1.5 Creazione di linguaggi
La teoria dei compilatori è stata sviluppata insieme ai primi linguaggi di programmazione; è stata una nascita precoce perché i primi calcolatori furono utilizzati per scopi scientifici, anzi militari (la preparazione delle tavole di lancio dei cannoni), ed i primi programmatori erano persone con una solida preparazione matematica. Non è un caso che una forma di descrizione dei linguaggi di programmazione, la Backus-Naur Form o BNF utilizzata per specificare il linguaggio Algol, è opera del creatore del FORTRAN John Backus.
Una descrizione formale, cioè una grammatica del linguaggio, è un insieme di regole che possono essere interpretate da un programma per generare il compilatore o l'interprete del linguaggio stesso. Ad essere più precisi tramite le regole si genera un controllore sintattico; per ottenere poi il prodotto finale, occorre associare alle regole un contenuto operativo. Esistono dei programmi per generare, da una grammatica, un "riconoscitore" del linguaggio corrispondente alla grammatica; in genere l'operazione avviene tramite due sottoprogrammi distinti: uno per l'analisi lessicale (lexer) ed uno per l'analisi grammaticale (parser). L'analisi lessicale "estrae" le parole del linguaggio associandole ad una categoria predefinita: costante, nome di variabile, comando, ecc…; il parser successivamente riconosce se una sequenza di parole è una frase del linguaggio. I parser più noti sono Yacc (Yet Another Compiler to Compiler) e Bison, e i lexer Lex e Flex.
1.5.1 Yacc e Bison
Prima di analizzare la struttura di Bison[1], occorre accennare brevemente alle regole che descrivono una grammatica: come nella grammatica di un linguaggio naturale, le regole indicano che categoria di parole o componenti (lessico) e in quale ordine (sintassi) queste concorrono a formare le frasi. La struttura di una frase si può descrivere con un diagramma simile a quello della Figura 1.5:
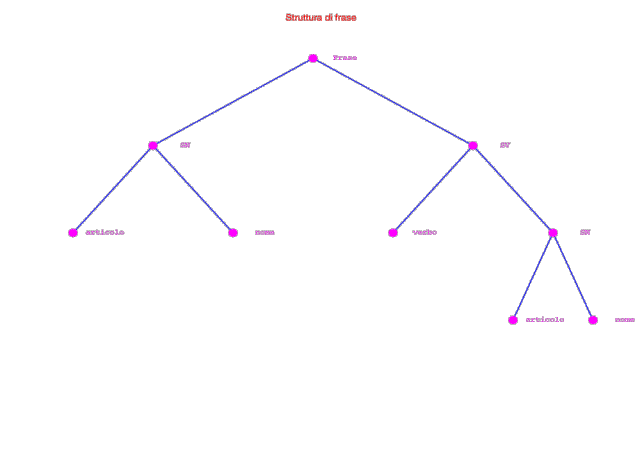
Figura 1-5
Le regole possono essere utilizzate per generare frasi corrette, o, come nel nostro caso, servono per verificare l'accettabilità di una frase. La struttura delle regole è del tutto analoga a quella della gran parte delle regole per la grammatica di un linguaggio naturale. A differenza di queste, le grammatiche dei linguaggi di programmazione sono più semplici e le regole non dipendono dal contesto, vale a dire, con una certa semplificazione, il tipo di una parola è sempre determinato, al contrario delle lingue naturali[2]. Una frase è quindi descritta in termini di componenti lessicali: parole e raggruppamenti di parole o sintagmi; quest'ultimi sono ancora descrivibili in termini di parole e sintagmi, fino ad arrivare ai costituenti ultimi della frase o simboli terminali. Nella Figura 1-5 le componenti lessicali di Frase sono sintagma nominale (SN) e sintagma verbale (SV) a loro volta definiti rispettivamente come Articolo - Nome e Verbo – SN.
Possiamo pensare, con un paradigma algebrico, che i simboli lessicali non terminali siano delle funzioni e che i simboli lessicali terminali siano valori che queste assumono. Così la funzione comando è definita come:
i)
comando: assegna |if
|while |dichiarazione |commento
dove il simbolo | indica l'alternativa. La funzione assegna è definita in molti linguaggi di programmazione, come:
ii)
assegna: VARIABILE = formula
In questa definizione compaiono gli elementi lessicali {VARIABILE, =} che sono valori e non più funzioni. Una descrizione (parziale) di formula potrebbe essere:
iii)
formula: (formula) |formula+formula
|formula*formula |formula/formula |... |VARIABILE |COSTANTE
Anche qui {VARIABILE, COSTANTE, (, )} sono elementi lessicali o valori, e formula è definita ricorsivamente per descrivere operazioni aritmetiche con parentesi. Così un'ipotetica istruzione:
area = (base * altezza)/2
è derivabile applicando le regole precedenti:
|
Regola |
espansione |
sostituzione |
|
comando: |
assegna |
assegna |
|
assegna: |
VARIABILE = formula |
area = formula |
|
formula: |
VARIABILE = formula/formula |
area = formula/formula |
|
formula: |
VARIABILE = (formula)/formula |
area = (formula)/formula |
|
formula: |
VARIABILE = (formula *
formula)/formula |
area = (formula *
formula)/formula |
|
formula: |
VARIABILE = (VARIABILE
* formula)/formula |
area = (base * formula)/formula |
|
formula: |
VARIABILE = (VARIABILE
* VARIABILE)/formula |
area = (base *
altezza)/formula |
|
formula: |
VARIABILE = (VARIABILE
* VARIABILE)/COSTANTE |
area = (base *
altezza)/2 |
L'ultima riga della colonna espansione contiene solo valori, questi
sono caratterizzati dal fatto che non hanno nessuna derivazione, sono quindi simboli
terminali, mentre le funzioni sono i simboli non terminali.
Bison utilizza la grammatica che gli è fornita sotto forma di regole espresse in forma analoga a quelle dell'esempio, per generare un sorgente in C che è l'analizzatore o parser del linguaggio. Tale sorgente deve essere compilato insieme con altri sorgenti:
§ il modulo main(), il cui compito principale è di richiamare la funzione di parser, cioè il sottoprogramma generato da Bison il cui nome è yyparse,
§ una procedura di gestione degli errori segnalati dal parser, il cui nome deve essere yyerror,
§ una funzione con nome yylex, che il parser utilizza, per ricevere uno per volta gli elementi costituenti il sorgente da compilare.
|
/* i tre moduli da utilizzare con il
sorgente generato da Bison */ main
() { yyparse (); } yyerror
(msg) { printf ("%s\n",msg); return(0); } yylex
() { ... return 0; /* fine sorgente */ ... return TIPO; /* TIPO = tipo dato */ } |
yylex deve riconoscere i vari componenti del sorgente (una costante, un numero, un'istruzione, ecc…), poiché ogni volta che è richiamata da Bison deve fornire questo dato con l'indicazione del tipo e il parser, in funzione delle informazioni che gli sono fornite, applica le regole opportune: se raggiunge una derivazione con soli simboli terminali, ritiene che l'espressione analizzata sia corretta; segnala invece un errore se, al punto in cui è arrivato nell'analisi, non trova nessuna regola che preveda il dato che ha ricevuto. Ad esempio con l'istruzione:
area 3 = (base * altezza)/2
Bison dopo VARIABILE riceve COSTANTE, che è una sequenza non presente in alcuna regola, quindi fallisce.
Nei casi più semplici la funzione yylex può essere scritta direttamente, ma può essere generata da programmi quali lex e flex sulla base di informazioni che descrivono come individuare gli elementi lessicali.
Quanto descritto corrisponde ad un puro e semplice
analizzatore, che termina segnalando la correttezza o meno del programma
parsificato. La generazione di un interprete o di un compilatore richiede
qualcosa in più, che va inserito insieme alla descrizione della grammatica,
sotto forma sostanzialmente di codice in linguaggio C, infatti il file con la
grammatica contiene quattro sezioni:
§
Dichiarazioni del linguaggio C: #include, macro,
costanti, variabili, funzioni, è una parte opzionale e va racchiusa fra %{
e %}. Se presente compare prima del codice del parser
generato da Bison.
§
Dichiarazioni di Bison: specificano simboli
terminali o non, precedenze, ecc…
§
Regole grammaticali. Sono compre fra due righe
contenenti la coppia di caratteri %%.
§
Codice addizionale in C. Se presente compare
dopo il codice del parser.
Le regole hanno la forma:
simbolononterminale: componenti;
dove componenti è un insieme di simboli terminali e non.
Inoltre è possibile assegnare ad ogni regola, del
codice in C, che è eseguito quando la regola è stata soddisfatta e che sostanzialmente
genera il programma finale:
tipidato: T_NUMBER ID
{save_vrb();printf("\nint
%s;",yytext);} ;
Quando la regola soprastante è verificata, Bison esegue la procedura save_vrb ed invia in output, supposto che ID corrisponda a base: int base;.
1.5.2 Lex
Lex è un programma che scompone un file in componenti sulla base di regole che ne descrivono il formato. Lex è utilizzato per lo più con Yacc o Bison, quindi le regole sono tali da individuare istruzioni, operatori, costanti, numeri, commenti, nomi di variabili, ecc… queste parti sono gli elementi lessicali del linguaggio.
Il file che Lex utilizza per scomporre e analizzare il sorgente, è formato da tre sezioni, separate dalla coppia di caratteri %%:
§ definizioni
§ regole
§ codice eventuale
Inoltre, ogni informazione che non inizi a colonna 1 o che sia racchiusa fra %{ e %{, è inviata in output, e quindi diventa parte del sorgente generato.
Nella sezione "definizioni" si possono associare dei nomi a delle sequenze di caratteri o espressioni regolari[3], (pattern) ciò rende non solo più leggibile il file di comandi, ma offre anche la possibilità di definire sequenze particolari come componenti di entità più complesse, ad esempio definendo:
SEGNO
[+|-]
DIGIT [0-9]
si possono definire gli elementi lessicali (la
parentesi quadra racchiude una raccolta di caratteri accettabili, il segno |
indica l'alternativa, il segno – indica un range di caratteri.):
INTERO {SEGNO}?{DIGIT}+
REALE
{SEGNO}?{DIGIT}+"."{DIGIT}*
FLOAT
({REALE}|{INTERO})[E|e]{INTERO}
Fra le parentesi graffe si indicano i nomi definiti; i caratteri ?, + e * si riferiscono all'espressione che li precede ed indicano:
§ ? l'espressione al più è presente una sola volta, infatti il segno può essere omesso,
§ + l'espressione può essere ripetuta e deve apparire almeno una volta,
§ * l'espressione può essere ripetuta anche nessuna volta.
Le regole, che compaiono nella sezione omonima, sono formate da una coppia {pattern azione}, dove pattern è o un nome predefinito, o un'espressione regolare o una sequenza di caratteri, ed azione un'insieme di istruzioni in linguaggio C. Le regole ed il codice ad esse associato, danno origine al modulo di nome yylex, che restituisce il tipo di dato ed il dato stesso nella variabile yytext.
1.5.3 Esempio di linguaggio interprete
L'esempio genera un programma interprete del linguaggio Brain*** (v. par.2.7). In pratica esso simula una macchina virtuale con della memoria dedicata al programma, della memoria di lavoro ed i registri che rispettivamente le indirizzano (PC e MP). Al primo richiamo della funzione yylex, questa memorizza il programma, inizializza la memoria ed i registri e ad ogni richiamo restituisce il codice istruzione presente all'indirizzo PC oppure 0 alla fine (v.Figura 1-6).
#include "brainf.tab.c"main(int argc, char** argv){ ARGV = argv; yyparse ();}yyerror (msg) { printf ("%s\n",msg); return(0); }yylex (){char opcode[] = "><+-,.[]";char c; if (lPgm == 0) { while ((c = getchar ()) != EOF) { /* carico il programma Brainf*** */ if (strchr(opcode,c) != NULL) BF_pgm[++lPgm] = c; } PC = 0; for (MP = 10; MP > 0;BF_mem[--MP] = 0); } PC = PC + 1; if (PC > lPgm) return 0; /* fine */ return BF_pgm[PC]; /* un'istruzione per l'interprete */} |
Figura 1-6
Le informazioni per generare il parsificatore sono:
|
%{ #define YYSTYPE double #define YYERROR_VERBOSE #include <math.h> int BF_mem[1000]; // memoria per Brainf*** char BF_pgm[1000]; // memoria
per il programma Brainf*** int PC; // Programm Counter di Brainf*** int MP; // Memory Pointer di Brainf*** int input = 0; // conta input argv char **ARGV; // parametri in riga di comando int lPgm = 0; // lunghezza programma %} /* Regole della Grammatica ed azioni */ %% exp: com | exp com ; com: '>' { MP++;} | '<' { MP--;} | '+' { BF_mem[MP]++;} | '-' { BF_mem[MP]--;} | ',' { BF_mem[MP] = atoi(ARGV[++input]);
printf("\nInput: %d",BF_mem[MP]);} | '.' { printf("\nOutput:
%d",BF_mem[MP]);} | '[' { if (BF_mem[MP] == 0) { int j; j=1; //
per match parentesi while (++PC
<= lPgm) { if
(BF_pgm[PC] == 93 && --j == 0) break; // trovato ] if (BF_pgm[PC]
== 91) j++; // trovato
[ } if (PC >
lPgm) {printf("non trovata ]");} } } | ']' { if (BF_mem[MP] != 0) { int j; j=1; //
per match parentesi while (--PC
> 0) { if
(BF_pgm[PC] == 91 && --j == 0) break; // trovato [ if
(BF_pgm[PC] == 93) j++;
// trovato ] } if (PC == 0)
{printf("non trovata [");} } } ; %% |
Figura 1-7
I simboli terminali sono i codici d'istruzione di Brainf***, il codice in linguaggio C ad essi associato è la simulazione in C delle istruzioni Brainf***.
La compilazione del sorgente della Figura 1-6, in cui è incluso il sorgente del parser generato da Bison (brainf.tab.c), produce l'interprete di Brianf***. Ad esempio il programma Brainf*** ,[>+++<-]>. calcola outupt = input * 3:
D:\fsf\Bison> brainf 3
< brainf.src
Input: 3
Output: 9
Il significato delle istruzioni è:
§ , leggi input
§ [ se 0 vai all'istruzione successiva a ]
§ > spostati sulla memoria successiva
§ +++ somma 1 (per tre volte)
§ < spostati sulla memoria precedente
§ - sottrai 1
§ ] se diverso da zero vai all'istruzione successiva a [
§ > spostati sulla memoria successiva
§ . stampa il risultato
1.5.4 Esempio di compilatore
L'esempio è relativo ad un compilatore di un abbozzo di linguaggio, di cui vi è in Figura 1-8 un frammento che calcola la radice quadrata di un numero intero, anche negativo. La realizzazione di un compilatore è del tutto analoga, a quella qui descritta, anche se molto più complessa. Rispetto ad un linguaggio "completo" l'esempio è rudimentale per l'incompletezza dei comandi, la povertà dei tipi di dato che esso accetta, e per la mancanza di funzioni di controllo.
|
Programma da compilare |
Sorgente in C del programma |
|
|
number sqr number
var string
unit move
arg to var move ' ' to unit --
verifico segno if
var < 0 move 'i' to unit -- unita immaginaria move abs var to var end move
square var to sqr print 'Radice di ' var ' = ' sqr unit--- compilazione e prova ---
|
#include "math.h" main(int argc, char **argv) { int arg = atoi(argv[1]); char stringa[] = " "; int
sqr; int
var; char unit;
var = arg;
unit = ' ';
/* verifico segno */
if (var < 0) {
unit = 'i';
/* unita immaginaria */
var = (var > 0 ? var:-var);
}
sqr = pow(var+0.1,0.5);
printf("Radice di ");
printf("%d",var);
printf(" = ");
printf("%d",sqr);
stringa[0] = unit;
printf(stringa);
printf("\n"); } |
Per realizzare il compilatore è necessario predisporre un modulo principale il cui scopo è di includere l'analizzatore lessicale generato da Flex ed il parsificatore generato da Yacc o Bison, nell'esempio #include "lexyy.c" e #include "prova.tab.c"; di richiamare il programma parsificatore ed eventualmente produrre le istruzioni iniziali e finali per il sorgente generato, nell'esempio la dichiarazione della routine main, la dichiarazione della variabile arg che contiene il numero passato sulla riga di comando, l'inclusione della libreria matematica math.h, ecc….
L'elaborazione principale avviene fra il parsificatore e l'analizzatore lessicale: il parsificatore richiama l'analizzatore e questi gli fornisce il dato proveniente dal sorgente da compilare ed il relativo tipo (i nomi simbolici dei tipi sono nel file generato da Bison "prova.tab.h", che deve essere incluso nell'analizzatore lessicale). Il parsificatore verifica che il tipo di dato sia coerente con la derivazione attuale; se la derivazione col nuovo dato è finale, cioè senza simboli non terminali, il parsificatore esegue le eventuali istruzioni collegate, che in genere producono il frammento di codice in linguaggio C corrispondente all'istruzione in esame. Alla fine si ottiene un codice sorgente che compilato esegue il programma (v.Figura 1-8).
|
#include
"lexyy.c" #include
"prova.tab.c" main(
argc, argv ) int
argc; char
**argv; { ++argv, --argc; /* skip over program name */ if ( argc > 0 ) yyin = fopen( argv[0],
"r" ); else yyin = stdin; // scrittura parte iniziale printf("#include
\"math.h\""); printf("\nmain(int argc, char
**argv) {"); printf("\nint arg =
atoi(argv[1]);"); printf("\nchar stringa[] = \"
\";"); yyparse (); printf("\n}"); // scrittura
parte finale } yyerror
(msg) { printf("\ntrovato: %s
\n",yytext); printf ("%s\n",msg); return(0); } |
Nella Figura
1-9 è riportato il modulo principale con la produzione delle istruzioni
iniziali, il richiamo del parsificatore yyparse ();, la
chiusura del sorgente generato e la semplice gestione degli errori rilevati dal
parsificatore: la funzione yyerror (msg). Nella sottostante Figura
1-10, è contenuto il sorgente per l'analizzatore lessicale.
/* flex.exe version 2.5.4 */
%{ #include "prova.tab.h" /* definizioni generate da Bison */ char vrb[255] = ""; // memorizza tipo e variabili dichiarate char op1[255]; // memorizza I operando char cmt[255]; // memorizza commento int
sw = -1; // memorizza
alternativamente op1 e op2 int
cmd; // memorizza il
comando int
tipo; // tipo dato char oper[2]; // operatore di confronto char indent[255] = " "; // indentazione save_op() { if (yytext[0] == '\x27' && strlen(yytext) > 3) { //
cambia ' in "
yytext[0] = '\"';
yytext[strlen(yytext)-1] = '\"'; } sw = -sw; if (sw > 0) strcpy(op1,yytext); } save_vrb() {
int i = strlen(vrb);
vrb[i] = tipo-256;
vrb[i+1] = '\0';
sprintf(vrb,"%s%s.",vrb,yytext); } %} %option noyywrap T_NUMBER number T_STRING string MOVE move TO to IF if END end ABS abs SQUARE square PRINT print DIGIT [0-9] ID [a-z][a-z0-9]* COSTANT '[^']*'
CR [\n] COMMENT --.* %% {ABS} cmd = ABS;return ABS; {SQUARE} cmd = SQUARE;return SQUARE; {T_NUMBER} tipo = T_NUMBER;return T_NUMBER; {T_STRING} tipo = T_STRING;return T_STRING; {TO} return TO; {IF} cmd = IF;sw = -1;return IF; {END} return END; {MOVE} cmd = MOVE;sw = -1;return MOVE; {PRINT} cmd = PRINT;return PRINT; {ID} save_op();return ID; {DIGIT}+ save_op();return DIGIT; {COMMENT} strcpy(cmt,yytext+2);return COMMENT; {COSTANT} save_op();return COSTANT; "<"|"<"|"="|"!="
strcpy(oper,yytext);return OPERAT; {CR} /*return CR;*/ [ \t]+ /* via spazi e tab*/ . printf( "Simbolo sconosciuto: %s\n", yytext
); %% |
La Figura 1-11 contiene le informazioni
per produrre il parsificatore.
/* GNU Bison version 1.28 */
%{ #include <math.h> #include <stdio.h> #include <string.h> #define YYERROR_VERBOSE #define YYDEBUG 1 wsource() {
int i;
char *sub_text;
char prepvar[255] = "";
// area per operando print
switch (cmd)
{ case MOVE:
{printf ("\n%s%s = %s; ",indent,yytext,op1); break;}
case SQUARE:
{sprintf(op1,"pow(%s+0.1,0.5)",yytext);
cmd = MOVE;
break;}
case ABS:
{sprintf(op1,"(%s > 0 ? %s:-%s)",yytext,yytext,yytext);
cmd = MOVE;
break;}
case PRINT:
{sprintf(prepvar,"%s.",yytext);
sub_text = strstr(vrb,prepvar);
strcpy(prepvar,yytext);
if (sub_text != NULL)
{ i = vrb[sub_text - vrb - 1] + 256; // estraggo TIPO if (i == T_NUMBER)
sprintf(prepvar,"\"%s\",%s","%d",yytext); else { printf ("\n%sstringa[0] =
%s;",indent,yytext); strcpy(prepvar,"stringa"); }
}
printf ("\n%sprintf(%s);",indent,prepvar);
break;}
case IF:
{printf ("\n%sif (%s %s %s) { ",indent,op1,oper,yytext);
strcat(indent," ");
break;}
} } %} %token MOVE PRINT IF END %token TO ID COSTANT COMMENT DIGIT CR %token OPERAT T_NUMBER T_STRING %token ABS SQUARE %% /* Regole */ lines: lines
line | /* empty */ ; line: cmd | commento ; cmd: MOVE exp TO ID
{wsource();} | IF exp OPERAT exp {wsource();} | END {indent[strlen(indent)-2] =
0;printf("\n%s}",indent);} | PRINT edit
{printf("\n%sprintf(\"\\n\");",indent);} | tipidato ; edit: edit ID
{wsource();} | edit COSTANT
{wsource();} | ID {wsource();} | COSTANT
{wsource();} ; exp: DIGIT | ID
| COSTANT
| SQUARE exp
{wsource();} | ABS exp
{wsource();} ; tipidato: T_NUMBER ID {save_vrb();printf("\nint %s;",yytext);} | T_STRING ID
{save_vrb();printf("\nchar %s;",yytext);} ; commento: COMMENT {printf("\n%s/* %s
*/",indent,cmt);} ; %% |
1.5.5
Oltre gli
strumenti standard
Da quanto visto nei paragrafi precedenti, gli analizzatori lessicale e
grammaticale rappresentano un utile strumento per lo sviluppo di un linguaggio,
ma la gran parte del lavoro è a carico del progettista. Si devono definire
scelte di architettura quali i tipi di
dato accettati, le operazioni su di essi; scegliere se adottare una
dichiarazione implicita piuttosto che esplicita delle variabili, se il tipo di
dato deve essere dichiarato o se il tipo è determinato dal suo utilizzo. In
termini di funzioni occorre prevedere l'estensibilità del linguaggio; l'accesso
a servizi esterni; il controlli di validità sulle variabili; gli strumenti per
la messa a punto dei programmi, ecc….
Un altro importante aspetto è l'efficienza del
codice prodotto, efficienza che si ottiene non solo con un codice ottimizzato,
ma anche tramite un'analisi semantica delle frasi, ad esempio
l'istruzione:
if a^2 + b < 3.1415 or a
> 0 then ...
può essere tradotta considerandola come:
if a > 0 or a^2 + b <
3.1415 then ...
in cui la determinazione della verità dell'
istruzione condizionale, è potenzialmente più veloce.
Un esempio un po' più complesso è il seguente
frammento in BASIC:
Intgr
= 0
passo
= 0.001
For i
= 0 To 3 Step passo
Intgr = Intgr + passo * i ^ 2 + passo * 3
Next
Print Intgr
che calcola l'integrale definito: ![]() mediante sommatorie
successive. Un'ottimizzatore porterebbe fuori dal ciclo For passo * 3 poiché il calcolo non
dipende dal ciclo:
mediante sommatorie
successive. Un'ottimizzatore porterebbe fuori dal ciclo For passo * 3 poiché il calcolo non
dipende dal ciclo:
Intgr
= 0
passo
= 0.001
Var =
passo * 3
For i
= 0 To 3 Step passo
Intgr = Intgr + passo * i ^ 2 + Var
Next
Print Intgr ' Si ottiene
18,0075 invece del valore esatto 18
Infine si può pensare ad un'analisi euristica del programma: in base
al comportamento nel passato, le istruzioni si modificano, riferendoci al primo
esempo di analisi semantica, se la variabile a è per
lo più negativa conviene effettuare prima il test a^2 + b < 3.1415.