end;
il tempo teorico è: 130.5hs
7.8 TABELLA RIASSUNTIVA
uesto studio ha permesso di stabilire l’ordine di grandezza
e il tipo di risoluzione che lo strumento di Bench-Mark deve essere in grado di monitorare.
|
Gruppo di istruzioni |
Tempo di processo |
|
Calcolo
Matematico |
216hs |
|
If… then… |
79.18hs |
|
If… then…
(annidati) |
147.7hs |
|
If…
then…else |
102.7hs |
|
Ciclo for… next |
130.5hs |
Questo studio ha permesso di stabilire l’ordine di grandezza
e il tipo di risoluzione che lo strumento di Bench-Mark deve essere in grado di monitorare.
8
ALGORITMI
INTRODUZIONE
Il termine algoritmo, che significa procedimento di calcolo, è una versione moderna del termine latino medievale agorismus, che deriva dal matematico usbeco Mohammed Ibn-Musa al-Khowarismi, vissuto nel IX secolo d.C.
Con tale termine si vuole indicare una descrizione precisa di azioni che un esecutore deve compiere per giungere ad una soluzione di un problema computazionale.
Ingresso Uscita Algoritmo
![]()
![]() In
altre parole l’algoritmo descrive la sequenza di azioni da eseguire per
ottenere l’uscita desiderata partendo
dall’ingresso.
In
altre parole l’algoritmo descrive la sequenza di azioni da eseguire per
ottenere l’uscita desiderata partendo
dall’ingresso.
L’algoritmo per giungere ad una soluzione ha bisogno di elaborare organizzare e rappresentare dei dati.
Si viene a creare quindi lo stretto legame inscindibile tra algoritmi e dati.
Le azioni elementari che risiedono all’interno di un algoritmo devono produrre dei risultati aventi le seguenti caratteristiche:
- tempo limitato;
- risultato certo;
- risultato unico;
- risultato ripetibile.
Se viene ripetuta la stessa azione su un dato deve riproporsi sempre lo stesso risultato.
Le azioni devono essere comprensibili ed eseguibili senza ambiguità alcuna.
Le azioni elementari di un algoritmo e i diversi livelli di dettaglio dipendono dalla capacità dell’esecutore; quando l’esecutore è un computer è necessario introdurre moltissimi dettagli.
Un elaboratore più o meno complesso, è un esecutore di algoritmi espressi in sequenze di bit.
Fortunatamente non è necessario conoscere in dettaglio il funzionamento di una macchina elaboratrice, ma si possono utilizzare costrutti tipici dei linguaggi ad alto livello.
Tali costrutti sono espressi, come visto in precedenza, in una forma intermedia tra il linguaggio discorsivo degli esseri umani, che spesso ha un significato ambiguo, e il linguaggio macchina, che non ha ambiguità, ma risulta per contro essere troppo tecnico.
I costrutti dei linguaggi di programmazione permettono concisione e chiarezza e hanno carattere di universalità, cioè non dipendono dall’Hardware, ma possono essere tradotti automaticamente da altri algoritmi, detti compilatori in sequenze di bit.
Un algoritmo descritto per mezzo di costrutti tipici del linguaggio di programmazione è comunemente detto procedura.
Una procedura permette di definire un algoritmo una volta per tutte, cioè di poterlo individuare attraverso un nome e di poterlo utilizzare più volte con valori distinti, purché consistenti con i dati del problema. Tutto questo produce i seguenti vantaggi:
1 - si evita di scrivere più volte un algoritmo per effettuare la computazione dei dati con valori di tipo diverso.
2 - si sviluppano algoritmi a complessità graduale, scrivendo prima le procedure elementari e successivamente procedure con complessità maggiore che utilizzano quelle elementari trattandole come istruzioni elementari.
In questo modo, una procedura A per la soluzione di un problema P può richiamare al suo interno una procedura B che risolve il problema Q che a sua volta può chiamare la procedura C che risolva il problema R e così via fino ad un arbitrario numero di dettaglio.
Il meccanismo di chiamata alla procedura può essere anche ricorsivo, nel senso che una procedura può chiamare se stessa dal suo interno.
Prendendo come riferimento il Pascal per la sua praticità di studio possiamo dire che i dati primitivi sono: reali, interi, booleani, stringhe e puntatori.
Per risolvere un problema sono spesso disponibili molte soluzioni con algoritmi diversi. Come scegliere la migliore? Un criterio generalmente adottato consiste nel valutare la bontà di un algoritmo in base alla quantità di risorsa tempo utilizzata per il calcolo.
La risorsa di interesse dominante è il tempo, anche se non meno importante è lo spazio necessario per immagazzinare e manipolare i dati.
Nella valutazione del tempo di calcolo di una procedura è in generale difficile quantificare con esattezza il numero di operazioni elementari eseguite. Questa difficoltà viene aggirata valutando l’ordine di grandezza del numero di operazioni.
Per stabilire la complessità di un algoritmo si studia l’ordine di grandezza del numero di operazioni elementari eseguite nel caso peggiore o medio in funzione della dimensione e della tipologia dei dati.
In generale si dice che l’algoritmo è efficiente se la complessità è di ordine polinomiale è inefficiente se ha complessità superpolinomiale.
8.1 ORDINAMENTI
L’importanza
dell’analisi degli algoritmi di ordinamento risiede nel fatto che i processi di
ordinamento coinvolgono un vasto insieme di variabili, quali: l’uso delle
strutture dati, la scelta del tipo di struttura dei dati, infatti queste
possono influenzare l’efficienza dell’ordinamento.
DEFINIZIONE: Per ordinamento si intende il processo di disposizione di un insieme di
oggetti secondo un ordine specifico.
Uno degli
scopi dell’ordinamento è agevolare la ricerca di elementi nell’insieme
ordinato.
Si tratta
di una attività fondamentale, che viene eseguita universalmente in tutti i
settori.
Introduciamo
il problema attraverso una minima terminologia matematica, fondamentale per
studiare i processi di ordinamento:
sia dato
l’insieme non ordinato
a1, a2, a3, …. , an
ordinare significa
permutare gli elementi dell’insieme secondo un ordine
ak1,…akn
tale che
data una funzione di ordinamento f sia
![]()
La funzione
di ordinamento non viene applicata in modo diretto, ma viene memorizzata e
confrontata come una componente esplicita (campo) per ogni elemento attraverso
la struttura a record, particolarmente adatta a rappresentare gli elementi ai.
Il suo valore viene chiamato chiave dell’elemento.
Per studiare
la funzione di ordinamento occorre individuare dei parametri che valutino delle
importanti caratteristiche di stabilità ed efficienza così definite:
DEFINIZIONE: Un metodo di ordinamento si dice stabile se mantiene inalterato l’ordine relativo degli elementi aventi
chiavi o campi uguali.
La
stabilità di un ordinamento è spesso desiderabile.
DEFINIZIONE: Un ordinamento è efficiente se il
numero delle permutazioni è minimo.
C ed M sono i parametri fondamentali per stabilire l’efficienza di un algoritmo.
DEFINIZIONE: C è il numero di confronti necessario per ordinare gli elementi di un
insieme.
DEFINIZIONE: M è il numero di scambi necessari
per effettuare l’ordinamento
A livello teorico una buona misura di efficienza si ottiene contando i numeri di confronti C tra chiavi necessarie e il numero di movimenti M di elementi; queste due quantità sono funzioni del numero n di elementi da ordinare.
I metodi
per ordinare i dati vengono generalmente classificati in due categorie:
-
ordinamento di array o matriciale;
-
ordinamento di file sequenziali.
I metodi di
ordinamento di array hanno l’obbligo principale di usare in forma economica e
ottimale la memoria (sia statica che dinamica) di un elaboratore.
La
permutazione degli elementi, che mette in ordine gli stessi, deve essere
eseguita sul posto e i metodi che trasportano gli elementi da una array
sorgente a una array di destinazione sono trascurabili.
Solitamente i buoni algoritmi di ordinamento richiedono un C = n · log n.
I metodi di ordinamento più semplici sono i metodi di ordinamento definiti diretti, solitamente sono importanti a scopo didattico perché:
1. i metodi diretti illustrano tutte le caratteristiche dei maggiori sistemi di ordinamento;
2. i programmi che sviluppano sistemi di ordinamento diretti sono facili da comprendere
e occupano poco spazio in memoria;
3. i metodi più sofisticati di ordinamento richiedono meno operazioni dei metodi diretti, questo produce come conseguenza che i metodi diretti sono più rapidi per n abbastanza piccoli e non devono essere considerati quando l’insieme da ordinare diventa troppo grande.
I metodi
diretti richiedono un C=![]()
Esiste una classificazione dei metodi a seconda del
tipo di memoria usata per l’ordinamento:
Ordinamento interno i dati della matrice avvengono nella memoria dinamica RAM (Random Access Memory).
Ordinamento esterno tutta la procedura di ordinamento utilizza file residenti nelle varie memorie di massa, che sono più lente ma più capienti.
8.2 QUICKSORT
Quicksort è fondato sul principio che l’efficienza aumenta effettuando il numero di scambi, ancor più se applicato su records o vettori di maggiori dimensioni.
Supponiamo
di avere un vettore di n elementi.
Scegliamo
un elemento a caso x (pivot) e percorriamo il vettore partendo da sinistra fino
un elemento ai>x, e poi da destra, fino a trovare un elemento aj<x.
Scambiamo i due elementi e continuiamo il processo di scansione e scambio fino
a quando le due scansioni si incontrino in un punto interno all’array. Ne risulterà
una partizione dell’array in due parti quella destra con chiavi minori di x e
quella sinistra con elementi con chiavi minori di x.
Questo algoritmo di partizione lo possiamo scrivere in Pascal come riportato nel seguente listato:
procedure QuickSort(var a: array of Integer; iLo, iHi: Integer);
var
Lo, Hi, Mid, T: Integer;
begin
Lo := iLo;
Hi := iHi;
Mid := a[(Lo + Hi) div 2];
repeat
while a[Lo] < Mid do Inc(Lo);
while a[Hi] > Mid do Dec(Hi);
if Lo <= Hi then
begin
T := a[Lo];
a[Lo] :=
a[Hi];
a[Hi] := T;
Inc(Lo);
Dec(Hi);
end;
until Lo > Hi;
if
Hi > iLo then QuickSort(a, iLo,
Hi);
if
Lo < iHi then QuickSort(a, Lo,
iHi);
ad esempio
con un vettore:
44 55 12 42
94 06 18 67
con due
scambi verrebbe così trasformato:
18 06 12 42
94 55 44 67
i valori
finali degli indici sarebbero Hi=5 e
Lo=3.
Le chiavi ai…ai-1 sono
minori di x=42, mentre le chiavi aj+1…an sarebbero
maggiori o uguali a 42 (pivot).
Di
conseguenza esistono due partizioni, partizione destra e partizione sinistra.
L’efficienza
di questo algoritmo è basata sul fatto che i comparandi i, j e x possono essere mantenuti tutti in
registri veloci per tutta la durata della scansione.
L’efficienza
di questo metodo è messa in discussione nel caso di n elementi pivot uguali che comporterebbero n/2 scambi inutili.
Tali scambi
potrebbero essere eliminati introducendo invece della comparazione < e > quella ![]()
![]() tuttavia questo
introduce come inconveniente che l’elemento x
non fungerebbe più da sentinella per le scansioni. Nelle condizioni peggiori in
cui tutti gli elementi sono uguali le scansioni supererebbero i limiti
dell’array e quindi si dovrebbero introdurre ulteriori procedure di
terminazioni più complesse.
tuttavia questo
introduce come inconveniente che l’elemento x
non fungerebbe più da sentinella per le scansioni. Nelle condizioni peggiori in
cui tutti gli elementi sono uguali le scansioni supererebbero i limiti
dell’array e quindi si dovrebbero introdurre ulteriori procedure di
terminazioni più complesse.
Statisticamente
la probabilità di effettuare ordinamenti con n chiavi uguali oltre a non avere
riscontri pratici è abbastanza bassa, ciò compensa largamente il numero di
scambi inutili.
Un modesto
risparmio di scambi lo si può ottenere introducendo una clausola che controlla
lo scambio ponendo i<j invece di i<=j.
8.2.1 Analisi Di Quicksort
Per poter
analizzare le prestazioni del quicksort, è necessario esaminare il
comportamento del processo di partizione. Questo processo richiede esattamente n operazioni di confronto, la scansione
completa del vettore avviene dopo aver selezionato la chiave x.
La
valutazione del numero di scambi necessita un approccio di tipo probabilistico.
Per ipotesi
assumiamo un insieme di dati che deve essere partizionato. Esso consiste in n elementi e supponiamo anche che sia stato scelto un
elemento pivotale x come limite.
Dopo che è
stato effettuato il processo di partizionamento x occuperà la x-esima
posizione all’interno dell’array. Il numero di scambi necessari
sarà uguale al numero di elementi della partizione sinistra moltiplicato
per la probabilità di scambio di una chiave. Una chiave viene scambiata se è
minore di x con una probabilità di (n-x-+1)/n. Il valore atteso di scambi M
può essere ottenuto sommando tutte le possibili scelte del limite x e dividendo per n:
![]()
quindi il
valore atteso del numero di scambi è approssimativamente n/6.
Se l’array
è ben disposta e se si seleziona sempre la mediana in qualità di limite, ogni
processo di partizionamento suddivide il vettore in due metà e il numero di
passi necessari sarà log n. Il numero
totale di confronti sarà n·Log n ed il numero totale di scambi sarà n/6×log n
In realtà non ci si può attendere di scegliere sempre la mediana perché la probabilità di riuscirvi è solo di 1/n
Le
prestazioni del quicksort sono modeste
per piccoli valori di n.
Inoltre
esiste una particolarità che in sostanza è il punto debole dell’algoritmo
ovvero consiste nel caso in cui x scelto a caso sia il massimo della
partizione, ad ogni passo dell’ordinamento l’algoritmo dividerà gli n elementi
in una partizione sinistra composta da n-1
elementi ed una partizione destra composta da un solo elemento. Saranno
necessarie quindi n suddivisioni,
invece che log n, e la prestazione
sarà dell’ordine di n2.
La
selezione dell’elemento pivot è cruciale per il quicksort.
Nel codice
Pascal utilizzato è stato scelta la chiave di mezzo dell’array, si sarebbe
potuto scegliere il primo o l’ultimo elemento e in questo ultimo caso la
situazione peggiore sarebbe stata costituita da un vettore inizialmente
ordinato.
La scelta
dell’elemento di mezzo non è casuale ma proviene da una valutazione statistica,
infatti la prestazione media migliora leggermente scegliendo l’elemento di
mezzo. Alcuni testi di ricerca operativa consigliano di prendere x a caso.
8.2.2 Stime di complessità su ordinamenti
Le
prestazioni degli algoritmi possono essere confrontate con diversi metodi. Uno
di questi consiste semplicemente nell’eseguire molti test per ogni algoritmo e
nel confrontarne i tempi di esecuzione misurati. Un altro modo è stimare il
tempo richiesto. Per esempio, possiamo affermare che il tempo di ricerca è T(n). Questo significa che il tempo di
ricerca, all’aumentare di n, è
proporzionale al numero di elementi n
nella lista, di conseguenza ci aspettiamo che il tempo di ricerca risulti
triplicato se la dimensione della lista aumenta di un fattore tre. La notazione
T-grande non descrive il tempo esatto richiesto da un algoritmo, ma indica solo
un limite superiore al tempo di esecuzione, entro un fattore costante. Se un
algoritmo richiede T(n2)
tempo, allora il suo tempo di esecuzione non cresce più del quadrato della
dimensione della lista.
Tabella 1:
Fattori di crescita
|
n |
lg n |
n lg n |
n1.25 |
n2 |
|
1 |
0 |
0 |
1 |
1 |
|
16 |
4 |
64 |
32 |
256 |
|
256 |
8 |
2.048 |
1.024 |
65.536 |
|
4.096 |
12 |
49.152 |
32.768 |
16.777.216 |
|
65.536 |
16 |
1.048.565 |
1.048.476 |
4.294.967.296 |
|
1.048.476 |
20 |
20.969.520 |
33.554.432 |
1.099.301.922.576 |
|
16.775.616 |
24 |
402.614.784 |
1.073.613.825 |
281.421.292.179.456 |
La
tabella illustra i valori con cui
crescono le varie funzioni. Un fattore di crescita T(lg n) si ha per gli algoritmi simili alla ricerca binaria. La funzione
lg
cresce di uno quando n
raddoppia. Con la ricerca binaria, è possibile ricercare fra il doppio dei
valori con un confronto in più. Pertanto la ricerca binaria è un algoritmo di
complessità T(lg n).
Se i valori
nella tabella 1 rappresentano microsecondi, allora un algoritmo T(lg n) può impiegare 20 microsecondi per
processare 1.048.476 elementi, un algoritmo T(n1.25) può impiegare 33 secondi e un algoritmo T(n2) può impiegare fino a 12
giorni
8.3 ZAINO
Dati un
insieme di n oggetti con n profitti {p1,…,pn} e volumi {v1,…,vn}, tutti
interi positivi il problema dello zaino consiste nello scegliere oggetti in
modo da minimizzare il profitto degli oggetti scelti senza superare la capacità
dello zaino, ovvero determinare un insieme{x1,…,xn} di reali
compresi tra 0 e 1 tali che:
![]() sia massima e
sia massima e ![]()
![]()
si assume
che i profitti siano memorizzati nei vettori p[1..n] e v[1..n].
La prima
fase consiste nell’ordinare il vettore rapporto tra profitti/volumi in maniera decrescente.
Nella
seconda fase si cerca di scegliere la porzione più grande possibile
dell’oggetto che dà il maggior profitto per unità di volume, senza superare la
capacità c. Una volta effettuata la
scelta si deve aggiornare c, la
capacità dello zaino precedente meno la porzione di spazio occupato dal nuovo
elemento. Se lo zaino non è riempito, allora si ripete il procedimento col
secondo oggetto che dà maggior profitto per unità di volume, effettuando così
una ricorsione della procedura aggiornando ad ogni iterazione la capacità
residua.
Alla fine saranno scelti per intero gli oggetti più appetibili. La complessità di questo algoritmo richiede un tempo di Q(nlogn).
La sua notazione in Pascal è la seguente:
Procedure Zaino(var
p,v: array of integer ;c:integer ;x:array of real );
var i:integer;
begin
for i:= 1 to n do x[i]:=0;
i:=1;
while(i<=4) and (c>=0) do begin
if v[i]>=c then begin x[i]:=c/v[i]; c:=0; end
else begin x[i]:=1; c:=c-v[i]; end;
i:=i+1;
end;
8.4 MOLTIPLICAZIONE TRA MATRICI
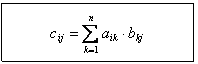 Tra le prove di bench-mark è stato valutato il problema di moltiplicare
tra loro due matrici quadrate nxn A=[aij] e B=[bij]. Per definizione,
la matrice prodotto C=A·B ha il generico elemento:
Tra le prove di bench-mark è stato valutato il problema di moltiplicare
tra loro due matrici quadrate nxn A=[aij] e B=[bij]. Per definizione,
la matrice prodotto C=A·B ha il generico elemento:
per ![]() ed
ed![]() il problema può essere risolto attraverso il seguente
algoritmo in Pascal.
il problema può essere risolto attraverso il seguente
algoritmo in Pascal.
For i:=1 to n do
For j:=1 to n do begin
C[i,j]:=0;
For k:=1 to n do
C[i,j]:=C[i,j]+A[i,k]·B[k,j];
end;
Questo
algoritmo ha complessità Q(n3).
8.5 METODO DI TRIANGOLARIZZAZIONE DI UNA MATRICE QUADRATA
L’algoritmo
matematico per la triangolarizzazione di matrici quadrate per le prove di
bench-mark utilizzato nel presente lavoro è il metodo di Crout. Con riferimento a un altro metodo di
triangolarizzazione quello di Gauss-Sidel, il metodo di Crout è più diffuso e per certi aspetti più pratico.
In questa sede è importante prendere in considerazione la notevole differenza di
triangolarizzazione dei due metodi:
quella con il metodo di Crout giunge
come risultato a una triangolare superiore che non possiede nessun legame con
la matrice d’origine, mentre il metodo di Gauss giunge alla
triangolarizzazione mantenendo il significato
fisico della matrice di partenza. In sostanza significa che se abbiamo un
sistema lineare con n equazioni in n
incognite triangolarizzazione con il
metodo di Gauss giunge ad una matrice
triangolare superiore le cui soluzione sono ancora soluzioni del sistema
d’origine mentre con il metodo di Crout le soluzioni della matrice triangolare
non corrispondono a quelle della matrice di partenza. Questo fatto diventa molto importante qualora si calcoli
il determinate, l’inversa e le soluzioni
di un sistema lineare in maniera
software, in quanto la triangolarizzazzione con il metodo di Crout
presuppone un metodo di memorizzazione del sistema di partenza. L’algoritmo in
Pascal è il seguente:
for J := 1 To N do //
metodo di Crouts'
begin
for
I := 1 To J - 1 do
begin
sum :=
a[I, J];
for K := 1 To I -
1 do
sum := sum - a[I, K] * a[K,
J];
// Next K
a[I, J] :=
sum ;
end;
//Next I
aamax := 0; //Inizia la ricerca del pivot'
for I := J To N do
begin
sum := a[I, J];
for K := 1 To J - 1 do
sum := sum - a[I, K] * a[K,
J];
//Next K
a[I, J] :=
sum;
dum := vv[I] * Abs(sum);
if (dum >= aamax) Then
begin
IMax :=
I;
aamax :=
dum; // è il più grande di vv(i)*abs(sum)'
end;
end;
//Next I
if (J <> IMax) then
begin
for K := 1 To N do
begin
dum :=
a[IMax, K];
a[IMax, K] := a[J, K];
a[J, K] := dum;
end; //Next K
d := -d;
vv[IMax]
:= vv[J]
end; //
End If
//Indx[J] :=
IMax;
if (a[J, J] = 0) then
a[J, J] :=
tiny;
if (J <> N) then
dum := 1 / a[J, J];
for I := Succ(J) to N do
a[I, J] := a[I, J] * dum;
//Next I
end;
8.6 CALCOLO DEL DETERMINANTE
Una possibile applicazione della triangolarizzazione di una matrice è il calcolo del determinante. Le procedure di calcolo automatico del determinante si articolano in due fasi:
1 -
consiste nel triangolarizzare la matrice con il metodo di Crout o Gauss;
2 -
effettuare il prodotto degli elementi della diagonale principale della matrice
triangolarizzata.
L’algoritmo
di questa seconda parte può essere
esemplificato nella seguente forma:
function
Determinante(var a: TArray): double;
var
d: integer;
i: integer;
begin
Ttriang(a, d, MaxArray);
Result := d;
for i := 1 to MaxArray do
Result := Result * a[i, i]: end.
Dove la matrice passata alla funzione determinate è una triangolare superiore di dimensione n x n.
8.7 NUMERI CASUALI
Il riferimento a questo paragrafo verte sul fatto che per le prove di bench-mark si sono utilizzati dei generatori di numeri casuali. Tali numeri sono utili sia nel progetto di algoritmi che per generare file di input al fine di provare sperimentalmente il comportamento degli stessi.
Un numero casuale è un numero che ha una certa probabilità di essere estratto all’interno di un dato intervallo di variabilità. Si considera probabilità uniforme la caratteristica di ciascun numero di essere estratto con la stessa probabilità di uscire di tutti gli altri.
Sulla generazione di numeri casuali e sui relativi test di casualità esiste un’ampia bibliografia, una loro trattazione più specifica esula dall’argomento principale oggetto del presente lavoro.
9
CONCLUSIONI E RISULTATI
9.1 ASPETTO ECONOMICO
Agli inizi
degli anni ’80 il numero di persone addette
allo sviluppo del software negli USA erano circa 1 milione e i costi del
software erano di circa 40
milioni di dollari (circa il 2% del PNL Americano). Questi costi sono andati
crescendo nel decennio di circa il 12 % l’anno,
con una crescita del personale di circa il 7% l’anno.
Nel 1988 le
dimensioni economiche del settore informatico italiano ammontavano di circa
7000 miliardi (con un incremento di oltre 20% rispetto all’anno precedente).
All’interno di tale mercato, il software e i servizi di informatica coprivano
circa l’80% del mercato globale.
Accanto
alla domanda esplicita di software esiste un fenomeno importante da considerare
la domanda nascosta ed inevasa cioè il Backlog, visibile nei ritardi che si
manifestano tra il momento nel quale
sorge la richiesta di una applicazione ed il momento in cui tale richiesta è
soddisfatta.
Secondo
l’Aeronautica militare Americana il fenomeno è quantificabile in un ritardo di
circa 4 anni, e i ritardi
in ambito civile di 2-3 anni
I
motivi sono:
-
carenza del personale dovuta all’incapacità delle
strutture informative di produrre un
numero adeguato di specialisti;
-
personale esistente poco
specializzato.
L’attuale
mercato misura la produttività e la competitività delle industrie e delle
società di servizi dal loro livello di
informatizzazione.
Ci si trova di fronte ad un fenomeno di
crescita del mercato del software in maniera esponenziale. Ma come il mercato
del software è in grado di
rispondere a questa crescita?
Non certo
con una altrettanta crescita della produttività e della qualità dei propri prodotti.
Se
confrontiamo il mercato Software con il mercato Hardware si rileva una
progressiva riduzione dei costi e un continuo miglioramento delle prestazioni.
La tabella
seguente riporta il rapporto tra costi Hardware e costi Software in funzione
del tempo. La figura mette in evidenza come nel corso degli anni il problema si sia completamente ribaltato.
I motivi di
ciò risiedono nella dimensione dei prodotti Hardware impiegati nell’automazione
dei processi produttivi.
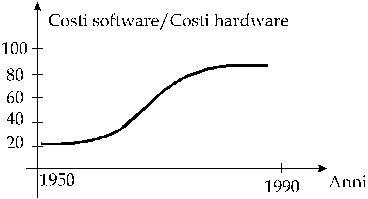
L’aspetto
di rilievo non è tanto dovuto a un lento progresso nello sviluppo tecnologico
del software, quanto al progresso estremamente veloce nello sviluppo
tecnologico dell’hardware. Nessuna altra forma di tecnologia nella storia
dell’umanità ha avuto una crescita di sei ordini di grandezza nel rapporto
prestazioni costi nell’arco di 30 anni.
A fronte di
ciò la produzione Hardware resta prevalentemente una attività di tipo
intellettuale, scarsamente automatizzata. Si tratta in maniera intrinseca di una attività in cui
prevale l’aspetto progettuale, mentre la componente manifatturiera risulta del tutto marginale.
La
produttività del software viene misurata attraverso il numero di linee di
codice prodotte per giorno o per mese da una persona: si considera cioè il
numero totale di righe di codice che costituisce l’applicazione e si divide
per il numero totale di giornate impiegate per l’intero progetto. Attraverso
prove sperimentali questo valore si attesta a 10-30 righe di codice al giorno
anche se la varianza di tale misura risulta altissima.
La
dimensione sociale ha uno spessore di rilievo nell’ambito del sviluppo
software.
L’affidabilità
del software è troppo bassa per le esigenze delle applicazioni.
Basti
pensare a decisioni strategiche prese sulla base di software che produce
risultati erronei nelle applicazioni di gestione di transizioni finanziarie.
Ancora più
critiche quelle applicazioni in cui il mal funzionamento ha riflessi sulla vita
dell’uomo, per esempio il monitoraggio
di pazienti nei reparti di rianimazione degli ospedali, il controllo del volo
degli aerei, sistemi di rilevazione militari.
Quando le
applicazioni possono generare dei rischi è necessario che si ponga ogni
cura nel produrre software
affidabile e che verifichi a posteriori l’effettiva affidabilità.
Come accade
per ogni tipo di prodotto, il software viene sviluppato da un suo processo
produttivo, la cui struttura può avere una forte influenza sulla qualità del
prodotto finale, oltre che sul costo del processo che porta a quel prodotto. Le
prime applicazioni informatiche erano
caratterizzate da una scarsa attenzione ai problemi di organizzazione e
gestione del software. Chi sviluppava software coincideva con l’utente
dell’applicazione: non sviluppava per un cliente o per un mercato, veniva cioè
utilizzato un metodo che gli oltreoceano
hanno definito code and fix, codifica e modifica. Con il crescere della
complessità e criticità delle applicazioni, nonché con il nascere del mercato
del software, questo metodo si è dimostrato del tutto inadatto. Dal punto di
vista gestionale e organizzativo viene
spontaneo da chiedersi quale siano le fasi di produzione
del prodotto.
Come in
qualsiasi processo di produzione industriale la scelta del modello del ciclo di
produzione è dettata da una analisi dei rischi.
Se il
rischio fondamentale è dato dall’affidabilità dell’applicazione, e i requisiti
sono estremamente stabili, allora un ragionevole ciclo di produzione potrebbe
essere del tipo.

In questa
progressione in cascata di fasi, da una fase si procede verso la successiva
nella direzione delle frecce senza tornare verso le fasi precedenti.
Infatti i
ricicli vengono visti come disturbi in quanto rendono il processo difficilmente
controllabile.
Se invece i
rischi fondamentali sono l’incertezza dei requisiti, allora è bene pianificare
un processo iterativo come visualizzato in figura.

L’uscita
intermedia che una fase produce come ingresso per la fase successiva è un
semilavorato di processo; si tratta sostanzialmente di documentazione di
supporto cartaceo. I soli semilavorati formalizzati sono ciò che viene prodotto
dall’attività di programmazione (il codice dei singoli moduli scritto in
qualche linguaggio di programmazione) ed integrazione (il sistema complessivo).
Questo modello di ciclo di produzione oltre a definire le fasi che compongono il prodotto e le attività interne ad ogni fase, si preoccupa di definire il controllo sulla qualità del prodotto, e in fase di pianificazione, la schedulazione dei semilavorati che devono essere prodotti. L’attività di controllo è fondamentale al fine di certificare l’avanzamento del processo secondo un piano stabilito. Se per esempio è previsto che l’attività di progettazione venga completata entro una certa data, è necessario verificare che la documentazione di progetto, cioè il semilavorato previsto in questa fase superi la fase di controllo qualità entro la data prevista.
Il processo di sviluppo del software si differenzia dai processi produttivi di altri settori industriali in quanto l’attività svolta è di tipo prevalentemente progettuale. Questo aspetto deve essere disciplinato in modo che i prodotti sviluppati siano facilmente verificabili, abbiano elevata affidabilità, siano facilmente modificabili e infine offrano le caratteristiche di qualità che godo altri prodotti industriali. A tal fine occorre che i produttori di software definiscano e adottino degli opportuni standard, non facilmente individuabili, che caratterizzino il loro modo di produrre i semilavorati e i prodotti finiti. Ad esempio uno standard può specificare in maniera dettagliata la successione delle fasi di ciclo di produzione, le attività da svolgere in ciascuna fase, le responsabilità delle persone nei diversi centri di lavoro etc.
Ne deriva che un ingegnere gestionale deve essere in grado di comprendere e capire un insieme di tecnologie concrete da impiegare nei processi produttivi, attraverso un insieme di processi rigorosi, che trovano giustificazione nelle basi teoriche.
I metodi e strumenti capaci di calibrare l’aspetto progettuale con il problema specifico da risolvere sono:
- affidabilità: le funzionalità offerte sono corrispondono requisiti. In altre parole, se i risultati calcolati, le elaborazioni effettuate, le azioni eseguite producono gli effetti dovuti;
- correttezza:
data una definizione dei requisiti che
il software deve soddisfare, questo si definisce corretto se i requisiti sono
rispettati;
- robustezza: il software si comporta in maniera accettabile anche in corrispondenza di situazioni non specificate nei requisiti;
- sicurezza: il termine sicurezza deve essere utilizzato in concomitanza con sistemi di accesso di informazioni private e protette, impedendo accessi non autorizzati.
- prestazioni: un programma può essere corretto, affidabile robusto ma può essere inutilizzabile a causa delle sue basse prestazioni, intese come uso inefficiente di alcune importanti risorse, quale il tempo di esecuzione e/o la memoria occupata.
Se per avere certe risposte corrette di sistema l’utente deve aspettare troppo tempo, può accadere che il sistema sia non utilizzabile per il tipo di applicazione.
Malgrado la velocità di esecuzione delle macchine odierne sia largamente superiore a quelle del passato ed il costo della memoria si sia enormemente ridotto, spesso gli elaboratori vengono sfruttati al massimo delle loro possibilità, sicché, paradossalmente, le esigenze di tempo e memoria costituiscono sempre un problema importante per molte classi di applicazioni. Ad esempio, certi algoritmi di simulazione del traffico sulle reti di trasmissione dati o elaborazioni di dati di natura meteorologica richiedono ancora oggi molte ore di tempo-macchina perché possano fornire dei risultati significativi.
Metodi empirici per valutare le prestazioni di un programma è dato dalla teoria della complessità di calcolo che riguarda uno degli argomenti principali della ricerca operativa, e permette di valutare le prestazioni nel caso medio o peggiore, in termini asintotici rispetto ad alcune grandezze tipiche del programma in esame.
Per esempio, dato un programma che ricerca un elemento in una sequenza ordinata di elementi, la valutazione viene fatta attraverso lo studio dell’andamento asintotico del tempo di esecuzione in funzione del numero di elementi che fanno parte della sequenza, nel caso medio e peggiore.
Il calcolo numerico su calcolatori elettronici costituisce uno dei capitoli più ricchi e stimolanti dell’informatica, ed ha portato conseguentemente ad una valutazione accurata della complessità di molti algoritmi fondamentali.
Esistono diversi metodi per valutare le prestazioni di un programma. Uno consiste nel misurare, mediante appositi strumenti software (software monitors), il tempo di esecuzione o l’occupazione in memoria durante esecuzioni-campione del programma. Un altro consiste nell’effettuare misure di tempo non mediante esecuzioni reali ma in ambienti simulati. Un terzo metodo consiste nel costruire il sistema sotto esame e nel dedurre le prestazioni operando in maniera analitica sul modello, ad esempio la teoria delle code mette a disposizione metodi analitici che possono essere impiegati per una analisi di tipo probabilistico.
Questa tesi è rivolta all’analisi delle prestazioni di alcuni compilatori, ed in particolare di alcuni linguaggi di programmazione molto diffusi sul mercato.
9.2 DEFINIZIONE DELL’ANALISI
9.2.2 Approccio
Studio
delle prestazioni di tre linguaggi di programmazione: Microsoft Visual Basic,
Borland Delphi e Java nella risoluzione dello stesso problema reale, attraverso
algoritmi matematici.
9.2.3 Ipotesi iniziali
Le ipotesi iniziali sono:
-
i tipi di dato e le strutture dati fra i tre linguaggi
devono essere uguali e confrontabili;
-
uguaglianza delle procedure di calcolo (algoritmi);
-
interfaccia grafica semplificata;
-
stessa piattaforma hardware per le prove sperimentali
(Celeron 466Mhz, 64Mb di Ram, 6 GB hard
disk, 512 cache memory);
-
sistema operativo Windows 98;
-
linguaggi di programmazione: Microsoft Visual Basic
6.0, Borland Delphi 3.0 e SUN Java 1.2.
9.2.4 Tipologia dei Dati Utilizzati
Un fattore importante già sottolineato nei precedenti capitoli è che ogni linguaggio di programmazione introduce sia strutture che tipi di dato con caratteristiche proprietarie.
I tipi di dato specifici di ciascun linguaggio sono stati discussi nel capitolo 2.
La condizione di uguaglianza o quantomeno similitudine dei tipi di dato per le prove sperimentali si rende strettamente necessaria per poter effettuare dei confronti di prestazione. I tipi numerici utilizzati nei test di bench-mark sono rappresentati nella seguente tabella :
Tipi di dati |
Visual
Basic |
Delphi |
Java |
|
Da -2.147.483.648 a 2.147.483.6477 |
Long |
Integer |
Int |
|
Da -1,79769313486232E308 a |
Double |
Double |
Double |
|
Da 0 a circa 2 miliardi di caratteri. |
String |
String |
String |
9.2.5 Tabella riassuntiva degli algoritmi analizzati
Fissati i
tipi di dato da sottoporre ad analisi, sono stati scelti gli algoritmi in
funzione delle loro caratteristiche matematiche e ai problemi di computazione
che introducevano. La tabella sottostante riporta gli algoritmi trattati e i
tipi di dato su cui sono stati
applicati:
|
|
Interi |
Stringhe |
Double |
|
QuickSort |
* |
* |
* |
|
Triangolarizzazione |
|
|
* |
|
Moltiplicazione tra matrici |
|
|
* |
|
Zaino |
|
|
* |
|
Calcolo del determinante |
|
|
* |
9.2.6 Interfaccia grafica semplificata
Al fine di rendere il bench-mark indipendente dagli appesantimenti introdotti dall’interfaccia grafica, è stata fatta la scelta di semplificare quest’ultima, anche per evitare lo sviluppo di codice che potesse in qualche forma aberrare le prove.
9.2.7 Piattaforma Hardware
Per le prove pratiche è stato utilizzato un PC 466Mhz Celeron 64Mb di ram 6Gb harddisk e 512 Kb cache memory.
Inoltre si sono effettuate alcune delle prove di bench-mark anche su altre piattaforme hardware con diverse caratteristiche, per verifica delle ipotesi iniziali e ulteriore conferma sulla validità del lavoro fatto.
9.3 METODOLOGIA DI ANALISI E RELATIVI PROBLEMI
In un primo
tempo è stata fatta la scelta di monitorare la velocità di esecuzione di un
algoritmo, utilizzando l’oggetto Timer, per Visual Basic e Delphi, e la
funzione currentTimeMillis() per Java.
Gli oggetti
Timer di VB e Delphi, seppur omonimi, all’uso sono risultati oggetti troppo
diversi fra loro, diversità giustificata dal fatto di essere costruiti e implementati
in maniera molto diversa. Entrambi implementano un contatore che utilizza il
Timer di sistema e lo interrogano ad intervalli definiti da una proprietà
impostata dall’utente. In Delphi un oggetto Timer, ed in generale qualunque
oggetto, è parte integrante dell’eseguibile; in Visual Basic invece un oggetto
è contenuto in un file OCX esterno e quindi richiamato, caricato ed eseguito
solo all’occorrenza. Nella pratica delle
misurazioni, è emerso che tali strutture software producevano tempi scarsamente
attendibili; ciò probabilmente a causa delle operazioni in background che il
sistema operativo esegue continuamente nell’amministrazione del sistema.
Java è
dotato di un contatore svincolato dal sistema operativo sottostante: il suo
clock virtuale, interrogato dalla funzione currentTimeMillis() presente nella
classe System, ha dimostrato di avere una risoluzione diversa da Visual Basic e
Delphi, rendendo i risultati non confrontabili.
Si è reso
quindi necessaria la ricerca di un metodo di cronometraggio che fosse il più
stabile possibile. Tali caratteristiche sono ottenibili attraverso funzioni a
basso livello che sono specifiche del sistema operativo Windows:
-
TimePerformanceFrequency
-
TimePerformanceCounter
Queste due
funzioni fanno parte delle API di WIN32 ed interrogano un contatore ad alta
risoluzione presente nel sistema.
La prima
funzione restituisce il valore massimo della frequenza di sensibilità del
sistema: il suo inverso quindi ci fornisce la risoluzione massima del contatore
di macchina. Nel nostro caso il valore restituito è 119821 cicli al secondo.
La seconda
funzione restituisce il numero dei cicli intercorsi dall’accensione del
sistema.
Ecco un
esempio d’uso delle funzione sopraindicate per il cronometraggio di una
procedura denominata genericamente Test():
…
QueryPerformanceFrequency(tl3); //Inzializza il contatore di frequenza
QueryPerformanceCounter(tl1); //inizia conteggio
Test(); //invoca
la funzione interessata
QueryPerformanceCounter(tl2); //fine conteggio
…
All’interno
delle applicazioni di bench-marking sono state
inserite e quindi implementate le
formule di seguito riportate:
![]()
Dove
tl2 = numero di cicli finale
tl1 = numero di cicli iniziale
tl3 = frequenza
Quindi
si è potuto risalire al calcolo del
tempo con una risoluzione di 8,3457·10 –6 secondi, calcolata attraverso il rapporto
implementato negli eseguibili di bench-mark:
![]()
Effettuando
alcune prove di Bench-Marking sono sorti alcuni problemi di natura tecnica per ciascun compilatore.
In Visual
Basic è stato necessario dichiarare, in “dichiarazioni generali” di modulo , le
direttive di chiamata alle funzioni, residenti in due particolari librerie
dinamiche (.dll) di proprietà di Windows residenti nel file Kernel32.dll
presente nella directory WINDOWS\SYSTEM.
Utilizzando
la sintassi:
Public Declare Function
QueryPerformanceCounter Lib "Kernel32" _
(X As Currency) As Boolean
Public Declare Function QueryPerformanceFrequency Lib "Kernel32" _
(X As
Currency) As Boolean
è possibile
richiamare funzioni esterne al linguaggio.
Questo
perché VB è un linguaggio semicompilato, cioè i suoi eseguibili necessitano di
un interprete che è contenuto in vba6.dll. VB soffre comunque di un’altra
limitazione cui abbiamo dovuto tenere conto nella procedura di cronometraggio:
una funzione esterna viene caricata in memoria solo al primo richiamo
esplicito. Ciò introduce un tempo di latenza che è inaccettabile. Per ovviare a
questo inconveniente richiamiamo le funzioni “a vuoto”; con tale artificio si
ottiene il precaricamento in memoria prima di effettuare la misura vera e
propria.
La tecnica
è di seguito esplicitata:
Private Sub Form_Load() (Caricamento della
form)
Call QueryPerformanceFrequency(tlfreq)
'chiama le dll per la prima volta'
Call QueryPerformanceCounter(tl0)
(inizio conteggio)
Call QueryPerformanceCounter(tl1) (fine
conteggio)
End Sub
Delphi non
soffre di questi problemi essendo già nativamente progettato per chiamare
qualunque funzione delle API di Windows.
Java è un linguaggio portabile che deve implementare funzionalità indipendenti dalla piattaforma. Quindi, particolari classi di oggetti e funzioni dipendenti da una specifica piattaforma hardware non sono supportate direttamente dal linguaggio. Per utilizzare delle funzioni del sistema operativo che ospita la Java Virtual Machine, è stata formalizzata una interfaccia chiamata Java Native Interface (JNI), che mette a disposizione del programmatore un insieme di funzioni standard attraverso le quali è possibile effettuare svariate operazioni in codice nativo. La procedura per utilizzare del codice nativo richiede lo sviluppato di una DLL in C++ a partire da un header file generato dalla utility javah fornita dalla SUN. Tale DLL si occupa dell’invocazione del codice nativo (QueryPerformanceFrequency e QueryPerformanceCounter) e provvede un metodo per "passare" i valori rilevati all’ambiente Java. Nel caso specifico le funzioni di interfaccia sono:
/*
* Class:
cputime
* Method:
jQueryPerformanceFrequency
*
Signature: ()J
*/
JNIEXPORT jlong JNICALL
Java_cputime_jQueryPerformanceFrequency
(JNIEnv *,
jclass);
/*
* Class: cputime
* Method: jQueryPerformanceCounter
* Signature:
()J
*/
JNIEXPORT jlong JNICALL Java_cputime_jQueryPerformanceCounter
(JNIEnv
*, jclass);
All’interno
del sorgente Java, richiamo tali funzioni tramite la sintassi
public static native long
jQueryPerformanceFrequency();
public static native long jQueryPerformanceCounter();
in cui si specifica, appunto, che le funzioni sono in codice nativo. In un altro frammento di codice:
static
{
System.loadLibrary("cputime");
}
si informa il compilatore Java quale sia la DLL che contiene il codice nativo.
Dopo questa fase sono state effettuate alcune prove di bench-mark al fine di verificare l’attendibilità delle misure; i risultati hanno dimostrato che due prove consecutive fornivano risultati dissimili, se si procedeva al riavvio del sistema tra una prova e l’altra.
Questo comportamento fa supporre che, al termine di una prova, la RAM rimane alterata e influenza l’esecuzione dei successivi test.
Per ovviare a questo problema, e quindi creare le stesse condizioni di misura, si è scelto il riavvio della macchina prima di ogni prova.
I dati di prova per lo sviluppo dei test sono stati memorizzati in file di input in formato ASCII, salvati in una cartella comune denominata “data”. Questi files sono stati creati da applicativi costruiti per la generazione di valori casuali per i tipi intero, stringa e virgola mobile. In questo modo si è garantita la ripetibilità delle prove.
9.4 RISULTATI
PRATICI DELLE PROVE
9.4.1 Benchmark
quiksort su tipi di dato intero
Gli applicativi utilizzati per questa prova sono statI:
- Il generatore di numeri casuali interi
- L’applicazione di bench-marking
Il generatore di numeri casuali è stato compilato con Visual Basic, e produce un file con nome INTERI.TXT in formato ASCII.
In appendice si riporta il codice sorgente in VB del generatore di numeri casuali interi.
Sempre in appendice sono riportati i sorgenti delle applicazioni nei tre linguaggi.
Per ottenere un metodo chiaro e generale per tutte e tre le piattaforme sono state sviluppate le seguenti procedure:
StartChrono;
StopChrono;
LoadFromFile(FileName: string);
SaveToFile(FileName: string);
QuickSort(var a: array of Integer; iLo, iHi: Integer);
Button1Click(Sender:
TObject);
Le procedure StartChrono e StopChrono hanno la funzione di iniziare e fermare il bench-mark.
La procedura LoadFromFile prende come argomento FileName quest’ultima è una variabile contenente il nome del file di ingresso i questo caso specifico Interi.txt.
SaveToFile in maniera analoga alla precedente salva in maniera automatica il file di output, sortInteri.txt.
La procedura QuickSort contiene l’algoritmo e il metodo buttonClick è il comando che utilizziamo per dare inizio al Bench-mark.
Per ogni numero di elementi si sono eseguite 10 prove ed effettuata la media tra i valori; si sono ottenuti i seguenti risultati:
N° elementi
|
Quicksort su tipo di dati intero |
VisualBasic (ms) |
Delphi (ms) |
Java (ms) |
|
1000 |
7,204 |
0,422 |
4,472 |
|
2000 |
11,309 |
0,722 |
4,949 |
|
3000 |
17,655 |
1,029 |
5,095 |
|
4000 |
23,675 |
1,365 |
5,381 |
|
5000 |
30,145 |
1,707 |
7,135 |
|
6000 |
37,931 |
2,05 |
6,254 |
|
7000 |
45,288 |
2,43 |
6,687 |
|
8000 |
49,884 |
2,672 |
7,048 |
|
9000 |
57,077 |
2,994 |
7,442 |
|
10000 |
68,033 |
3,38 |
8,288 |
|
20000 |
140,401 |
7,172 |
12,004 |
|
30000 |
212,499 |
10,761 |
16,835 |
|
40000 |
322,484 |
16,229 |
22,233 |
|
50000 |
370,502 |
21,925 |
27,849 |
|
60000 |
463,86 |
25,784 |
37,057 |
|
70000 |
594,16 |
32,382 |
40,076 |
|
80000 |
703,374 |
40,419 |
48,277 |
|
90000 |
712,164 |
45,455 |
51,909 |
|
100000 |
850,094 |
55,242 |
66,216 |
|
200000 |
1686,157 |
109,209 |
159,715 |
|
300000 |
2605,505 |
174,863 |
251,217 |
|
400000 |
3637,724 |
253,851 |
298,192 |
|
500000 |
4702,781 |
318,06 |
421,768 |
Quicksort su tipo di
dato intero N° Elementi Log Tempo
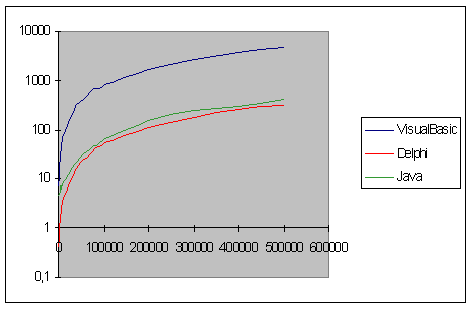
Il grafico
riporta in ordinata i valori del tempo
su scala logaritmica e in ascissa il numero di elementi che hanno subito il processi di ordinamento.
Dalla analisi del grafico possiamo vedere che Java e delphi si comportano in modo analogo. Un aspetto da mettere in risalto è l’andamento delle tre curve allo stato iniziale; Delphi ha valori negativi questo significa che per valori piccoli di elementi il tempo di ordinamento è dell’ordine dei microsecondi; Visual Basic è sull’ordine della decina di millisecondi così pure Java. Il grafico, seguente evidenzia la complessità del algoritmo e la differenza tra i tre compilatori nell’eseguirlo.
Quicksort su tipo
di dati intero Tempo
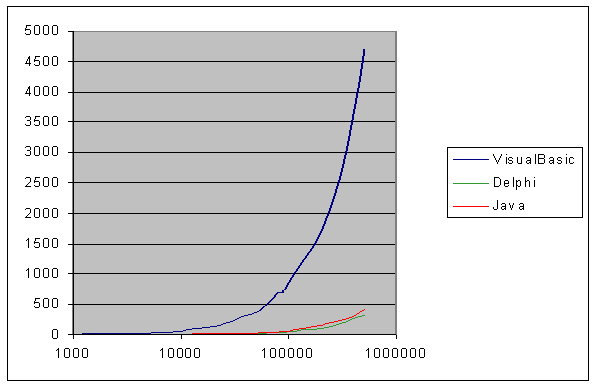
N° Elementi
N° elementi Tempo (ms)
Il numero di prove effettuato
termina sui 500.000 elementi per
due sostanziali motivi.
Sono sufficienti questi dati per predire le prestazioni dei compilatori per valori anche esterni all’intervallo di misura.
Per dimensioni prossime ai dieci milioni di elementi la gestione degli stessi viene affidata anche alla memoria virtuale di windows e dalla velocità di lettura e scrittura dei file di swap su disco fisso quando la memoria ram è satura. Queste due operazioni, oltre ad essere molto laboriose non garantiscono l’effettiva validità dei risultati di Bench-mark.
9.4.2 Bench-mark quicksort su tipo di dato string
Questa prova ha voluto mettere in evidenza il comportamento dei tre compilatori nel trattare tipi di dato in formato stringa. L’algoritmo è uguale al precedente cambiano gli argomenti delle procedure e il tipo di dati di ingresso che per questa prova è il file Stringhe.txt sempre presente nella cartella “data”. Queste stringhe sono state costruite attraverso un generatore di stringhe casuali sempre implementato in Visual Basic il cui listato è visualizzato in appendice.
I risultati
delle prove sono:
|
Quicksort su tipo di dato string |
VisualBasic (ms) |
Delphi (ms) |
Java (ms) |
|
1000 |
20,731 |
2,592 |
12 |
|
2000 |
41,75 |
5,467 |
17,848 |
|
3000 |
63,217 |
8,961 |
25,27 |
|
4000 |
94,459 |
12,621 |
32,798 |
|
5000 |
120,755 |
17,683 |
45,552 |
|
6000 |
152,75 |
23,222 |
58,468 |
|
7000 |
184,311 |
29,563 |
63,655 |
|
8000 |
206,769 |
32,417 |
68,673 |
|
9000 |
242,043 |
39,752 |
91,098 |
|
10000 |
264,88 |
43,595 |
92,112 |
|
20000 |
597,822 |
101,508 |
216,857 |
|
30000 |
928,675 |
179,342 |
361,738 |
|
40000 |
1271,148 |
256,561 |
532,88 |
|
50000 |
1637,48 |
411,897 |
634,472 |
|
60000 |
2419,555 |
517,184 |
794,265 |
|
70000 |
2353,45 |
521,815 |
1019,6 |
|
80000 |
3133,013 |
656,38 |
1084,17 |
|
90000 |
3200,559 |
807,244 |
1353,7 |
|
100000 |
4357,757 |
917,865 |
1448,23 |
|
200000 |
9827,675 |
2200,95 |
3.865 |
|
300000 |
13803,8426 |
3388,44 |
6231,82 |
|
400000 |
19781,544 |
4586,29 |
9014,14 |
|
500000 |
20583,686 |
6166,14 |
11744,4 |
Quicksort su tipo di
dato stringa Log Tempo (ms)
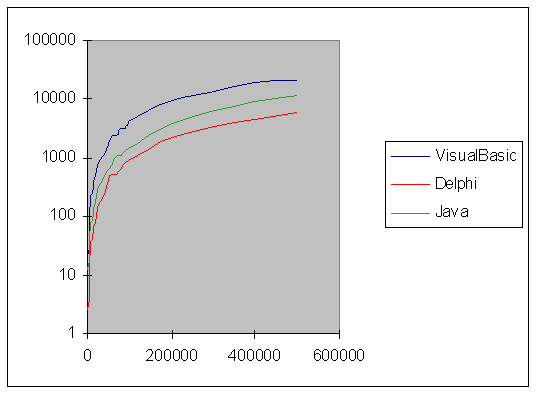
N° Elmenti
I risultati evidenziano come si trattano il problema di ordinamento sulle stringhe i tre compilatori. La differenza messa in risalto da questo grafico dimostra che VisualBasic non impegna tutte le sue risorse sull’algoritmo le impegna anche per altre operazioni di controllo sul tipo.
9.4.3 Bench-mark quicksort su tipo di dato dati double
I risultati
ottenuti nella gestione dei tipi di dato
in virgola mobile hanno messo in risalto
una superiorità di velocità tra Java
rispetto a Delphi.
Java, anche
se linguaggio semicompilato, prima della esecuzione attiva un traduttore in
codice nativo: trasforma il bytecode (codice intermedio) in modo molto simile
al codice nativo (.exe). Lo strumento si chiama JIT (Just In Time).
All'esecuzione ottimizza il codice prima di lanciarlo fisicamente. Ciò (come
dicono i progettisti) trasforma il bytecode in modo simile al codice C
compilato.
In altre
parole, il sistema JVM è un interprete che traduce ed esegue ciascuna
istruzione Bytecode separatamente ogni volta che l’istruzione è necessaria al
programma completo. Per alcuni programmi questa operazione può essere alquanto
lenta. I progettisti di Java hanno fornito lo strumento JIT che compila un file
Bytecode in una immagine eseguibile per consentire una esecuzione più rapida. La velocita maggiore di Java
rispetto a VisualBasic e Delphi si fa
sentire su un grannumero di elementi, mentre viceversa per basso numero di elementi Java risulta più lento di
Delphi.
I risultati ottenuti sono i seguenti:
|
Quicksort su tipo di dato double |
VisualBasic (ms) |
Delphi (ms) |
Java (ms) |
|
1000 |
42,973 |
0,628 |
4,788 |
|
2000 |
92,469 |
1,226 |
5,177 |
|
3000 |
144,309 |
1,836 |
6,033 |
|
4000 |
198,987 |
2,498 |
6,351 |
|
5000 |
257,796 |
3,106 |
6,813 |
|
6000 |
308,094 |
3,775 |
7,403 |
|
7000 |
370,791 |
4,605 |
7,996 |
|
8000 |
483,687 |
5,123 |
8,606 |
|
9000 |
480,678 |
5,854 |
9,121 |
|
10000 |
540,782 |
6,71 |
9,856 |
|
20000 |
1187,58 |
15,273 |
19,28 |
|
30000 |
1851,68 |
25,496 |
27,556 |
|
40000 |
2502,46 |
36,291 |
37,85 |
|
50000 |
3170,29 |
47,335 |
45,004 |
|
60000 |
3871,27 |
60,767 |
57,94 |
|
70000 |
4587,19 |
73,185 |
72,302 |
|
80000 |
5336,08 |
86,303 |
78,268 |
|
90000 |
6000,17 |
97,547 |
88,538 |
|
100000 |
6884,34 |
112,93 |
103,082 |
|
200000 |
14485,2 |
228,35 |
242,061 |
|
300000 |
22503,3 |
445,027 |
365,965 |
|
400000 |
30717,6 |
590,628 |
480,570 |
|
500000 |
39227,5 |
681,523 |
649,687 |
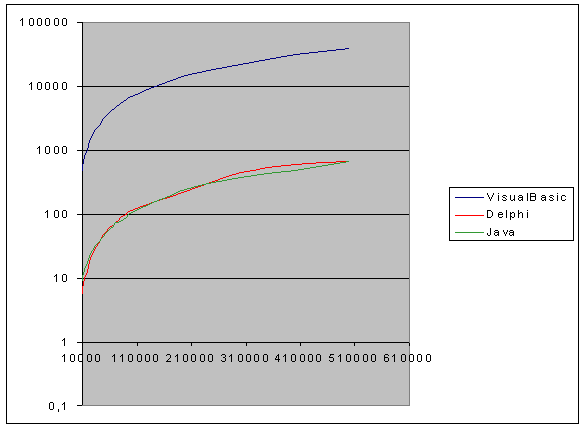
Si può
notare che Java comincia ad essere più veloce di Delphi quando il numero di elementi è prossimo alle 70.000 unità. Java sebbene
sia leggermente più lento di un codice nativo il JIT può accelerare di 10 o
perfino 20 volte l’esecuzione dei programmi Java.
La
filosofia di ottimizazione del compilatore JIT è verificare, per esempio, quale
segmento di codice all’interno del programma viene eseguito con maggiore frequenza
e ottimizzare solo tale codice per la velocità.
Questa
tecnologia è in continuo miglioramento e potrebbe finire per dare risultati non
raggiungibili con gli altri sistemi di programmazione.
TABELLA E GRAFICO RIASSUNTIVI
|
Quicksort |
VisualBasic interi |
Delphi interi |
Java interi |
VisualBasic stringhe |
Delphi stringhe |
Java stringhe |
VisualBasic Double |
Delphi Double |
Java Double |
|
1000 |
7,204 |
0,422 |
4,472 |
20,731 |
2,592 |
12,48 |
42,973 |
0,628 |
4,788 |
|
2000 |
11,309 |
0,722 |
4,949 |
41,75 |
5,467 |
17,848 |
92,469 |
1,226 |
5,177 |
|
3000 |
17,655 |
1,029 |
5,095 |
63,217 |
8,961 |
25,27 |
144,309 |
1,836 |
6,033 |
|
4000 |
23,675 |
1,365 |
5,381 |
94,459 |
12,621 |
32,798 |
198,987 |
2,498 |
6,351 |
|
5000 |
30,145 |
1,707 |
7,135 |
120,755 |
17,683 |
45,552 |
257,796 |
3,106 |
6,813 |
|
6000 |
37,931 |
2,05 |
6,254 |
152,75 |
23,222 |
58,468 |
308,094 |
3,775 |
7,403 |
|
7000 |
45,288 |
2,43 |
6,687 |
184,311 |
29,563 |
63,655 |
370,791 |
4,605 |
7,996 |
|
8000 |
49,884 |
2,672 |
7,048 |
206,769 |
32,417 |
68,673 |
483,687 |
5,123 |
8,606 |
|
9000 |
57,077 |
2,994 |
7,442 |
242,043 |
39,752 |
91,098 |
480,678 |
5,854 |
9,121 |
|
10000 |
68,033 |
3,38 |
8,288 |
264,88 |
43,595 |
92,112 |
540,782 |
6,71 |
9,856 |
|
20000 |
140,4 |
7,172 |
12,004 |
597,822 |
101,508 |
216,857 |
1187,58 |
15,273 |
19,28 |
|
30000 |
212,5 |
10,761 |
16,835 |
928,675 |
179,342 |
361,738 |
1851,683 |
25,496 |
27,556 |
|
40000 |
322,48 |
16,229 |
22,233 |
1271,148 |
256,561 |
532,88 |
2502,456 |
36,291 |
37,85 |
|
50000 |
370,5 |
21,925 |
27,849 |
1637,48 |
411,897 |
634,472 |
3170,292 |
47,335 |
45,004 |
|
60000 |
463,86 |
25,784 |
37,057 |
2419,555 |
517,184 |
794,265 |
3871,267 |
60,767 |
57,94 |
|
70000 |
594,16 |
32,382 |
40,076 |
2353,45 |
521,815 |
1019,601 |
4587,191 |
73,185 |
72,302 |
|
80000 |
703,37 |
40,419 |
48,277 |
3133,013 |
656,38 |
1084,165 |
5336,078 |
86,303 |
78,268 |
|
90000 |
712,16 |
45,455 |
51,909 |
3200,559 |
807,244 |
1353,7 |
6000,173 |
97,547 |
88,538 |
|
100000 |
850,09 |
55,242 |
66,216 |
4357,757 |
917,865 |
1448,229 |
6884,338 |
112,93 |
103,082 |
|
200000 |
1686,2 |
109,209 |
159,715 |
9827,675 |
2200,947 |
3.865 |
14485,177 |
228,35 |
242,061 |
|
300000 |
2605,5 |
174,863 |
251,217 |
13803,84265 |
3388,442 |
6231,82 |
22503,345 |
445,027 |
365,965 |
|
400000 |
3637,7 |
253,851 |
298,192 |
19781,544 |
4586,289 |
9014,138 |
30717,605 |
590,628 |
480,570 |
|
500000 |
4702,8 |
318,06 |
421,768 |
20583,686 |
6166,135 |
11744,36 |
39227,534 |
681,523 |
649,687 |
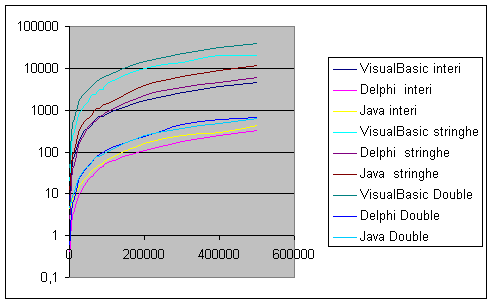
9.4.4 Bench-mark del prodotto tra matrici quadrate su tipo di dato double
Dalla
teoria emerge che la complessità dell’algoritmo del prodotto tra matrici ha
complessità Q(n3).
|
Prodotto si matrici quadrate nxn |
VisualBasic (ms) |
Delphi (ms) |
Java (ms) |
|
5 |
0,702 |
0,197 |
5,546 |
|
10 |
1,332 |
0,269 |
5,65 |
|
20 |
5,521 |
0,715 |
5,906 |
|
30 |
16,826 |
1,752 |
6,671 |
|
40 |
37,342 |
3,806 |
7,94328 |
|
50 |
73,333 |
7,587 |
10,859 |
|
60 |
121,824 |
13,224 |
15,394 |
|
70 |
193,984 |
21,537 |
20,126 |
|
80 |
297,696 |
34,6737 |
27,122 |
|
90 |
417,665 |
46,883 |
39,71 |
|
100 |
583,15 |
66,934 |
65,26 |
Prodotto tra matrici
quadrate nxn Log Tempo (ms)
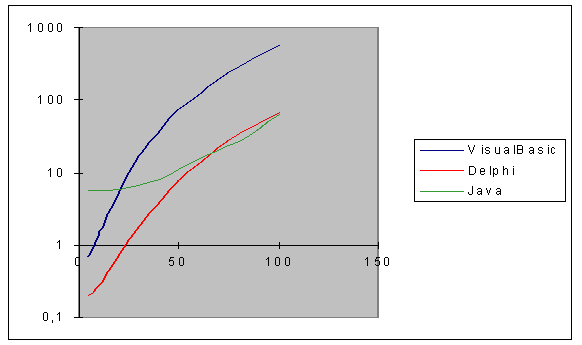
N° elementi
Questa prova di Bench-mark ha estratto in modo significativo e visuale quanto è stato detto sul JIT di Java nella prova dei tipi di dati Double. La curva in verde relativa a Java dimostra appunto questo aspetto: bassa efficienza per dimensioni di matrici piccole, e alta efficienza per dimensioni elevate di matrici popolate con tipi di dato double.
9.4.5 Bench-marck di calcolo della triangolare
superiore con tipi di dato double
Questa prova e le successive sono state eseguite solo sui compilatori Delphi e VisualBasic in quanto le precedenti prove sembrano aver risposto a tutte le domande che ci eravamo posti sul comportamento di Java, nel trattamento dei tipi di dati presi in considerazione in questo lavoro di tesi.
Il calcolo della triangolare superiore è uno degli aspetti più interessanti dal punto di vista del calcolo automatico. Anche in questa prova si è tentato di mettere alla luce i problemi dei compilatori attraverso l’applicazione dell’algoritmo di Crout.
|
Triangolarizzazione numero di
elementi n di matrici nxn |
VisualBasic (ms) |
Delphi (ms) |
|
2 |
0,095 |
0,118 |
|
3 |
0,113 |
0,124 |
|
4 |
0,121 |
0,132 |
|
5 |
0,128 |
0,133 |
|
6 |
0,143 |
0,135 |
|
7 |
0,144 |
0,144 |
|
8 |
0,177 |
0,147 |
|
9 |
0,109 |
0,16 |
|
10 |
0,218 |
0,158 |
|
20 |
0,771 |
0,29 |
|
25 |
1,268 |
0,408 |
|
30 |
2,006 |
0,568 |
|
35 |
2,996 |
0,788 |
|
40 |
4,263 |
1,081 |
|
45 |
5,925 |
1,547 |
|
50 |
8,047 |
1,824 |
|
55 |
10,317 |
2,358 |
|
60 |
13,56 |
2,95 |
|
65 |
17,101 |
3,659 |
|
70 |
22,036 |
4,428 |
|
75 |
25,445 |
5,461 |
|
80 |
31,258 |
6,527 |
|
85 |
36,366 |
7,775 |
|
90 |
43,227 |
8,976 |
Dimensione Tempo (ms) Prodotto tra matrici
quadrate nxn
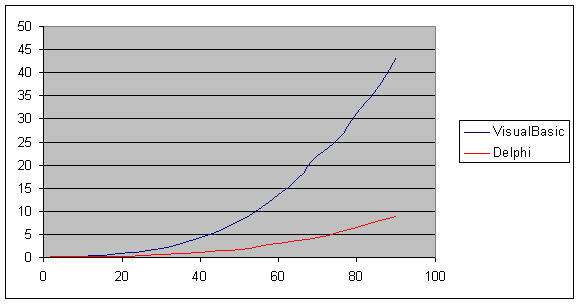
9.4.6 Bench-mark del algoritmo di ottimizzazione zaino
su tipi di dato double
L’andamento
delle curve è di tipo lineare come vuole
la complessità matematica. Dalla analisi dei dati si può notare che anche in
condizioni di linearità VB si trova in situazione di inferiorità prestazionale rispetto a
Delphi
I risultati della prova sono stati ricavati impostando la dimensione dello zaino costante, questo perché ai fini
del test non comporta delle differenze significative:
|
Zaino di capacità 50000 |
VisualBasic (ms) |
Delphi (ms) |
|
10 |
0,875 |
0,1726 |
|
20 |
0,928 |
0,176 |
|
30 |
1,00 |
0,178 |
|
40 |
1,041 |
0,187 |
|
50 |
1,1 |
0,193 |
|
60 |
1,237 |
0,194 |
|
70 |
1,29 |
0,202 |
|
80 |
1,392 |
0,206 |
|
90 |
1,49 |
0,213 |
|
100 |
1,504 |
0,223 |
|
500 |
4,83 |
0,516 |
|
1000 |
9,624 |
0,864 |
|
2000 |
21,472 |
1,706 |
|
3000 |
33,481 |
2,529 |
|
4000 |
43,175 |
3,401 |
|
5000 |
54,852 |
4,644 |
|
6000 |
66,914 |
5,671 |
|
7000 |
79,25 |
6,796 |
|
8000 |
92,141 |
8,684 |
|
9000 |
106,033 |
9,844 |
|
10000 |
118,186 |
11,42 |
|
50000 |
686,488 |
93,91 |
|
100000 |
1463,115 |
222,063 |
Tempo (ms) Zaino Log Tempo(ms)
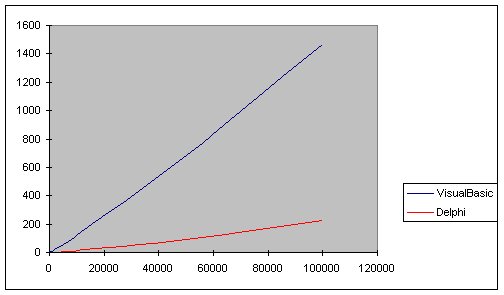
Zaino
Il grafico su scala
logaritmica evidenzia la differenza di
velocità.
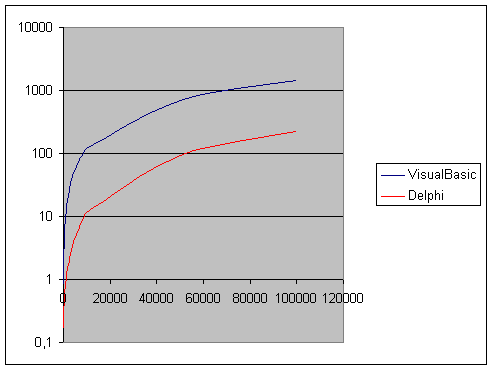
9.5 CONSIDERAZIONI GENERALI
In
Visual Basic esistono dei controlli di ottimizzazione specifici che garantiscono una minima
ottimizzazione di velocità e di dimensione.
L’ottimizzazione di velocità dei file eseguibili comporta un aumento delle dimensioni degli stessi. Quando il compilatore traduce un codice nel corrispondente linguaggio macchina, spesso una determinata istruzione o un particolare blocco di istruzioni può essere scritto in numerose forme, per quanto diverse, tutte lecite. La scelta tra due particolari tipi di istruzioni rappresenta un compromesso tra dimensioni e velocità. Uno degli scopi di questo lavoro è stato quello di riconoscere tra un insieme di alternative la sequenza di codice più veloce possibile, anche quando questo può comportare l’aumento delle dimensioni del programma compilato.
Viene da sé che il problema inverso, è quello di ridurre al minimo le dimensioni dei file eseguibili a discapito della velocità.
La nascita di questo compromesso pone il programmatore e l’utente di fronte al problema di individuare tra un insieme di alternative, la scelta dell’ottimo nel contesto reale in cui opera.
In VisualBasic esiste un controllo per gli elementi in virgola mobile: l’arrotondamento avviene solitamente in maniera predefinita dal compilatore; la sua disabilitazione comporta un netto miglioramento delle velocità.
9.6 VISUALBASIC DELPHI
E JAVA
Non esiste un linguaggio perfetto per tutti i progetti. Questo perché progetti diversi hanno obbiettivi e priorità diverse che devono essere chiare fin dall’inizio.
La scelta del tipo di piattaforma è funzione del tipo di progetto che intendiamo realizzare.
un progetto può fallire semplicemente per mancanza di chiarezza sul suo scopo.
Una metodologia per evitare l’insuccesso va ricercata nelle scelte che devono essere fatte attraverso delle basi solide di teoria computazionale.
Per la scelta del linguaggio appropriato al fine di sviluppare una applicazione è necessario fare chiarezza sullo scopo del progetto e sui tipi di dati da elaborare. Non basta avere deciso e documentato chiaramente cosa deve fare una applicazione dal punto di vista funzionale, è indispensabile analizzare anche l’aspetto non funzionale del progetto.
I tre tipi di linguaggio presi in esame sono linguaggi che supportano un programmazione ad oggetti anche se tuttavia questi ultimi sono trattati in maniera diversa.
Tutti e tre hanno una ampia documentazione e una ampia base di sviluppatori competenti e tutti e tre possono essere utilizzati per sviluppare applicazioni piccole, medie e grandi.
Nella realtà sono tre linguaggi molto diversi e hanno caratteristiche altrettanto diverse e riassunti nella seguente tabella.
|
|
Visual Basic |
Delphi |
Java |
|
Object-oriented |
In parte |
Si |
si |
|
Eereditarietà delle interfacce |
No |
Si |
si |
|
Ereditarietà di implementazione |
No |
Si |
Si |
|
Ereditarietà Multipla di implementazione |
In parte |
No |
|
|
Polimorfismo di metodi e funzioni |
In parte |
Si dalla 4 versione |
Si |
|
Template |
No |
No |
|
|
Gestione degli errori tramite eccezioni |
No |
Si |
Si |
|
Garbarage Collection automatica |
No |
No |
Si |
|
Aritmentica dei puntatori |
No |
Si |
|
|
Libreria di classi standard |
No |
Si (Visual component library) |
Si |
|
Controllo della sicurezza a livello di runtime |
No |
N/A |
Si |
VISUALBASIC
Visual Basic è il
linguaggio meno dotato dal punto di
vista della potenza, dato che non supporta ancora l’ereditarietà
dell’implementazione e la gestione degli errori attraverso l’istruzione “on error goto”, rispetto alla
gestione delle eccezioni di Java è un metodo obsoleto. È l’unico dei tre linguaggi disponibile su una
unica piattaforma.
E’ sufficiente a soddisfare la quasi totalità delle applicazioni di Windows.
Dei tre linguaggi è il più facile da apprendere.
Utilizzare al massimo le sue capacità non è più semplice degli altri due linguaggi visto che è un agglomerato di sintassi, modalità e stili di programmazione diversi aggiunti in tempi successivi a quello che era il Basic.
La curva di apprendimento non è molto ripida, in breve tempo si può utilizzare il linguaggio per scrivere un programma, ma le sue potenzialità possono essere estratte solo attraverso una lunga esperienza.
Anche se le caratteristiche attuali del linguaggio sono limitate rispetto ad altri ambienti la cronaca riporta che in famiglia Microsoft ci sono tutte le caratteristiche per continuare a supportare e sviluppare VisualBasic, tanto da aver anticipato che nella versione 7 sarà implementata la caratteristica di ereditarietà e la gestione delle eccezioni in linea con gli altri linguaggi di programmazione. La grande diffusione da garanzia che il linguaggio sarà ritenuto valido ancora per molti anni anche se non portabile su altre piattaforme.
Esistono dei controlli di ottimizzazione del codice in VisualBasic:
Il primo controllo è la possibilità di scelta che l’ambiente offre di tradurre un eseguibile in P-code o codice nativo. La prova di ordinamento su 100.000 elementi ha dato come risultato in P-code 2362ms e in codice nativo 867ms.
Una ulteriore possibilità che offre Visual Basic è abilitare o disabilitare una impostazione che controlla gli errori per gli indici di matrice validi e il corretto numero di dimensioni di una matrice. Se l’indice è esterno ai limiti della matrice, viene restituito un errore. Se questo controllo viene disattivato si introduce un significativo aumento delle della velocità di operazioni di matrici ma con il rischio di accedere a delle locazioni di memoria non valide senza per altro che venga visualizzato alcun messaggio di avvertimento.
Un altro controllo che pregiudica la velocità del programma compilato è il controllo di overflow degli interi. L’impostazione predefinita in Visual Basic consente un continuo controllo su ciascun calcolo che coinvolge una variabile con dati di tipo intero (Byte, integer, long ) per verificare che il risultato dell’operazione sia compreso nell’intervallo di tale tipo.
Se il risultato in valore assoluto è errato viene automaticamente generato un errore.
Anche in questo caso la rimozione di questo controllo migliora la velocità del compilato.
Di contro la sua disattivazione oscura la veridicità dei calcoli.
Le prestazioni di velocità dipendono da un ulteriore controllo predefinito in VisualBasic ed è quello per verificare che i valori numerici assegnati siano corretti, cioè compresi nell’intervallo di tipi di dati e che controlli se erroneamente vengono operate divisioni per zero e altre operazioni illecite per il tipo di dato.
JAVA
Dei tre linguaggi in esame, Java è indubbiamente il più moderno.
Java divide tranquillamente un numero in virgola mobile per 0 e non riporta alcun errore ma solleva una eccezione, questa mancanza di controllo in alcuni casi lo rende un po’ più performante.
In Java la struttura degli interi non dipende dalla macchina su cui l’applicazione verrà eseguita. Questo allevia ai programmatori il problema di portabilità da una piattaforma hardware ad un'altra o da un sistema operativo ad un altro .
Infatti alcuni compilatori su piattaforme diverse
possono provocare degli overflow di interi.
Questo
fatto comporta un calo di prestazioni in alcuni casi.
In
Java tutti i tipi di dati sono indipendenti dal sistema operativo e
inoltre non possiede un tipo di dati
unsigned.
Sempre in
Java, l’elaborazione dei numeri float a precisione singola e più
veloce di un ordine di grandezza della stessa elaborazione che utilizza il tipo
double.
Rispetto al C++ gli manca l'ereditarietà multipla e i tipi parametrici ma di contro è dotato di tutte le caratteristiche desiderabili dal punto di vista sintattico e semantico. E’ un linguaggio che permette di sviluppare applicazioni multithread utilizzando unicamente elementi del linguaggio base, senza l’utilizzo di tools esterni. Ha una eccellente gestione delle eccezioni assai simile al C++ ed è dotato di una serie di librerie molto potenti e in continuo sviluppo.
Il fatto che Java sia un linguaggio semicompilato in un linguaggio intermedio che produce file. class determina caratteristiche fortemente positive (interprete JVM) e negative allo stesso tempo.
Il punto di forza è la JVM (Java Virtual Machine). Questo è un interprete standard in grado di far funzionare un programma su una qualsiasi piattaforma senza la necessità di ricompilare il programma. Questo ne fa un linguaggio di elezione per tutti quei casi in cui la portabilità sia assolutamente necessaria, come nel caso di applet da includere in pagine web.
Il punto debole è che il fatto di non poter essere completamente compilato in linguaggio macchina rende Java assai meno efficiente degli altri linguaggi. Questo fatto non è troppo visibile considerando il fatto che la maggior parte degli applicativi attendono buona parte del tempo in eventi e componenti esterni.
Dei tre linguaggi Java è quello più sofferente in ambiente Microsoft.
Le battaglie legali che da qualche tempo stanno investendo casa Microsoft rende poco trasparente il futuro di Java. Può accadere che Microsoft decida di abbandonare il prodotto Java prodotto dalla Sun, al suo destino, ed investire in più moderne versioni di Visual Basic.
DELPHI
Delphi di tutti e tre i compilatori è il meno diffuso.
Le sue caratteristiche di object-oriented, compilazione veloce, integrazione con Windows e portabilità su altre piattaforme come Linux Os/2, sono aspetti poco conosciuti almeno nell’ambito italiano
Il suo ruolo di fratello minore del Pascal è oscurato, negli ambienti accademici dallo stesso Pascal e dal potente C considerati ormai strumenti fondamentali di studio-sviluppo.
Nonostante ciò rimane un ottimo ambiente per la produzione e distribuzione di software a livello commerciale.
10
I LISTATI
10.1 VISUALBASIC 6
Generatore di numeri interi casuali per il bench-mark quicksort
Public a() As Long
Public dimensione As Long
Private Sub Command1_Click()
dimensione
= Text1.Text
ReDim
a(dimensione)
End Sub
Private Sub Command3_Click()
i = 0
Open "c:\tesi\data\Interi.txt" For
Output As 1
For i =
0 To dimensione
Write
#1, a(i)
Next
Close #1
End Sub
Private Sub Command4_Click()
Dim
i As Long
Randomize ' generatore
casuali di numeri interi interi'
For i = 0 To
dimensione
a(i) = Int((100 * Rnd) + 1)
Next
i
End Sub
Generatore di stringhe casuali per il bench-mark quicksort
Public a() As String
Public dimensione As Long
Private Sub Command1_Click()
i = 0
Open "c:\tesi\data\Stringhe.txt" For
Output As 1
For i = 0 To dimensione
Write #1, a(i)
Next
Close #1
End Sub
Private Sub Command2_Click()
Randomize
For
i = 0 To dimensione
n =
Int((10 * Rnd) + 5)
For
k = 1 To n
s =
s + Chr((21 * Rnd) + 65)
Next k
a(i) = s
s =
""
Next
i
End Sub
Private
Sub Command3_Click()
dimensione
= Text1.Text
ReDim
a(dimensione)
End
Sub
Generatore
di numeri casuali in virgola mobile per
il bench-mark quicksort
Public a() As Double
Public dimensione As Long
Private Sub Command1_Click()
i = 0
Open "c:\tesi\data\double.txt" For
Output As 1
For i = 0 To dimensione
Write #1, a(i)
Next
Close #1
End Sub
Private Sub Command2_Click()
Randomize
For
i = 0 To dimensione
n = Int((10 * Rnd) + 5)
s
= CDbl(((Rnd(10) - Rnd(10)) * (Rnd(1000) / (1 + Rnd(100)))))
a(i) = s
Next
i
End Sub
Private
Sub Command3_Click()
dimensione
= Text1.Text
ReDim
a(dimensione)
End Sub
QUICKSORT PER TIPI DI DATI INTEGER
Modulo
Const MaxSizeArray = 10000000
Const InFileName =
"C:\Tesi\data\Interi.txt"
Const OutFileName =
"C:\Tesi\data\sortinteri.txt"
Public MaxArray As Long
Public BaseArray(0 To MaxSizeArray) As Long
Public tl0, tl1, tlfreq As Currency
Public Declare Function
QueryPerformanceCounter Lib "Kernel32" _
(X As
Currency) As Boolean
Public Declare Function
QueryPerformanceFrequency Lib "Kernel32" _
(X As
Currency) As Boolean
Public
Sub StartChrono()
Call
QueryPerformanceFrequency(tlfreq)
Call
QueryPerformanceCounter(tl0)
TfMain!eTempo.Text = " "
End Sub
Public
Sub StopChrono()
Call
QueryPerformanceCounter(tl1)
TfMain!eTempo.Text = "Tempo = " & Format((((tl1 - tl0) /
tlfreq) * 1000), "###.### msec")
End Sub
Public
Sub LoadFromFile(FileName As String)
Dim f
As Long
Dim
line As String
MaxArray = -1
f =
FreeFile
Open
InFileName For Input As #f
Do
While Not EOF(f)
Line
Input #f, line
MaxArray = MaxArray + 1
BaseArray(MaxArray) = CLng(line)
Loop
Close
#f
End Sub
Public
Sub SaveToFile(FileName As String)
Dim f
As Long
Dim
line As String
Dim i
As Long
f =
FreeFile
Open
OutFileName For Output As #f
For i =
0 To MaxArray
Write
#f, CStr(BaseArray(i))
Next i
Close
#f
End Sub
Public
Function QuickSort(BaseArray() As Long,
ByVal iLo As Long, ByVal iHi As Long)
Dim mid As Long
Lo =
iLo
Hi =
iHi
mid =
BaseArray((Lo + Hi) \ 2)
Do
While (BaseArray(Lo) <
mid)
Lo = Lo + 1
Wend
While
(BaseArray(Hi) > mid)
Hi
= Hi - 1
Wend
If Lo <= Hi Then
T = BaseArray(Lo)
BaseArray(Lo) = BaseArray(Hi)
BaseArray(Hi) = T
Lo = Lo + 1
Hi = Hi - 1
End
If
Loop
Until (Lo > Hi)
If Hi
> iLo Then
Call
QuickSort(BaseArray, iLo, Hi)
End If
If Lo
< iHi Then
Call
QuickSort(BaseArray, Lo, iHi)
End If
End Function
Private
Sub Command1_Click() Bench-mark
StartChrono
StopChrono
StartChrono
Call
QuickSort(BaseArray, 0, MaxArray)
StopChrono
eTempo.Text = "Tempo = " &
Format((Ctr2 - Ctr1) / Freq * 1000, "### msec")
SaveToFile (OutFileName)
End Sub
Private
Sub Form_Load()
LoadFromFile (InFileName)
Rem ShowData(BaseArray,)
End Sub
QUICKSORT SU TIPO DI DATO DOUBLE
Modulo
Const MaxSizeArray = 10000
Const InFileName =
"C:\Tesi\data\double.txt"
Const OutFileName =
"C:\Tesi\data\sortdouble.txt"
Public MaxArray As Long
Public BaseArray(0 To MaxSizeArray) As Double
Public tl0, tl1, tlfreq As Currency
Public Declare Function QueryPerformanceCounter
Lib "Kernel32" _
(X As
Currency) As Boolean
Public Declare Function
QueryPerformanceFrequency Lib "Kernel32" _
(X As
Currency) As Boolean
Public
Sub StartChrono()
Call
QueryPerformanceFrequency(tlfreq)
Call
QueryPerformanceCounter(tl0)
TfMain!eTempo.Text = " "
End Sub
Public
Sub StopChrono()
Call
QueryPerformanceCounter(tl1)
TfMain!eTempo.Text = "Tempo = " & Format((((tl1 - tl0) /
tlfreq) * 1000), "###.### msec")
End Sub
Public
Sub LoadFromFile(FileName As String)
Dim f
As Long
Dim
line As Double
MaxArray = -1
f =
FreeFile
Open
InFileName For Input As #f
Do
While Not EOF(f)
Line
Input #f, line
MaxArray = MaxArray + 1
a =
CVar(line)
BaseArray(MaxArray) = a
Loop
Close
#f
End Sub
Public
Sub SaveToFile(FileName As String)
Dim f As Long
Dim line As String
Dim i
As Long
f =
FreeFile
Open
OutFileName For Output As #f
For i =
0 To MaxArray
Write
#f, CStr(BaseArray(i))
Next i
Close #f
End Sub
Public
Function QuickSort(BaseArray() As Double, ByVal iLo As Long, ByVal iHi As Long)
Dim mid, t As String
Lo =
iLo
Hi =
iHi
mid =
BaseArray((Lo + Hi) \ 2)
Do
While (BaseArray(Lo) <
mid)
Lo = Lo + 1
Wend
While
(BaseArray(Hi) > mid)
Hi
= Hi - 1
Wend
If Lo
<= Hi Then
t = BaseArray(Lo)
BaseArray(Lo) = BaseArray(Hi)
BaseArray(Hi) = t
Lo = Lo + 1
Hi = Hi - 1
End
If
Loop
Until (Lo > Hi)
If Hi
> iLo Then
Call
QuickSort(BaseArray, iLo, Hi)
End If
If Lo
< iHi Then
Call
QuickSort(BaseArray, Lo, iHi)
End If
End Function
Form
Private
Sub Command1_Click()
StartChrono
StopChrono
StartChrono
Call
QuickSort(BaseArray, 0, MaxArray)
StopChrono
SaveToFile (OutFileName)
End Sub
Private
Sub Form_Load()
LoadFromFile (InFileName)
Call QueryPerformanceFrequency(tlfreq)
Call
QueryPerformanceCounter(tl0)
Call
QueryPerformanceCounter(tl1)
End Sub
QUICKSORT SU TIPO DI DATO IN FORMATO STRINGA
modulo
Const MaxSizeArray = 500000
Const InFileName =
"C:\Tesi\data\Stringhe.txt"
Const OutFileName =
"C:\Tesi\data\Stringhesort.txt"
Public MaxArray As Long
Public BaseArray(0 To MaxSizeArray) As String
Public tl0, tl1, tlfreq As Currency
Public Declare Function QueryPerformanceCounter
Lib "Kernel32" _
(X As
Currency) As Boolean
Public Declare Function
QueryPerformanceFrequency Lib "Kernel32" _
(X As
Currency) As Boolean
Public
Sub StartChrono()
Call
QueryPerformanceFrequency(tlfreq)
Call
QueryPerformanceCounter(tl0)
TfMain!eTempo.Text = " "
End Sub
Public
Sub StopChrono()
Call
QueryPerformanceCounter(tl1)
TfMain!eTempo.Text = "Tempo = " & Format((((tl1 - tl0) /
tlfreq) * 1000), "###.### msec")
End Sub
Public
Sub LoadFromFile(FileName As String)
Dim f
As Long
Dim
line As String
MaxArray = -1
f =
FreeFile
Open
InFileName For Input As #f
Do
While Not EOF(f)
Line
Input #f, line
MaxArray = MaxArray + 1
BaseArray(MaxArray) = line
Loop
Close
#f
End Sub
Public
Sub SaveToFile(FileName As String)
Dim f
As Long
Dim
line As String
Dim i
As Long
f =
FreeFile
Open
OutFileName For Output As #f
For i =
0 To MaxArray
Write
#f, CStr(BaseArray(i))
Next i
Close
#f
End Sub
Public
Function QuickSort(BaseArray() As String, ByVal iLo As Long, ByVal iHi As Long)
Dim mid, t As String
Lo = iLo
Hi =
iHi
mid =
BaseArray((Lo + Hi) \ 2)
Do
While (BaseArray(Lo) <
mid)
Lo = Lo + 1
Wend
While
(BaseArray(Hi) > mid)
Hi
= Hi - 1
Wend
If Lo
<= Hi Then
t = BaseArray(Lo)
BaseArray(Lo) = BaseArray(Hi)
BaseArray(Hi) = t
Lo = Lo + 1
Hi = Hi - 1
End
If
Loop
Until (Lo > Hi)
If Hi
> iLo Then
Call
QuickSort(BaseArray, iLo, Hi)
End If
If Lo
< iHi Then
Call
QuickSort(BaseArray, Lo, iHi)
End If
End Function
Form
Private
Sub Command1_Click()
StartChrono
StopChrono
StartChrono
Call
QuickSort(BaseArray, 0, MaxArray)
StopChrono
SaveToFile (OutFileName)
End Sub
Private
Sub Form_Load()
LoadFromFile (InFileName)
Rem call ShowData(BaseArray,)
Call QueryPerformanceFrequency(tlfreq)
Call
QueryPerformanceCounter(tl0)
Call
QueryPerformanceCounter(tl1)
End Sub
TRIANGOLARIZZAZIONE SUPERIORE DI MATRICI E CALCOLO DEL DETERMINANTE DI MATRICI NXN
Modulo
Const MaxSizeArray = 100
Const InFileName =
"C:\Tesi\data\double.txt"
Public MaxArray As Long
Public a(0 To MaxSizeArray, 0 To MaxSizeArray)
As Double
Public tl0, tl1, tlfreq As Currency
Public Declare Function QueryPerformanceCounter
Lib "Kernel32" _
(X As
Currency) As Boolean
Public Declare Function
QueryPerformanceFrequency Lib "Kernel32" _
(X As
Currency) As Boolean
Public
Sub LoadFromFile(FileName As String)
Dim f
As Long
Dim
line As String
Dim I,
J As Integer
f =
FreeFile
Open
InFileName For Input As #f
Line Input #f, line 'La
prima riga è la dimensione della matrice
MaxArray = CInt(line)
For I
= 1 To MaxArray
For J
= 1 To MaxArray
Line
Input #f, line
a(I,
J) = CLng(line)
b(i, j) = a(i, j)
Next J
Next I
Close
#f
End Sub
Public
Sub StartChrono()
Call
QueryPerformanceFrequency(tlfreq)
Call
QueryPerformanceCounter(tl0)
Form1!Text1.Text = " "
End Sub
Public
Sub StopChrono()
Call
QueryPerformanceCounter(tl1)
Form1!Text1.Text = "Tempo = " & Format((((tl1 - tl0) /
tlfreq) * 1000), "###.### msec")
End Sub
Public
Sub ludcmp(a#(), d#)
'Indx&(), d#)
Dim
I&, IMax&, N&, J&, K&
Dim
aamax#, dum#, sum#, vv#(), tiny#
N =
MaxArray
ReDim
Indx(1 To N)
ReDim vv#(1 To N)
tiny = 1E-20
d = 1#
For I
= 1 To N
aamax = 0#
For J = 1 To N
If (Abs(a(I, J)) > aamax) Then aamax = Abs(a(I, J))
Next J
If (aamax = 0#) Then
MsgBox "Matrice singolare"
Exit Sub
End If
vv(I) = 1# / aamax
Next I
For J
= 1 To N
For I = 1 To J - 1
sum = a(I, J)
For K = 1 To I - 1
sum = sum - a(I, K) * a(K, J)
Next K
a(I, J) = sum
Next I
aamax = 0#
For I = J To N
sum = a(I, J)
For K = 1 To J - 1
sum = sum - a(I, K) * a(K, J)
Next K
a(I, J) = sum
dum = vv(I) * Abs(sum)
If (dum >= aamax) Then
IMax = I
aamax = dum '
End If
Next I
'
If (J <> IMax) Then
For K = 1 To N
dum = a(IMax, K)
a(IMax, K) = a(J, K)
a(J, K) = dum
Next K
d = -d
vv(IMax) = vv(J)
End If
Indx(J) = IMax
If (a(J, J) = 0#) Then a(J, J) = tiny
If (J <> N) Then
dum = 1# / a(J, J)
For I = J + 1 To N
a(I, J) = a(I, J) * dum
Next I
End If
Next
J
End Sub
Public Function
Determinante(a#()) As Double
Dim Indx&(), J&, d#
'Call
ludcmp(a(), Indx(), d) ' This returns d
as ± 1.
Call
QueryPerformanceFrequency(tlfreq)
Call
QueryPerformanceCounter(tl0)
Call ludcmp(a(), d)
Call
QueryPerformanceCounter(tl1)
Form1!Text3.Text = "Tempo = " & Format((((tl1 - tl0) /
tlfreq) * 1000), "###.### msec")
For J
= 1 To MaxArray
d
= d * a(J, J)
Next
J
Form1!Text2.Text = d
End Function
Form1
Private
Sub Command1_Click()
StartChrono
Call Determinante(a())
StopChrono
End Sub
Private
Sub Command2_Click()
For I = 1 To MaxArray
For J =
1 To MaxArray - 1
V$ = Format$(a(I, J), "#0.000")
If Left$(V$, 1) <> "-" Then V$ = "+" & V$
Label3.Caption = Label3 & V$ & " "
Next J
V$
= Format$(a(I, MaxArray), "#0.000")
If
Left$(V$, 1) <> "-" Then V$ = "+" & V$
Label3.Caption = Label3 & V$ & vbCrLf
Next
I
End Sub
Private
Sub Form_Load()
LoadFromFile (InFileName)
Call
QueryPerformanceFrequency(tlfreq)
Call
QueryPerformanceCounter(tl0)
Call
QueryPerformanceCounter(tl1)
End Sub
PRODOTTO DI
MATRICI QUADRATE
Modulo
Const MaxSizeArray = 100
Const InFileName =
"C:\Tesi\data\double.txt"
Public MaxArray As Long
Public a(0 To MaxSizeArray, 0 To MaxSizeArray)
As Double
Public b(0 To MaxSizeArray, 0 To MaxSizeArray)
As Double
Public d(0 To MaxSizeArray, 0 To MaxSizeArray)
As Double
Public tl0, tl1, tlfreq As Currency
Public Declare Function
QueryPerformanceCounter Lib "Kernel32" _
(X As
Currency) As Boolean
Public Declare Function
QueryPerformanceFrequency Lib "Kernel32" _
(X As
Currency) As Boolean
Public Sub LoadFromFile(FileName As String)
Dim f As Long
Dim
line As String
Dim i,
j As Integer
f =
FreeFile
Open
InFileName For Input As #f
Line Input #f, line 'La
prima riga è la dimensione della matrice
MaxArray = CInt(line)
For i
= 1 To MaxArray
For
j = 1 To MaxArray
Line
Input #f, line
a(i,
j) = CLng(line)
b(i, j) = a(i, j)
Next j
Next i
Close
#f
End Sub
Public
Sub StartChrono()
Call
QueryPerformanceFrequency(tlfreq)
Call
QueryPerformanceCounter(tl0)
Form1!Text1.Text = " "
End Sub
Public
Sub StopChrono()
Call
QueryPerformanceCounter(tl1)
Form1!Text1.Text = "Tempo = " & Format((((tl1 - tl0) /
tlfreq) * 1000), "###.### msec")
End Sub
Public
Sub moltiplica()
For i = 1 To MaxArray
For j =
1 To MaxArray
d(i, j)
= 0
For k =
1 To MaxArray
d(i, j) = d(i, j) + a(i, k) * b(k, j)
Next k
Next j
Next i
End Sub
Form
Private
Sub Command1_Click()
StartChrono
'For i = 1 To 10
moltiplica
'Next i
StopChrono
End Sub
Private
Sub Command2_Click()
For i = 1 To MaxArray
For
j = 1 To (MaxArray - 1)
V$ = Format$(d(i, j), "#0.000")
If Left$(V$, 1) <> "-" Then V$ = "+" & V$
Label1.Caption = Label1 & V$ & " "
Next j
V$
= Format$(d(i, MaxArray), "#0.000")
If
Left$(V$, 1) <> "-" Then V$ = "+" & V$
Label1.Caption = Label1 & V$ & vbCrLf
Next
i
End Sub
Private
Sub Form_Load()
LoadFromFile (InFileName)
End Sub
ZAINO
Const MaxSizeArray = 100000
Const
InFileName = "c:\Tesi\data\zaino.txt"
Const OutFileName = "c:\tesi
data\xzaino.txt"
'TBaseInteger = array[0..MaxSizeArray] of Integer;
'TBaseDouble = array[0..MaxSizeArray] of double;
Public
Declare Function QueryPerformanceCounter Lib "Kernel32" _
(x As
Currency) As Boolean
Public Declare Function
QueryPerformanceFrequency Lib "Kernel32" _
(x As Currency)
As Boolean
Public p(0 To MaxSizeArray) As Long
Public
v(0 To MaxSizeArray) As Long
Public
x(0 To MaxSizeArray) As Double
Public
a(0 To MaxSizeArray) As Double
Public
c, MaxArray As Long
Public
tl0, tl1, tlfreq As Currency
Public
Sub StartChrono()
Call
QueryPerformanceFrequency(tlfreq)
Call
QueryPerformanceCounter(tl0)
Form1!Text1.Text = " "
End Sub
Public
Sub StopChrono()
Call
QueryPerformanceCounter(tl1)
Form1!Text1.Text = "Tempo = " & Format((((tl1 - tl0) /
tlfreq) * 1000), "###.### msec")
End Sub
Public
Sub LoadFromFile(FileName As String)
Dim f As Long
Dim line As String
Dim i As Long
f = FreeFile
Open
InFileName For Input As #f
Line
Input #f, line
MaxArray = CLng(line)
Line
Input #f, line
c =
CLng(line)
For i =
0 To MaxArray - 1
Line
Input #f, line
p(i)
= CLng(line)
Line
Input #f, line
v(i)
= CLng(line)
a(i)
= p(i) / v(i)
Next
i
Close
#f
End Sub
Public
Function QuickSort(a() As Double, ByVal iLo As Long, ByVal iHi As Long)
Dim Lo, Hi, z As Long
Dim Mid, T As Double
Lo = iLo
Hi = iHi
Mid = a((Lo + Hi) \ 2)
Do
While
(a(Lo) < Mid)
Lo
= Lo + 1
Wend
While
(a(Hi) > Mid)
Hi
= Hi - 1
Wend
If Lo
<= Hi Then
T =
a(Lo)
a(Lo) = a(Hi)
a(Hi) = T
z = p(Lo)
p(Lo) = p(Hi)
p(Hi) = z
z = v(Lo)
v(Lo) = v(Hi)
v(Hi) = z
Lo = Lo + 1
Hi = Hi - 1
End If
Loop
Until (Lo > Hi)
If Hi
> iLo Then
Call
QuickSort(a, iLo, Hi)
End If
If Lo
< iHi Then
Call
QuickSort(a, Lo, iHi)
End If
End Function
Public
Sub RandomData()
Dim
line As String
Dim i,
f As Long
f =
FreeFile
Open
InFileName For Output As #f
Randomize
For i =
0 To MaxSizeArray
'Write #f, Random(
Next i
Close
#f
End Sub
Public
Sub Zaino(p() As Long, v() As Long, ByVal c As Long, x() As Double)
Dim i As Long
Call
QuickSort(a, 0, MaxArray - 1)
For i =
0 To MaxArray - 1
x(i)
= 0
i = 1
While
(i <= MaxArray - 1) And (c >= 0)
If
v(i) >= c Then
'
try
If v(i) = 0 Then
'Showmessage(inttostr(i));
x(i) = c / v(i)
' except
'
showmessage('zero');
End If
c =
0
x(i)
= 1
c =
c - v(i)
End
If
i = i
+ 1
Wend
Next i
End Sub
10.2 DELPHI 3
GENERATORE CASUALE DI MATRICI QUADRATE POPOLATE CON TIPI DI DATO DOUBLE (VIRGOLA MOBILE)
Unit1;
interface
uses
Windows, Messages, SysUtils, Classes, Graphics, Controls, Forms,
Dialogs,
StdCtrls;
const
MaxSizeArray = 1000;
InFileName = 'c:\Tesi\Data\double.txt';
type
TForm1
= class(TForm)
Button1: TButton;
Edit1: TEdit;
Label1: TLabel;
procedure Button1Click(Sender: TObject);
private
{
Private declarations }
public
{
Public declarations }
end;
var
Form1:
TForm1;
implementation
{$R *.DFM}
procedure
TForm1.Button1Click(Sender: TObject);
var
i, j,
n: integer;
line:
string;
f:
TextFile;
begin
Randomize;
AssignFile(f, InFileName);
Rewrite(f);
Writeln(f, Edit1.Text);
n := StrToInt(Edit1.Text);
for i
:= 1 to n do
for j
:= 1 to n do
Writeln(f,
FloatToStr((Random(10)-Random(10))*(Random(1000)/(1+Random(100)))));
CloseFile(f);
end;
end.
QUICKSORT SU TIPO DI DATIO INTERO
unit uMain;
interface
uses
Windows,
Messages, SysUtils, Classes, Graphics, Controls, Forms, Dialogs,
StdCtrls;
const
MaxSizeArray = 500000;
InFileName =
'..\..\..\data\Interi.txt';
OutFileName =
'..\..\..\data\sortInteri.txt';
type
TfMain
= class(TForm)
Memo1: TMemo;
Button1: TButton;
eTempo: TEdit;
lTempo: TLabel;
Label1: TLabel;
procedure StartChrono;
procedure StopChrono;
procedure LoadFromFile(FileName: string);
procedure SaveToFile(FileName: string);
procedure ShowData(a: array of integer;
StringList: TStrings);
procedure QuickSort(var a: array of
Integer; iLo, iHi: Integer);
procedure FormCreate(Sender: TObject);
procedure Button1Click(Sender: TObject);
procedure RandomData(Sender: TObject);
private
{
Private declarations }
public
{
Public declarations }
end;
TBaseArray = array[0..MaxSizeArray] of Integer;
var
fMain:
TfMain;
BaseArray: TBaseArray;
MaxArray: integer;
tl0,
tl1, tlfreq: TLargeInteger;
implementation
{$R *.DFM}
procedure
TfMain.StartChrono;
begin
QueryPerformanceFrequency(tlfreq);
QueryPerformanceCounter(tl0);
eTempo.Clear;
end;
procedure
TfMain.StopChrono;
begin
QueryPerformanceCounter(tl1);
eTempo.Text := Format('Tempo = %10.5f
msec',[(tl1.QuadPart-tl0.QuadPart)/tlfreq.QuadPart*1000]);
end;
procedure
TfMain.LoadFromFile(FileName: string);
var
f:
TextFile;
line:
string;
begin
AssignFile(f, FileName);
Reset(f);
MaxArray := -1;
while
not eof(f) do
begin
Readln(f, line);
Inc(MaxArray);
BaseArray[MaxArray] := StrToInt(line);
end;
CloseFile(f);
end;
procedure
TfMain.SaveToFile(FileName: string);
var
f:
TextFile;
line:
string;
i:
integer;
begin
AssignFile(f, FileName);
Rewrite(f);
for i
:= 0 to MaxArray do
Writeln(f, IntToStr(BaseArray[i]));
CloseFile(f);
end;
procedure
TfMain.ShowData(a: array of integer; StringList: TStrings);
var
i:
integer;
begin
StringList.Clear;
for i
:= 0 to MaxArray do
StringList.Add(IntToStr(BaseArray[i]));
end;
procedure
TfMain.QuickSort(var a: array of Integer; iLo, iHi: Integer);
var
Lo, Hi, Mid, T: Integer;
begin
Lo := iLo;
Hi := iHi;
Mid := a[(Lo + Hi) div 2];
repeat
while
a[Lo] < Mid do Inc(Lo);
while
a[Hi] > Mid do Dec(Hi);
if Lo
<= Hi then
begin
T :=
a[Lo];
a[Lo] := a[Hi];
a[Hi] := T;
Inc(Lo);
Dec(Hi);
end;
until Lo > Hi;
if Hi
> iLo then QuickSort(a, iLo, Hi);
if Lo
< iHi then QuickSort(a, Lo, iHi);
end;
procedure
TfMain.FormCreate(Sender: TObject);
begin
LoadFromFile(InFileName);
end;
procedure
TfMain.Button1Click(Sender: TObject);
begin
StartChrono;
QuickSort(BaseArray, 0, MaxArray);
StopChrono;
SaveToFile(OutFileName);
end;
procedure
TfMain.RandomData(Sender: TObject);
var
f:
TextFile;
line:
string;
i:
integer;
begin
AssignFile(f, InFileName);
Rewrite(f);
Randomize;
for i
:= 0 to MaxSizeArray - 1 do
Writeln(f, IntToStr(Random(500000)));
CloseFile(f);
end;
end.
QUICKSORT SU TIPI DI DATO STRINGHE
unit uMain;
interface
uses
Windows,
Messages, SysUtils, Classes, Graphics, Controls, Forms, Dialogs,
StdCtrls;
const
MaxSizeArray = 10000000;
InFileName =
'..\..\..\data\Stringhe.txt';
OutFileName = '..\..\..\data\Stringhesort.txt';
type
TfMain
= class(TForm)
Memo1: TMemo;
Button1: TButton;
eTempo: TEdit;
lTempo: TLabel;
Label1: TLabel;
procedure StartChrono;
procedure StopChrono;
procedure LoadFromFile(FileName: string);
procedure SaveToFile(FileName: string);
procedure ShowData(a: array of String;
StringList: TStrings);
procedure QuickSort( var a: array of
String; iLo, iHi: Integer);
procedure FormCreate(Sender: TObject);
procedure Button1Click(Sender: TObject);
procedure RandomData(Sender: TObject);
private
{
Private declarations }
public
{
Public declarations }
end;
TBaseArray = array[0..MaxSizeArray] of String;
var
fMain:
TfMain;
BaseArray: TBaseArray;
MaxArray: integer;
tl0,
tl1, tlfreq: TLargeInteger;
implementation
{$R *.DFM}
procedure
TfMain.StartChrono;
begin
QueryPerformanceFrequency(tlfreq);
QueryPerformanceCounter(tl0);
eTempo.Clear;
end;
procedure
TfMain.StopChrono;
begin
QueryPerformanceCounter(tl1);
eTempo.Text := Format('Tempo = %10.5f msec',[(tl1.QuadPart-tl0.QuadPart)/tlfreq.QuadPart*1000]);
end;
procedure
TfMain.LoadFromFile(FileName: string);
var
f:
TextFile;
line:
string;
begin
AssignFile(f, FileName);
Reset(f);
MaxArray := -1;
while
not eof(f) do
begin
Readln(f, line);
Inc(MaxArray);
BaseArray[MaxArray] := line;
end;
CloseFile(f);
end;
procedure
TfMain.SaveToFile(FileName: string);
var
f:
TextFile;
line:
string;
i:
integer;
begin
AssignFile(f, FileName);
Rewrite(f);
for i
:= 0 to MaxArray do
Writeln(f, (BaseArray[i]));
CloseFile(f);
end;
procedure
TfMain.ShowData(a: array of string; StringList: TStrings);
var
i:
integer;
begin
StringList.Clear;
for i
:= 0 to MaxArray do
StringList.Add((BaseArray[i]));
end;
procedure
TfMain.QuickSort(var a: array of string; iLo, iHi: Integer);
var
Lo,
Hi:integer;
Mid, T:
string;
begin
Lo := iLo;
Hi := iHi;
Mid := a[(Lo + Hi) div 2];
repeat
while
a[Lo] < Mid do Inc(Lo);
while
a[Hi] > Mid do Dec(Hi);
if Lo
<= Hi then
begin
T
:= a[Lo];
a[Lo] := a[Hi];
a[Hi] := T;
Inc(Lo);
Dec(Hi);
end;
until Lo > Hi;
if Hi
> iLo then QuickSort(a, iLo, Hi);
if Lo
< iHi then QuickSort(a, Lo, iHi);
end;
procedure
TfMain.FormCreate(Sender: TObject);
begin
LoadFromFile(InFileName);
//ShowData(BaseArray, Memo1.Lines);
end;
procedure
TfMain.Button1Click(Sender: TObject);
begin
StartChrono;
QuickSort(BaseArray, 0, MaxArray);
StopChrono;
SaveToFile(OutFileName);
end;
QUICKSORT SU TIPO DI DATO IN VIRGOLA MOBILE
unit
uMain;
interface
uses
Windows, Messages, SysUtils, Classes,
Graphics, Controls, Forms, Dialogs,
StdCtrls;
const
MaxSizeArray = 500000;
InFileName
= '..\..\..\data\double.txt';
OutFileName =
'..\..\..\data\sortdouble.txt';
type
TfMain
= class(TForm)
Memo1: TMemo;
Button1: TButton;
eTempo: TEdit;
lTempo: TLabel;
Label1: TLabel;
procedure StartChrono;
procedure StopChrono;
procedure LoadFromFile(FileName: string);
procedure SaveToFile(FileName: string);
procedure ShowData(a: array of String; StringList: TStrings);
procedure QuickSort( var a: array of
double; iLo, iHi: Integer);
procedure FormCreate(Sender: TObject);
procedure Button1Click(Sender: TObject);
procedure RandomData(Sender: TObject);
private
{
Private declarations }
public
{
Public declarations }
end;
TBaseArray = array[0..MaxSizeArray] of Double;
var
fMain:
TfMain;
BaseArray: TBaseArray;
MaxArray: integer;
tl0,
tl1, tlfreq: TLargeInteger;
implementation
{$R *.DFM}
procedure
TfMain.StartChrono;
begin
QueryPerformanceFrequency(tlfreq);
QueryPerformanceCounter(tl0);
eTempo.Clear;
end;
procedure
TfMain.StopChrono;
begin
QueryPerformanceCounter(tl1);
eTempo.Text := Format('Tempo = %10.5f msec',[(tl1.QuadPart-tl0.QuadPart)/tlfreq.QuadPart*1000]);
end;
procedure
TfMain.LoadFromFile(FileName: string);
var
f:
TextFile;
line:
double;
begin
AssignFile(f, FileName);
Reset(f);
MaxArray := -1;
while
not eof(f) do
begin
Readln(f, line);
Inc(MaxArray);
BaseArray[MaxArray] :=line;
end;
CloseFile(f);
end;
procedure
TfMain.SaveToFile(FileName: string);
var
f:
TextFile;
line:
string;
i:
integer;
begin
AssignFile(f, FileName);
Rewrite(f);
for i
:= 0 to MaxArray do
Writeln(f, (BaseArray[i]));
CloseFile(f);
end;
procedure
TfMain.QuickSort(var a: array of double; iLo, iHi: Integer);
var
Lo,
Hi:integer;
Mid, T:
double;
begin
Lo := iLo;
Hi := iHi;
Mid := a[(Lo + Hi) div 2];
repeat
while
a[Lo] < Mid do Inc(Lo);
while
a[Hi] > Mid do Dec(Hi);
if Lo
<= Hi then
begin
T
:= a[Lo];
a[Lo] := a[Hi];
a[Hi] := T;
Inc(Lo);
Dec(Hi);
end;
until Lo > Hi;
if Hi
> iLo then QuickSort(a, iLo, Hi);
if Lo
< iHi then QuickSort(a, Lo, iHi);
end;
procedure
TfMain.FormCreate(Sender: TObject);
begin
LoadFromFile(InFileName);
end;
procedure
TfMain.Button1Click(Sender: TObject);
begin
StartChrono;
QuickSort(BaseArray, 0, MaxArray);
StopChrono;
SaveToFile(OutFileName);
end;
procedure
TfMain.RandomData(Sender: TObject);
var
f:
TextFile;
line:
string;
i:
integer;
begin
AssignFile(f, InFileName);
Rewrite(f);
Randomize;
for i
:= 0 to MaxSizeArray - 1 do
Writeln(f, IntToStr(Random(500000)));
CloseFile(f);
end;
end.
PRODOTTO DI MATRICI POPOLATE CON TIPI DI DATO DOUBLE
unit
Unit1;
interface
uses
Windows, Messages, SysUtils, Classes,
Graphics, Controls, Forms, Dialogs,
StdCtrls;
const
MaxSizeArray = 100;
InFileName
= 'c:\tesi\data\double.txt';
type
TForm1
= class(TForm)
Button1: TButton;
Edit1: TEdit;
Label1: TLabel;
Label2: TLabel;
procedure Button1Click(Sender: TObject);
procedure moltiplica;
procedure LoadFromFile(FileName: string);
procedure FormCreate(Sender: TObject);
procedure StopChrono;
procedure StartChrono;
private
{
Private declarations }
public
{
Public declarations }
end;
var
Form1:
TForm1;
MaxArray: integer;
a:
array[1..MaxSizeArray, 1..MaxSizeArray] of double;
b:
array[1..MaxSizeArray, 1..MaxSizeArray] of double;
c:
array[1..MaxSizeArray, 1..MaxSizeArray] of double;
tl0,
tl1, tlfreq: TLargeInteger;
implementation
{$R *.DFM}
procedure
TForm1.Button1Click(Sender: TObject);
var
i:integer;
begin
StartChrono;
moltiplica
;
StopChrono
;
Edit1.Text := Format('Tempo = %10.5f
msec',[(tl1.QuadPart-tl0.QuadPart)/tlfreq.QuadPart*1000]);
end;
procedure
tform1.moltiplica;
var i,j,k, times : integer;
begin
for i
:= 1 to MaxArray do
for j
:= 1 to MaxArray do
begin
c[i,
j] := 0;
for k
:= 1 to MaxArray do
c[i, j] := c[i, j] + a[i, k] * b[k, j];
end;
end;
procedure
TForm1.LoadFromFile(FileName: string);
var
f:
TextFile;
line:
string;
i, j:
integer;
begin
AssignFile(f, FileName);
Reset(f);
Readln(f, line); //La prima riga è la
dimensione della matrice
MaxArray :=
StrToInt(line);
for i
:= 1 to MaxArray do
for j
:= 1 to MaxArray do
begin
Readln(f, line);
a[i,
j] := StrToFloat(line);
b[i,j]:=a[i,j];
end;
CloseFile(f);
end;
procedure
TForm1.FormCreate(Sender: TObject);
begin
LoadFromFile (InFileName)
end;
procedure
Tform1.StartChrono;
begin
QueryPerformanceFrequency(tlfreq);
QueryPerformanceCounter(tl0);
edit1.Clear;
end;
procedure
Tform1.StopChrono;
begin
QueryPerformanceCounter(tl1);
edit1.Text := Format('Tempo = %10.5f
msec',[(tl1.QuadPart-tl0.QuadPart)/tlfreq.QuadPart*1000]);
end;
end.
TRIANGOLARIZZAZIONE E CALCOLO DEL DETERMINANTE DI MATRICI QUADRATE NXN POPOLATE CON TIPI DI DATO DOUBLE
unit
Unit1;
interface
uses
Windows, Messages, SysUtils, Classes,
Graphics, Controls, Forms, Dialogs,
StdCtrls;
const
MaxSizeArray = 1000;
InFileName = 'c:\Tesi\Data\double.txt';
type
TArray =
array[1..MaxSizeArray, 1..MaxSizeArray] of double;
TVector
= array[1..MaxSizeArray] of double;
TForm1
= class(TForm)
Button1: TButton;
Edit1: TEdit;
Edit2: TEdit;
Edit3: TEdit;
Label1: TLabel;
Label2: TLabel;
Label3: TLabel;
Label4: TLabel;
procedure
FormCreate(Sender: TObject);
procedure Button1Click(Sender: TObject);
procedure StopChrono;
procedure StartChrono;
procedure LoadFromFile(FileName: string);
private
{ Private declarations }
public
{
Public declarations }
end;
function Determinante(var a: TArray):double
;
procedure ludcmp(var a: TArray; var d:
integer; N: integer);
var
Form1:
TForm1;
BaseArray,a,b: TArray;
MaxArray, Segno: integer;
tl0,
tl1, tlfreq: TLargeInteger;
implementation
{$R *.DFM}
procedure
TForm1.FormCreate(Sender: TObject);
begin
LoadFromFile (InFileName)
end;
procedure
TForm1.Button1Click(Sender: TObject);
begin
StartChrono;
Determinante (a);
StopChrono ;
Edit1.Text := Format('Tempo = %10.5f
msec',[(tl1.QuadPart-tl0.QuadPart)/tlfreq.QuadPart*1000]);
end;
procedure
Tform1.StopChrono;
begin
QueryPerformanceCounter(tl1);
edit1.Text := Format('Tempo = %10.5f
msec',[(tl1.QuadPart-tl0.QuadPart)/tlfreq.QuadPart*1000]);
end;
procedure
Tform1.StartChrono;
begin
QueryPerformanceFrequency(tlfreq);
QueryPerformanceCounter(tl0);
edit1.Clear;
end;
procedure
TForm1.LoadFromFile(FileName: string);
var
f:
TextFile;
line:
string;
i, j:
integer;
begin
AssignFile(f, FileName);
Reset(f);
Readln(f, line);
MaxArray := StrToInt(line);
for i
:= 1 to MaxArray do
for j
:= 1 to MaxArray do
begin
Readln(f, line);
a[i,
j] := StrToFloat(line);
b[i,j]:=a[i,j];
end;
CloseFile(f);
end;
function
Determinante(var a: TArray):double;
var
d:
integer;
i:
integer;
begin
form1.StartChrono
;
ludcmp(a, d, MaxArray);
form1.StopChrono ;
form1.Edit2.Text := Format('Tempo = %10.5f
msec',[(tl1.QuadPart-tl0.QuadPart)/tlfreq.QuadPart*1000]);
Result
:= d;
for
i := 1 to MaxArray do
Result := Result * a[i, i];
form1.Edit3.Text:=floattostr(Result);
end;
procedure ludcmp(var a:
TArray; var d: integer; N: integer); Triangolarizzazione
var
I,
IMax, J, K: integer;
aamax,
dum, sum, tiny: double;
vv:
TVector;
begin
tiny :=
1E-20;
d := 1;
for I
:= 1 To N do
begin
aamax
:= 0;
for J
:= 1 To N do
begin
if
(Abs( a[I, J] ) > aamax) then
aamax := Abs(a[I, J]);
end;
if
(aamax = 0) then
begin
ShowMessage('Matrice singolare');
Exit;
end;
vv[I]
:= 1 / aamax;
end;
for J
:= 1 To N do
begin
for I
:= 1 To J - 1 do
begin
sum
:= a[I, J];
for K := 1 To I - 1 do
sum
:= sum - a[I, K] * a[K, J];
a[I, J] := sum ;
end;
aamax
:= 0;
for I := J To N do
begin
sum := a[I, J];
for K
:= 1 To J - 1 do
sum
:= sum - a[I, K] * a[K, J];
//Next K
a[I, J] := sum;
dum := vv[I] * Abs(sum);
if (dum >= aamax) Then
begin
IMax := I;
aamax := dum; // è il più
grande di vv(i)*abs(sum)'
end;
end; //Next I
if (J
<> IMax) then
begin
for
K := 1 To N do
begin
dum := a[IMax, K];
a[IMax, K] := a[J, K];
a[J,
K] := dum;
end; //Next K
d
:= -d;
vv[IMax] := vv[J]
end;
// End If
//Indx[J] := IMax;
if
(a[J, J] = 0) then
a[J, J] := tiny;
if (J
<> N) then
dum := 1 / a[J, J];
for I :=
Succ(J) to N do
a[I,
J] := a[I, J] * dum;
//Next
I
end;
end;
end.
ZAINO
unit uMain;
interface
uses
Windows, Messages, SysUtils, Classes, Graphics, Controls, Forms,
Dialogs,
StdCtrls;
const
MaxSizeArray = 100000;
InFileName =
'..\..\..\data\zaino.txt';
OutFileName = '..\..\..\data\xzaino.txt';
type
TBaseInteger = array[0..MaxSizeArray] of Integer;
TBaseDouble = array[0..MaxSizeArray] of double;
TfMain
= class(TForm)
Memo1: TMemo;
Button1:
TButton;
eTempo: TEdit;
lTempo: TLabel;
Label1: TLabel;
Button2: TButton;
Button3: TButton;
procedure StartChrono;
procedure StopChrono;
procedure LoadFromFile(FileName: string);
procedure SaveToFile(FileName: string);
procedure ShowData(a: array of integer;
StringList: TStrings);
procedure QuickSort(var a: array of double;
iLo, iHi: Integer);
procedure Zaino(var p, v: TBaseInteger; c:
integer; var x: TBaseDouble);
procedure Carica(Sender: TObject);
procedure Button1Click(Sender: TObject);
procedure RandomData(Sender: TObject);
private
{
Private declarations }
public
{
Public declarations }
end;
var
fMain:
TfMain;
p, v:
TBaseInteger;
x, a:
TBaseDouble;
c,
MaxArray: integer;
tl0,
tl1, tlfreq: TLargeInteger;
implementation
{$R *.DFM}
procedure
TfMain.StartChrono;
begin
QueryPerformanceFrequency(tlfreq);
QueryPerformanceCounter(tl0);
eTempo.Clear;
end;
procedure
TfMain.StopChrono;
begin
QueryPerformanceCounter(tl1);
eTempo.Text := Format('Tempo = %10.5f
msec',[(tl1.QuadPart-tl0.QuadPart)/tlfreq.QuadPart*1000]);
end;
procedure
TfMain.LoadFromFile(FileName: string);
var
f:
TextFile;
line:
string;
i:
integer;
begin
AssignFile(f, FileName);
Reset(f);
Readln(f, line);
MaxArray := StrToInt(line);
Readln(f, line);
c :=
StrToInt(line);
for i
:= 0 to MaxArray-1 do
begin
Readln(f, line);
p[i]
:= StrToInt(line);
Readln(f, line);
v[i]
:= StrToInt(line);
a[i]
:= p[i]/v[i];
end;
CloseFile(f);
end;
procedure
TfMain.SaveToFile(FileName: string);
var
f: TextFile;
i:
integer;
begin
AssignFile(f, FileName);
Rewrite(f);
for i
:= 0 to MaxArray-1 do
Writeln(f, floatToStr(x[i]));
CloseFile(f);
end;
procedure
TfMain.ShowData(a: array of integer; StringList: TStrings);
var
i:
integer;
begin
StringList.Clear;
for i
:= 0 to MaxArray-1 do
StringList.Add(FloatToStr(x[i]));
end;
procedure
TfMain.QuickSort(var a: array of double; iLo, iHi: Integer);
var
Lo, Hi, z: Integer;
Mid, T: double;
begin
Lo :=
iLo;
Hi :=
iHi;
Mid
:= a[(Lo + Hi) div 2];
repeat
while
a[Lo] < Mid do Inc(Lo);
while
a[Hi] > Mid do Dec(Hi);
if Lo
<= Hi then
begin
T
:= a[Lo];
a[Lo]
:= a[Hi];
a[Hi] := T;
z := p[Lo];
p[Lo] := p[Hi];
p[Hi] := z;
z := v[Lo];
v[Lo] := v[Hi];
v[Hi] := z;
Inc(Lo);
Dec(Hi);
end;
until
Lo > Hi;
if Hi
> iLo then QuickSort(a, iLo, Hi);
if Lo
< iHi then QuickSort(a, Lo, iHi);
end;
procedure
TfMain.Zaino(var p, v: TBaseInteger; c: integer; var x: TBaseDouble);
var
i:
integer;
begin
QuickSort(a, 0, MaxArray-1);
for i
:= 0 to MaxArray-1 do
x[i]
:= 0;
i := 1;
while
(i<=MaxArray-1) and (c>=0) do
begin
if
v[i] >= c then
begin
try
if
v[i]=0 then
Showmessage(inttostr(i));
x[i] := c / v[i];
except
showmessage('zero');
end;
c
:= 0;
end
else
begin
x[i] := 1;
c
:= c - v[i];
end;
Inc(i);
end;
end;
procedure
TfMain.Carica(Sender: TObject);
begin
LoadFromFile(InFileName);
//ShowData(BaseArray, Memo1.Lines);
end;
procedure
TfMain.Button1Click(Sender: TObject);
begin
StartChrono;
Zaino(p,
v, c, x);
StopChrono;
//
SaveToFile(OutFileName);
//
ShowData(BaseArray, Memo1.Lines);
end;
procedure
TfMain.RandomData(Sender: TObject);
var
f:
TextFile;
i:
integer;
begin
AssignFile(f, InFileName);
Rewrite(f);
Randomize;
Writeln(f, IntToStr(Random(100000)));
for i
:= 0 to MaxSizeArray - 1 do
begin
Writeln(f, IntToStr(1+Random(1000)));
Writeln(f, IntToStr(1+Random(1000)));
end;
CloseFile(f);
10.3 JAVA
ALGORITMO DI ORDINAMENTO QUICKSORT PER TIPO DI DATO INTEGER
import java.io.*;
import java.lang.*;
public class cputime {
static
int MaxArraySize = 50000000;
public
static String InFileName = "c:\\tesi\\data\\interi.txt";
public
static int MaxArray;
public
static long tl0, tl1, tFreq;
public
static int[] a = new int[MaxArraySize];
public static native long
jQueryPerformanceFrequency();
public static native long jQueryPerformanceCounter();
public static void StartChrono() {
tFreq
= jQueryPerformanceFrequency();
tl0 =
jQueryPerformanceCounter();
//System.currentTimeMillis();
}
public static void StopChrono() {
tl1 =
jQueryPerformanceCounter();
//System.currentTimeMillis();
System.out.println("Frequenza = "+tFreq);
System.out.println();
System.out.println("Elementi = "+MaxArray+"
interi");
System.out.println("Tempo 0 = "+tl0);
System.out.println("Tempo 1
= "+tl1);
System.out.println("Tempo = "+(1000*(tl1-tl0)/tFreq)+"
msec");
}
public static void LoadFromFile(String
FileName) throws IOException {
String
riga;
RandomAccessFile file = new RandomAccessFile(FileName, "r");
riga =
file.readLine();
riga =
riga.trim();
MaxArray = Integer.parseInt(riga);
int i;
for
(i=0; i<MaxArray; i++) {
riga
= file.readLine();
a[i]
= Integer.parseInt(riga.trim());
}
}
public static void SaveToFile(String
FileName) throws IOException {
RandomAccessFile file = new RandomAccessFile(FileName, "w");
for
(int i=0; i<=MaxArray; i++);
//file.writeLine(a[i]);
}
public static void ShowData() {
for
(int i=0; i<=MaxArray; i++)
System.out.println(i+" - "+a[i]);
}
public static void quicksort(int a[], int
iLo, int iHi) {
int
Mid, T, Lo, Hi;
Lo = iLo;
Hi = iHi;
Mid = a[(Lo + Hi) / 2];
do {
while (a[Lo] < Mid) Lo++;
while (a[Hi] > Mid) Hi--;
if
(Lo <= Hi) {
T = a[Lo];
a[Lo] = a[Hi];
a[Hi] = T;
Lo++;
Hi--;
}
} while (Lo <= Hi);
if (Hi > iLo) quicksort(a, iLo, Hi);
if (Lo < iHi) quicksort(a, Lo, iHi);
}
static
{
System.loadLibrary("cputime");
}
public static void main(String[] arg) throws
IOException {
LoadFromFile(InFileName);
StartChrono();
quicksort(a, 0, MaxArray);
StopChrono();
}
}
ALGORITMO DI ORDINAMENTO QUICKSORT PER TIPO DI DATO STRINGHE
import java.io.*;
import java.lang.*;
public class cputime {
static
int MaxArraySize = 10000;
public
static String InFileName = "c:\\tesi\\data\\stringhe.txt";
public
static int MaxArray;
public
static long tl0, tl1, tFreq;
public
static String[] a = new String[MaxArraySize];
public static native long jQueryPerformanceFrequency();
public static native long
jQueryPerformanceCounter();
public
static void StartChrono() {
tFreq
= jQueryPerformanceFrequency();
tl0 =
jQueryPerformanceCounter();
//tl0
= System.currentTimeMillis();
}
public static void StopChrono() {
tl1 =
jQueryPerformanceCounter();
// tl1 = System.currentTimeMillis();
System.out.println("Frequenza = "+tFreq);
System.out.println();
System.out.println("Elementi = "+MaxArray+"
stringhe");
System.out.println("Tempo 0 = "+tl0);
System.out.println("Tempo 1
= "+tl1);
System.out.println("Tempo = "+((1000*(tl1-tl0))/tFreq)+"
msec");
}
public static void LoadFromFile(String
FileName) throws IOException {
String
riga;
RandomAccessFile file = new RandomAccessFile(FileName, "r");
riga =
file.readLine();
riga =
riga.trim();
MaxArray = Integer.parseInt(riga);
int i;
for
(i=0; i<MaxArray; i++) {
riga
= file.readLine();
//riga = riga.trim();
//if
(riga.indexOf(',')>=0)
a[i]
= riga;
}
}
public static void SaveToFile(String
FileName) throws IOException {
RandomAccessFile file = new RandomAccessFile(FileName, "w");
for
(int i=0; i<=MaxArray; i++);
//file.writeLine(a[i]);
}
public static void ShowData() {
for (int i=0; i<=MaxArray; i++)
System.out.println(i+" - "+a[i]);
}
public static void quicksort(String a[], int
iLo, int iHi) {
int
Lo, Hi;
String Mid, T;
Lo
= iLo;
Hi = iHi;
Mid = a[(Lo + Hi) / 2];
do {
while (a[Lo].compareTo(Mid)<0) Lo++;
//a[Lo]<Mid
while (a[Hi].compareTo(Mid)>0)
Hi--; //a[Hi] > Mid
if
(Lo <= Hi) {
T
= a[Lo];
a[Lo] = a[Hi];
a[Hi] = T;
Lo++;
Hi--;
}
} while (Lo <= Hi);
if (Hi > iLo) quicksort(a, iLo, Hi);
if (Lo < iHi) quicksort(a, Lo, iHi);
}
static
{
System.loadLibrary("cputime");
}
public
static void main(String[] arg) throws IOException {
LoadFromFile(InFileName);
StartChrono();
quicksort(a, 0, MaxArray);
StopChrono();
ShowData();
}
}
ALGORITMO DI ORDINAMENTO QUICKSORT PER TIPO DI DATO INTEGER DOUBLE
import java.io.*;
import java.lang.*;
public class cputime {
static
int MaxArraySize = 1000000;
public
static String InFileName = "c:\\tesi\\data\\double.txt";
public
static int MaxArray;
public
static long tl0, tl1, tFreq;
public
static double[] a = new double[MaxArraySize];
public static native long
jQueryPerformanceFrequency();
public static native long
jQueryPerformanceCounter();
public static void StartChrono() {
tFreq
= jQueryPerformanceFrequency();
tl0 =
jQueryPerformanceCounter();
//tl0
= System.currentTimeMillis();
}
public static void StopChrono() {
tl1 =
jQueryPerformanceCounter();
// tl1 = System.currentTimeMillis();
System.out.println("Frequenza = "+tFreq);
System.out.println();
System.out.println("Elementi = "+MaxArray+"
double");
System.out.println("Tempo 0 = "+tl0);
System.out.println("Tempo 1
= "+tl1);
System.out.println("Tempo = "+((1000*(tl1-tl0))/tFreq)+"
msec");
}
public static void LoadFromFile(String
FileName) throws IOException {
String
riga;
RandomAccessFile file = new RandomAccessFile(FileName, "r");
riga =
file.readLine();
riga =
riga.trim();
MaxArray = Integer.parseInt(riga);
int i;
for
(i=0; i<MaxArray; i++) {
riga
= file.readLine();
//riga = riga.trim();
//if
(riga.indexOf(',')>=0)
riga
= riga.replace(',', '.');
a[i]
= Double.parseDouble(riga);
}
}
public static void SaveToFile(String
FileName) throws IOException {
RandomAccessFile file = new RandomAccessFile(FileName, "w");
for
(int i=0; i<=MaxArray; i++);
//file.writeLine(a[i]);
}
public static void ShowData() {
for
(int i=0; i<=MaxArray; i++)
System.out.println(i+" - "+a[i]);
}
public static void quicksort(double a[], int
iLo, int iHi) {
int Lo, Hi;
double
Mid, T;
Lo
= iLo;
Hi = iHi;
Mid = a[(Lo + Hi) / 2];
do {
while (a[Lo] < Mid) Lo++;
while (a[Hi] > Mid) Hi--;
if
(Lo <= Hi) {
T = a[Lo];
a[Lo] = a[Hi];
a[Hi] = T;
Lo++;
Hi--;
}
} while (Lo <= Hi);
if (Hi > iLo) quicksort(a, iLo, Hi);
if (Lo < iHi) quicksort(a, Lo, iHi);
}
static
{
System.loadLibrary("cputime");
}
public static void main(String[] arg) throws
IOException {
LoadFromFile(InFileName);
StartChrono();
quicksort(a, 0, MaxArray);
StopChrono();
//ShowData();
}
}
PRODOTTO TRA MATRICI NXN
import java.io.*;
import java.lang.*;
public class cputime {
static
int MaxArraySize = 100;
public
static String InFileName = "c:\\tesi\\data\\moltiplica.txt";
public static int MaxArray;
public
static long tl0, tl1, tFreq;
public
static double[][] a = new double[MaxArraySize][MaxArraySize];
public
static double[][] b = new double[MaxArraySize][MaxArraySize];
public
static double[][] c = new double[MaxArraySize][MaxArraySize];
public static native long
jQueryPerformanceFrequency();
public static native long
jQueryPerformanceCounter();
public static void StartChrono() {
tFreq
= jQueryPerformanceFrequency();
tl0 =
jQueryPerformanceCounter();
//tl0
= System.currentTimeMillis();
}
public static void StopChrono() {
tl1 =
jQueryPerformanceCounter();
// tl1 = System.currentTimeMillis();
System.out.println("Frequenza = "+tFreq);
System.out.println();
System.out.println("Array di "+MaxArray+" x
"+MaxArray+" double");
System.out.println("Tempo 0 = "+tl0);
System.out.println("Tempo 1
= "+tl1);
System.out.println("Tempo = "+((1000*(tl1-tl0))/tFreq)+"
msec");
}
public static void LoadFromFile(String
FileName) throws IOException {
String
riga;
double
tmp;
RandomAccessFile file = new RandomAccessFile(FileName, "r");
riga =
file.readLine();
riga =
riga.trim();
MaxArray = Integer.parseInt(riga);
for
(int i=0; i<MaxArray; i++)
for
(int j=0; j<MaxArray; j++) {
riga
= file.readLine();
riga
= riga.replace(',', '.');
tmp
= Double.parseDouble(riga);
a[i][j] = tmp;
b[i][j] = tmp;
}
}
public
static void SaveToFile(String FileName) throws IOException {
RandomAccessFile file = new RandomAccessFile(FileName, "w");
for
(int i=0; i<=MaxArray; i++);
//file.writeLine(a[i]);
}
public static void ShowData() {
for
(int i=0; i<=MaxArray; i++)
System.out.println(i+" - "+a[i]);
}
public static void moltiplica() {
int
i, j, k;
for
(i=0; i<MaxArray; i++)
for
(j=0; j<MaxArray; j++) {
c[i][j] = 0;
for
(k=0; k<MaxArray; k++)
c[i][j] = c[i][j] + a[i][k] * b[k][j];
}
}
static
{
System.loadLibrary("cputime");
}
public static void main(String[] arg) throws
IOException {
LoadFromFile(InFileName);
StartChrono();
moltiplica();
StopChrono();
//ShowData();
}
}
Bibliografia
Prentice-Hall[1976], Algoritms+Data
Structure=Program
Peter
Grogono[1983], Programmare in
Pascal
Niklaus
Wirth[1991], Algoritmi +Strutture dati=Programmi
Paolo
Serafini[giugno 2000], Ottimizzazione
Mondadori
informatica[1999], Manuale Ufficiale per Microsoft Visual Basic 6.0
John R.Hubbard[1999], Programming with Java
Vincenzo
Falzone[1982], Circuiti digitali integrati e
microprocessori
Marco
Cantu’[1999], Programmare con
Delphi 4
Cay
Horstman & Gary Cornel[1999], Java 2 i fondamenti
Alan
Bertossi [luglio 2000], Algoritmi
e strutture dati
Alfonso
Fuggetta, Carlo Ghezzi,
SandroMorasca, Angelo Morzenti,
Mauro Pezzè [1991], Ingegneria del Software
Ringraziamenti
Desidero
ringraziare chi a vario titolo ha
permesso la stesura di questa Tesi e il
contributo economico per il
conseguimento della stessa in particolare:
Prof. Livio Clemente Piccinini del
dipartimento di Ingegneria Civile dell'Università degli Studi di Udine.
Il
Sig. Paolo Sciarrini consulente Informatico della regione Autonoma Friuli
Venezia Giulia
Dedico
questo lavoro a tutta la mia Famiglia (incluso i scomparsi), a mia Sorella
Annateresa e la sua famiglia, in cui ho trovato serenità e aiuto.