Nella memoria del calcolatore ci sono sequenze di bit organizzate in bytes o multipli di bytes, organizzazione che deriva, di fatto, dalla capacità d’indirizzamento e trattamento dei dati delle istruzioni della macchina. Tuttavia le sequenze di bytes hanno un significato per il programma che li elabora ed un insieme di bytes può quindi contenere indifferentemente una stringa di caratteri secondo una determinata codifica, dei numeri o delle istruzioni di macchina.
Le istruzioni che spostano i bytes da una locazione di memoria ad un’altra, trattano questi come caratteri, le istruzioni aritmetiche trattano un certo numero di bytes consecutivi interpretandoli come numeri, se ad esempio in due bytes ci sono i caratteri ASCII. “0A”, in stampa si avrà “0A”, ma stampati come numero intero si otterrà 16688[1].
Non sempre i linguaggi di programmazione mantengono i tipi di dato nativi del processore, ma li utilizzano per creare i propri tipi di dato: un esempio significativo è quello della dimensione dei numeri nel COBOL stabilito in un massimo di 18 cifre decimali sia perché è una lunghezza sufficiente per le necessità del calcolo commerciale, sia perché nessuno dei calcolatori delle società partecipanti al progetto del compilatore prevedeva numeri ed istruzioni aritmetiche per queste dimensioni è ciò allo scopo di non dare a nessuno un indebito vantaggio.
I primi tipi di dato previsti da un linguaggio di programmazione, sono stati i numeri: numeri interi e floating point, singoli o inglobati in strutture multiple dette matrici, ciò perché i primi linguaggi di programmazione erano indirizzati al calcolo scientifico. I tipi di dato alfanumerici furono inizialmente un semplice "commento" ai numeri prodotti dal calcolo. I tipi di dati formati da caratteri o da aggregati di dati, anche di tipo diverso (record), comunque immagine diretta del contenuto dei supporti di memorizzazione, sono stati introdotti con i linguaggi indirizzati ad applicazioni commerciali. I dati di tipo carattere furono inizialmente di lunghezza fissa, con il PASCAL acquistano una certa variabilità, poiché la stringa è terminata dal carattere con valore binario zero. Con il BASIC si supera questa limitazione ottenendo una gran flessibilità nel trattamento delle stringhe, esse diventano un oggetto dotato dell’attributo lunghezza e con la possibilità di modificarne non solo il contenuto, ma anche la dimensione; da ciò discende la necessità che il linguaggio preveda un trattamento dinamico della memoria associata alle stringhe. Il FORTRAN introdusse il tipo di dato Booleano con due valori: Vero e Falso.
Un’altra struttura di dati variabile fu introdotta con il LISP, le liste; anche queste strutture presuppongono una gestione dinamica della memoria, e meccanismi di recupero di questa (garbage collection) quando essa è esaurita. In SNOBOL appaiono le matrici associative, sono un prodotto pressoché gratuito delle tecniche dei compilatori, in cui le variabili e le informazioni relative sono memorizzate in tabelle con accesso hash.
I numeri interi sono formati da 1, 2 o 4 byte consecutivi. Per i numeri segnati un bit è utilizzato per indicare il segno ed i restanti rappresentano il numero binario. Per il calcolo tecnico scientifico si utilizzano i numeri floating point che possono esprimere valori molto piccoli o molto alti: ±N*10±m dove N è detta Mantissa ed è un valore fra 1 e 9,999..., ed m è l’esponente di 10 ad esempio:
|
Numero |
Notazione in virgola mobile |
|
559876543290290000 |
5.5987654329029E+17 |
|
-0.00000000009876543 |
-9.876543E-11 |
In genere i numeri floating point utilizzano 4 bytes, in semplice precisione o 8 bytes in doppia precisione. Con i numeri in virgola mobile a semplice precisione si possono esprimere numeri negativi da -3,402823E38 a -1,401298E-45 e numeri positivi da 1,401298E-45 a 3,402823E38. Alcuni calcolatori (IBM 360/370) adottano una codifica dei numeri detta packed. Questi occupano da 1 ad 16 byte. Ogni carattere contiene due cifre numeriche codificate da 0000 a 1001 (da 0 a 9), l'ultimo byte a destra contiene il valore dell’unità ed il segno. Il segno è positivo se il semibyte contiene il valore (esadecimale) A, C, E o F, negativo se contiene B o D.
Fra i primi tipi di numero specificati dai linguaggi troviamo i numeri con decimali, il compilatore, che utilizza istruzioni aritmetiche su numeri interi, genera tali istruzioni tenendo conto del numero di decimali voluti, ad esempio se il campo IMPORTO, definito con tre decimali, contiene 320.1, nella memoria ci sarà il numero 320100, l’istruzione che somma 150 all’IMPORTO, in realtà sommerà 150000.
Altri linguaggi di programmazione prevedono tipi di dato con numero fisso di decimali (tipo di dato currency); al solito un bit determina il segno, un certo numero di bit determina il valore decimale ed i bit rimanenti individuano il valore intero.
In genere le date sono memorizzate in 8 bytes, 4 per la data, e 4 per l’ora. In Oracle® le date possono variare dal 1 gennaio 4712 AC al 31 Dicembre 4712 DC; in Visual Basic® dal 1 gennaio 100 al 31 dicembre 9999.
In alcuni linguaggi sono previsti i numeri razionali, cioè formati da dividendo e divisore; molti linguaggi moderni supportano il trattamento di numeri interi "illimitati".
E’ il tipo di dato per informazioni descrittive, ci si riferisce ad esso anche col nome di stringhe o dati alfanumerici.
Questi tipi di dato sono realizzati in modi diversi, il più semplice è un insieme contiguo di caratteri di lunghezza fissa. Nel linguaggio C le stringhe, pur essendo dichiarate di lunghezza fissa, sono terminate con il carattere con valore binario 0, ottenendo di fatto una limitata gestione di stringhe a lunghezza variabile. Nel linguaggio Basic le stringhe sono di lunghezza variabile, la loro struttura è formata da dei caratteri che contengono la lunghezza del dato, seguiti dal dato stesso (formato BSTR). Quando si varia la lunghezza di una stringa il programma colloca la stringa modificata in coda allo spazio dedicato alla loro memorizzazione. Se lo spazio è esaurito è attivato un meccanismo di recupero degli spazi.
Sono i tipi di dati detti variant, il linguaggio di programmazione ne determina il tipo in funzione dell'utilizzo che ne è fatto. Sono utilizzabili per stringhe, numeri e date.
Le matrici o array sono strutture contenenti occorrenze multiple di dati dello stesso tipo; la singola informazione è individuata dal nome della matrice e da uno o più indici che sono le coordinate della sua posizione nella matrice. Le matrici possono avere più dimensioni, quelle con una dimensione sono anche dette matrici lineari o vettori.
Un tipo particolare di matrici sono le matrici associative[2]. Nelle matrici associative ogni elemento è individuato da una chiave, che è il mezzo per accedere al suo valore.
Le tabelle sono simili alle matrici bidimensionali, ma le colonne possono contenere tipi di dato diversi. Se il linguaggio di programmazione non permette di dichiarare matrici non omogenee, occorre utilizzare matrici di stringhe di caratteri, ed effettuare la conversione dei dati dalla rappresentazione in formato carattere a quella voluta. Ad esempio una tabella con consumi mensili di acqua, luce e gas sarà formata da una matrice di stringhe di dimensioni 12 x 4, in cui la prima colonna contiene il nome del mese e le successive i consumi mensili.
Le liste sono delle strutture di dati proprie di molti linguaggi; nella loro
forma più generale sono una collezione di oggetti, ognuno dei quali è o un
oggetto elementare o una lista o un insieme vuoto. La definizione in termini di
generazione di linguaggio è:
Lista → {Testa, {Coda}}
I linguaggi che prevedono le liste hanno generalmente un insieme di
operazioni per inserire, modificare o cancellare elementi o parti di una lista,
e l'individuazione degli elementi per posizione. La possibilità di indicare la
testa e la coda di una lista, con la possibilità di verificare se essa è
vuota, di per se offrono lo strumento per utilizzare le liste in modo ricorsivo
(esempi in Haskell):
somma
[] = 0
somma (x:xs) = x + somma xs
Fra le funzioni su liste, sono particolarmente importanti le funzioni map, filter, foldr e foldl, in effetti sono dei sostituti eleganti delle istruzioni di loop:
|
Main>
map cubo [1..7]
-- applica la funzione cubo alla lista [1,8,27,64,125,216,343] Main> filter odd (map cub
[1..7]) –- filtra i cubi
dispari [1,27,125,343] Main> foldr (+) 0 ( filter odd (map cub [1..7])) 496
|
Con riferimento all’esempio, map genera una nuova lista applicando una funzione (cubo) ad ogni elemento della stessa, filter produce una lista con in soli elementi che soddisfano una condizione (odd) e foldr o foldl applicano una funzione binaria (+) fra un valore iniziale (0) e via via tutti gli elementi di una lista.
Gli elementi di una lista sono, omogenei, le collezioni di oggetti non omogenei sono dette tuple.
Le liste sono strutture flessibili ed adatte a rappresentare alberi, matrici, code, stack, e rappresentano un superamento della struttura lineare della memoria.
I record descrivono insiemi di dati contenenti dati elementari o no, anche di tipo diverso. Sono strutture introdotte nel COBOL, per descrivere il contenuto degli archivi. Nei linguaggi moderni sono presenti, sia come descrizione cui corrisponde un’area di memoria, sia come insiemi di nomi e attributi, ove gli attributi non necessariamente sono contenuti in aree di memoria contigue.
Le enumerazioni sono elenchi di dati, ad esempio {nord, est, sud, ovest} o i giorni della settimana.
I patterns o modelli sono una notazione per descrivere il contenuto di una
stringa di caratteri, al fine di estrarne o controllarne il contenuto. Ha
assunto varie codifiche nel corso del tempo, ma si sta affermando una
formulazione, che risale al linguaggio Perl, nota come espressioni regolari, in
quanto derivata dalla descrizione formale delle stringhe riconoscibili da automi
a stati finiti.
I linguaggi che prevedono gli insiemi di dati forniscono metodi per dichiararli e per operare su di essi.
Un semaforo è una struttura utilizzata per gestire delle risorse comuni a più processi. I semafori furono introdotti da Edsger W. Dijkstra . Nella forma più semplice il semaforo può assumere due stati gestiti da due metodi, l’uno per l’acquisizione della risorsa, l’altro per il rilascio di questa. Il metodo di acquisizione, se lo stato del semaforo è occupato, attende che questo diventi libero, se il semaforo è libero cambia lo stato in occupato e prosegue. Il metodo di rilascio della risorsa, pone semplicemente lo stato del semaforo a libero. Una variante di semaforo è il contatore di risorse: l’acquisizione della risorsa è possibile se il contatore è maggiore di zero, in questo caso il contatore è decrementato; il rilascio della risorsa consiste nell’incrementare il contatore di 1. La funzione del semaforo è quindi quella di “proteggere” il blocco di istruzioni compreso fra l’acquisizione ed il rilascio della risorsa.
Sono possibili varianti quali azioni alternative se la risorsa non è disponibile dopo un certo intervallo.
Nella notazione di Dijkstra acquisizione e rilascio sono indicati con P() e V(), in Python sono nomerisorsa.acquire() e nomerisorsa.release(), nell’assembler 370 ENQ nomerisorsa e DEQ nomerisorsa.
In taluni
linguaggi i semafori sono anche chiamati mutex.
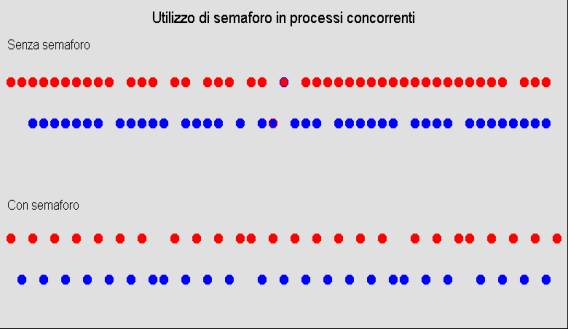
Nei linguaggi che prevedono i processi concorrenti (thread), i semafori sono facilmente con variabili globali, come si può vedere nell’esempio sottostante. La Figura 1‑3 evidenzia sia il comportamento nel caso di elaborazione senza semaforo, il cui effetto è di aggiornare in modo erroneo la risorsa contatore, sia il funzionamento con l’utilizzo del semaforo .
;
PureBasic - : Version 3.30 (c) 2001 - Fantaisie Software
;
------------------------------------------------------------
Global
contatore.w, NumThread, enq.w, delta.w ;
Procedure
PgmConcorrente(Param)
;
disegna cerchi
While contatore < 50
While enq = 0: Wend
; risorsa occupata
enq = enq - 1 ; blocco risorsa
buffer = contatore + 1
Colore = RGB(0,0,255)
If Param = 1
Colore = RGB(255,0,0)
EndIf
Delay(Random(50)) ; attende un tempo variabile
contatore = buffer
Circle(contatore*15,Delta+(50 * Param) ,6,Colore)
enq = enq + 1 ; sblocco risorsa
Delay(Random(50))
Wend
NumThread
= NumThread - 1
EndProcedure
Titolo.s
= "Utilizzo di semaforo in processi concorrenti"
If OpenWindow(0, 200, 100, 800, 600,
#PB_Window_SystemMenu, Titolo)
If
CreateImage(1, 780, 400)
If
StartDrawing(ImageOutput())
Box(0,0,779,399,RGB(224,224,224))
; sfondo grigio
LoadFont (0, "Arial", 14)
LoadFont (1, "Arial", 12)
DrawingMode(1) ; Trasparente
DrawingFont(UseFont(0))
FrontColor(0,0,0)
Locate((780-TextLength(Titolo))/2 , 10)
DrawText(Titolo)
DrawingFont(UseFont(1))
Locate(10, 45)
DrawText("Senza semaforo")
enq = 2 ; così non funziona come semaforo
Delta = 50 ;
Gosub StartProcessi
Locate(10, 240)
FrontColor(0,0,0)
DrawText("Con semaforo")
enq = 1 ; così funziona come semaforo
Delta = 240
Gosub StartProcessi
EndIf
StopDrawing()
EndIf
Repeat
EventID.l
= WaitWindowEvent()
If
EventID = #PB_EventRepaint
StartDrawing(WindowOutput())
DrawImage(ImageID(), 0, 100)
SaveImage(1,"thread.bmp")
StopDrawing()
EndIf
If
EventID = #PB_Event_CloseWindow
Quit = 1
EndIf
Until Quit =
1
EndIf
StartProcessi:
NumThread
= 2
contatore
= 0
thr1=CreateThread(@PgmConcorrente(), 1)
thr2=CreateThread(@PgmConcorrente(), 2)
While
NumThread > 0 : Wend; aspetto che finiscano
return
End
Ogni tipo di dato ha significato in quanto è correlato a come esso può
essere trattato, vale a dire alle
operazioni che sono possibili con esso: così due dati di tipo numerico possono
essere addizionati, da una stringa di caratteri se ne può estrarre una parte,
ecc….
Tipi di dato particolare, possono essere formati a partire da tipi di dato esistenti, e con l’associazione di particolari operazioni o metodi, ad esempio una data è formata dal tipo “insieme di 32 bit”, al quale sono associate dei metodi quali la trasformazione in data intelleggibile, la somma di giorni, la differenza fra date, ecc…
Gli oggetti sono strutture di dati con un’insieme di operazioni che possono essere fatte con questi o che possono essere attivate da particolari eventi (event driven). Nella terminologia degli oggetti le funzioni sono dette metodi, le informazioni proprietà, ed eventi le sollecitazioni a cui essi reagiscono.
Le proprietà di un Oggetto possono essere le più diverse e dipendono dal tipo di oggetto. Un oggetto grafico avrà dimensioni, posizionamento sul video, colore, bordi, sequenza di attivazione, visibilità, abilitazione, ecc... Le proprietà possono essere determinate al momento della preparazione dell'interfaccia utente, oppure variate dal programma.
Gli eventi sono le azioni dell'utilizzatore sull'oggetto, ad esempio la pressione del tasto del mouse. La "reazione" del programma all'evento è una porzione di programma, associata all'evento, che effettua qualche particolare azione.
I metodi sono delle azioni che l'oggetto compie se attivato da appositi comandi del programma. Alcuni metodi sono nativi, altri, quelli legati agli eventi, sono scritti dal programmatore.
La classe di un oggetto è la sua definizione, l'istanza dell'oggetto è l'oggetto utilizzato dal programma. Di un oggetto se ne possono creare più istanze. Inoltre in taluni linguaggi è possibile derivare proprietà metodi ed eventi da classi diverse. Gli oggetti possono ricevere messaggi dall’ambiente in cui sono presenti, il messaggio di fatto è l’invocazione di un metodo da parte del programma.[1]
Questo nei sistemi con microprocessore INTEL, in cui il byte con i valori più
significativi è a destra (little endian).
[2]
in alcuni linguaggi di programmazione sono chiamate dizionari
o array o map (SETL).